Author: Denis Avetisyan
New research introduces a system that significantly improves the accuracy of AI-powered scientific question answering by focusing on the most relevant evidence.
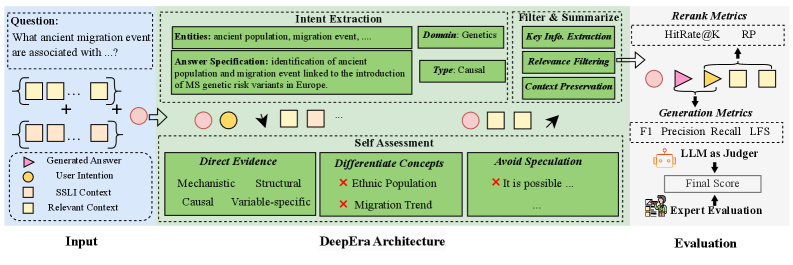
DeepEra employs an agentic reranking approach to prioritize logically relevant passages for Retrieval-Augmented Generation, enhancing the reliability of answers from scientific literature.
Despite advances in Retrieval-Augmented Generation (RAG) for scientific question answering, current systems remain vulnerable to irrelevant, yet semantically similar, passages that undermine factual accuracy. To address this, we present ‘DeepEra: A Deep Evidence Reranking Agent for Scientific Retrieval-Augmented Generated Question Answering’, introducing a novel agentic reranker that prioritizes logically relevant evidence, enhancing the reliability of RAG systems and validating this approach with the new SciRAG-SSLI dataset. Our evaluations demonstrate superior retrieval performance compared to existing rerankers, highlighting the critical need to address subtle logical inconsistencies in scientific text. Can this approach pave the way for more trustworthy and robust scientific knowledge discovery using large language models?
The Ever-Expanding Archive: A Challenge to Knowledge Synthesis
The relentless growth of scientific literature presents a formidable obstacle to efficient knowledge discovery. While advancements in data generation consistently outpace humanity’s capacity to synthesize that information, the need for accurate and rapid answers to complex questions intensifies. This challenge isn’t merely one of scale; the inherent complexity of scientific concepts, nuanced language, and the interconnectedness of research fields demand more than simple data retrieval. Effectively querying this vast corpus requires systems capable of discerning subtle relationships, understanding context, and identifying genuinely relevant information-a task far exceeding the capabilities of traditional keyword-based approaches. Consequently, accelerating scientific progress hinges on overcoming this bottleneck and enabling researchers to efficiently extract actionable insights from an ever-expanding sea of data.
Current approaches to scientific question answering frequently falter when confronted with the sheer scale of available research. Many systems depend heavily on keyword matching – a technique that identifies documents containing specific terms, but fails to grasp the underlying meaning of those terms within the scientific context. This reliance on lexical similarity often leads to the retrieval of irrelevant papers, or misses crucial information expressed using different terminology but addressing the same concept. Consequently, researchers are left sifting through numerous results, a time-consuming process that hinders, rather than facilitates, knowledge discovery. The limitation underscores a critical need for systems capable of semantic understanding, allowing them to discern the true relevance of information beyond superficial word overlap and accurately synthesize evidence from the expanding body of scientific literature.
Advancing scientific discovery hinges on the development of systems that move beyond simple information retrieval to achieve genuine comprehension of complex research. Current methods often falter when faced with the subtleties of scientific language and the need to synthesize evidence from multiple sources; a robust system must therefore be capable of discerning not just keywords, but the meaning behind them, and critically evaluating the strength of supporting evidence. Such a capability would dramatically accelerate the pace of research by enabling scientists to quickly and accurately identify relevant findings, validate hypotheses, and build upon existing knowledge, ultimately fostering innovation and addressing critical challenges across diverse fields of study. The capacity for nuanced understanding and reliable evidence-based answers is no longer a desirable feature, but a fundamental requirement for maintaining momentum in the ever-expanding landscape of scientific literature.
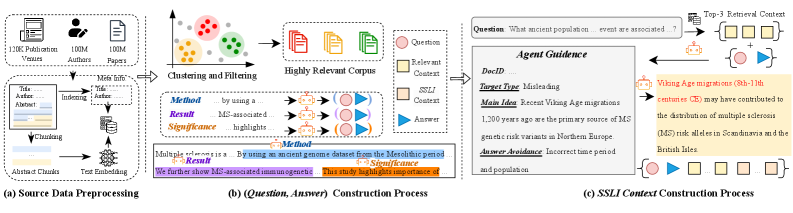
Augmenting Knowledge: The Promise of Contextualization
Retrieval-Augmented Generation (RAG) functions by integrating pre-trained Large Language Models (LLMs) – which excel at language understanding and generation but are limited by their training data – with external knowledge sources. These sources, such as vector databases, document repositories, or APIs, provide the LLM with access to information beyond its initial training. By retrieving relevant data from these sources prior to response generation, RAG systems effectively augment the LLM’s knowledge, enabling it to formulate answers grounded in current and specific information, and improving both factual accuracy and the relevance of the output. This combination leverages the LLM’s generative capabilities with the reliability of verifiable, external data.
Retrieval-augmented generation (RAG) systems operate in a two-stage process. Initially, a user query is processed to identify and retrieve pertinent documents from a pre-defined knowledge base, which can consist of various data formats including text files, databases, and web pages. This retrieval is typically performed using semantic search or keyword matching techniques. Subsequently, the retrieved documents, along with the original user query, are provided as context to a large language model (LLM). The LLM then synthesizes the information from these documents to generate a response, effectively grounding the answer in external, verifiable data and allowing for more informed and accurate outputs.
Large Language Models (LLMs), while powerful, are constrained by the data they were initially trained on, leading to potential inaccuracies or outdated information. Retrieval-Augmented Generation (RAG) addresses this limitation by supplementing the LLM’s internal knowledge with data retrieved from external sources at the time of query. This process ensures responses are based on current and verifiable evidence, reducing the risk of generating hallucinations or perpetuating obsolete facts. Specifically, RAG systems dynamically incorporate relevant documents into the prompt, effectively providing the LLM with contextual information that extends beyond its pre-training data and allows for responses grounded in reliable, external knowledge bases.
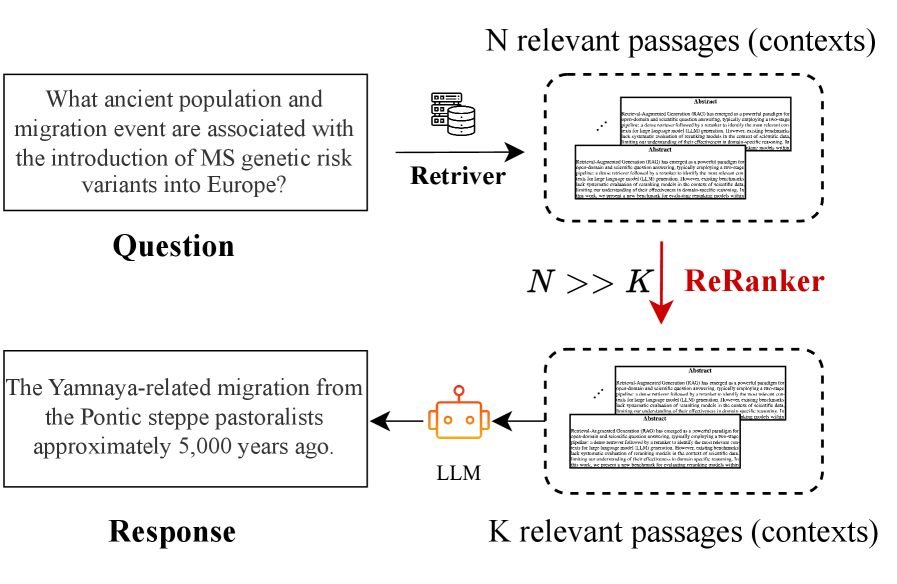
DeepEra: Refining the Search for Truth
DeepEra is an agentic reranker intended to enhance the performance of Retrieval-Augmented Generation (RAG) systems specifically for scientific question answering. Unlike traditional rerankers that rely on lexical matching, DeepEra employs Large Language Models (LLMs) as agents to actively assess and refine the initial set of retrieved passages. This agentic approach allows DeepEra to move beyond surface-level keyword comparisons and instead focus on semantic relevance, logical coherence, and the factual basis of the content, thereby increasing the precision and reliability of the information presented to the LLM for answer generation. The system is designed to improve robustness against noisy or irrelevant information commonly found in large scientific datasets.
DeepEra evaluates candidate passages using Large Language Models (LLMs) to move beyond traditional keyword-based retrieval. This assessment encompasses three primary criteria: semantic relevance, determining how closely the passage’s meaning aligns with the query; logical consistency, verifying the internal coherence and absence of contradictions within the passage; and evidential grounding, which confirms that claims made within the passage are supported by the provided text. By analyzing passages based on these factors, DeepEra aims to identify information that is not merely lexically similar to the query, but genuinely addresses the underlying intent and is factually substantiated, improving the quality of information delivered by Retrieval-Augmented Generation (RAG) systems.
DeepEra’s architecture centers on three primary components: Intention Recognition, Evidence Filtering, and Evidence Summarization. Intention Recognition analyzes the input query to discern subtle contextual cues and user intent beyond surface-level keywords. Evidence Filtering then rigorously evaluates retrieved passages, eliminating content deemed irrelevant or lacking supporting evidence for the query. Remaining passages undergo Evidence Summarization, a process which condenses the information into a concise and focused form suitable for answer generation. Benchmarking demonstrates that this combined approach yields up to an 8% relative improvement in both retrieval robustness – the consistency of relevant results across variations in query phrasing – and overall answer accuracy on scientific question answering tasks.

SciRAG-SSLI: A Rigorous Test of Comprehension
The SciRAG-SSLI dataset distinguishes itself as a rigorous benchmark by moving beyond simple retrieval tasks and introducing a level of complexity mirroring real-world scientific information seeking. It accomplishes this through a unique construction: alongside genuinely relevant passages sourced from scientific literature, the dataset incorporates deliberately misleading ‘distractor’ passages generated by large language models. This dual approach-combining authentic data with intelligently crafted misinformation-forces reranking models to not only identify pertinent information but also to discern it from plausible yet incorrect alternatives. Such a challenge is crucial for evaluating a system’s capacity for nuanced understanding and critical assessment, pushing the boundaries of performance beyond superficial keyword matching and demanding a deeper comprehension of scientific context.
The SciRAG-SSLI dataset represents a novel approach to evaluating information retrieval systems, moving beyond simplistic benchmarks to mirror the complexities of scientific research. Unlike traditional datasets relying solely on existing documents, SciRAG-SSLI incorporates both authentic scientific passages and deliberately crafted, LLM-generated distractors – plausible but incorrect information designed to challenge reranking algorithms. This nuanced construction forces models to demonstrate a deeper understanding of semantic relevance, rather than simply identifying keyword matches. By presenting a significantly more difficult evaluation scenario, the dataset effectively pushes the limits of current state-of-the-art models, revealing their true capabilities and highlighting areas for improvement in scientific document retrieval and knowledge synthesis.
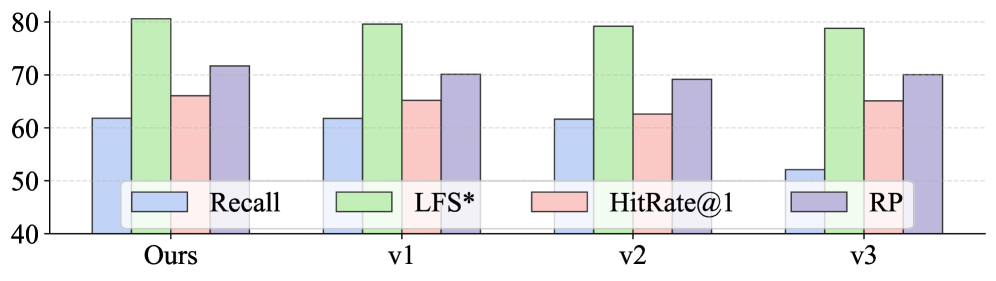
Evaluations using the challenging SSLI subset of the SciRAG-SSLI dataset reveal DeepEra’s substantial advancements in scientific document retrieval. The model attains a HitRate@1 of 66.6, indicating that the correct answer appears as the top result in over two-thirds of queries, and extends this performance with a HitRate@3 of 76.4. Further metrics demonstrate DeepEra’s nuanced understanding; it achieves a Relative Position (RP) score of 71.96, signifying its ability to rank relevant documents higher than irrelevant ones, alongside an F1 Score of 43.38, reflecting a strong balance between precision and recall. Critically, an LLM Score of 3.94 – assessed through large language model evaluation – confirms the semantic relevance and quality of DeepEra’s retrieved passages, collectively showcasing a marked improvement over existing methods in complex scientific information retrieval tasks.
Towards an Intelligent Future of Scientific Discovery
The future of scientific knowledge retrieval hinges on increasingly sophisticated systems capable of not just finding relevant papers, but intelligently prioritizing them. Agentic rerankers, exemplified by models like DeepEra, represent a significant step towards this goal, functioning as iterative evaluators that refine search results based on complex reasoning. However, realizing the full potential of these tools demands rigorous testing and validation; this is where datasets like SciRAG-SSLI become essential. SciRAG-SSLI provides a challenging benchmark, specifically designed to assess a reranker’s ability to synthesize information and identify truly impactful findings within a vast landscape of scholarly literature, ensuring that these intelligent systems genuinely enhance, rather than distort, the process of scientific discovery.
The advancement of artificial intelligence in scientific discovery is increasingly reliant on the availability of comprehensive data, and open scholarly metadata repositories like OpenAlex are proving pivotal in this regard. These repositories aggregate information about scientific publications – authors, affiliations, abstracts, citations, and more – creating a rich, interconnected network of knowledge. By providing access to this data, OpenAlex facilitates the construction of significantly larger and more diverse training datasets for machine learning models. This expanded data pool enables algorithms to identify subtle patterns, generate novel hypotheses, and ultimately accelerate the pace of scientific breakthroughs, moving beyond the limitations of datasets confined to single institutions or disciplines. The accessibility of such resources democratizes research, empowering a wider range of scientists and fostering collaborative innovation.
The convergence of improved knowledge retrieval and intelligent agent systems promises a transformative shift in the landscape of scientific research. These advancements aren’t simply about automating tasks; they represent the creation of powerful tools capable of augmenting human intellect and accelerating the pace of discovery. Researchers will increasingly be able to leverage these systems to synthesize information from vast and disparate sources, identify hidden connections, and formulate novel hypotheses with unprecedented efficiency. This collaborative potential – pairing computational power with human creativity – is expected to drive innovation across all scientific disciplines, from materials science and drug discovery to fundamental physics and beyond, ultimately reshaping how knowledge is generated and applied.
The pursuit of reliable knowledge, as demonstrated by DeepEra, echoes a fundamental truth about complex systems. Every iteration refines the approach, acknowledging that initial results are seldom perfect. This aligns with Edsger W. Dijkstra’s observation: “It’s not enough to have good intentions; you also need good execution.” DeepEra’s agentic reranker isn’t simply about retrieving information; it’s about the diligent execution of filtering irrelevant passages and prioritizing logically relevant evidence, much like carefully reviewing and debugging code. The system doesn’t merely attempt Retrieval-Augmented Generation, it actively strives for a graceful decay of error through continuous refinement, a principle central to maintaining robust systems over time.
What Lies Ahead?
The pursuit of reliable scientific question answering, as exemplified by DeepEra, inevitably encounters the inherent decay of information systems. While agentic reranking represents a step toward mitigating the ‘noise’ within retrieval-augmented generation, it does not eliminate the fundamental problem: evidence, however logically prioritized, is still a snapshot of a continually evolving understanding. The system, in identifying relevant passages, merely delays the inevitable introduction of new data that renders those passages incomplete, or even incorrect.
Future work will likely focus on quantifying not just what is retrieved, but when that information ceases to be reliably relevant. A temporal dimension to relevance – an acknowledgement that knowledge has a half-life – could prove crucial. This shifts the challenge from simple filtering to a predictive modeling of informational decay, anticipating the need for updates before errors propagate. The agent, then, becomes less a librarian and more a curator, proactively managing a collection’s obsolescence.
Ultimately, DeepEra, and systems like it, chart a course toward increasingly sophisticated error management. Incidents – instances where retrieved evidence fails to provide a satisfactory answer – are not failures of the system, but necessary steps toward maturity. The true measure of success will not be the elimination of errors, but the efficiency with which the system learns from, and adapts to, its own inevitable imperfections.
Original article: https://arxiv.org/pdf/2601.16478.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Charlie Day Confirms What Always Sunny Scene Is His Career Highlight
2026-01-27 00:59