Author: Denis Avetisyan
Researchers have developed a novel architecture, Momentum Mamba, to better capture long-range dependencies in inertial sensor data for more accurate human activity recognition.
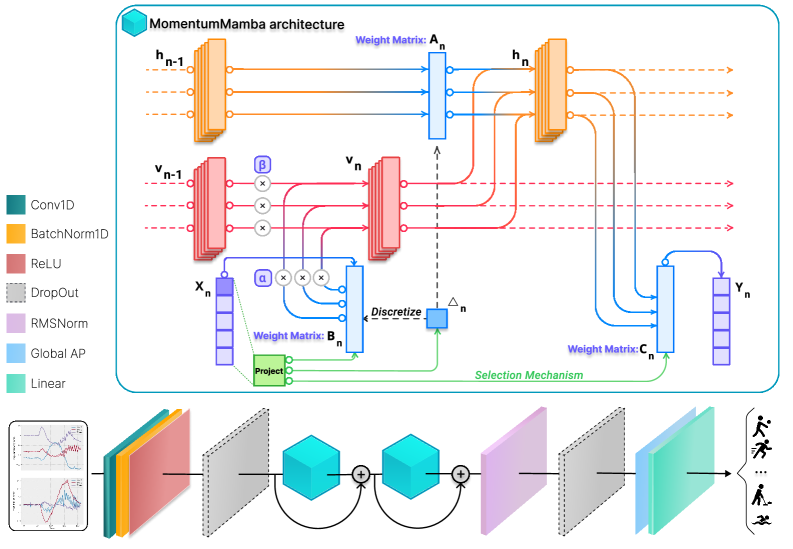
Momentum Mamba integrates momentum-based recurrence into state space models to improve gradient stability and performance with inertial measurement units.
Despite advances in deep learning, human activity recognition from inertial sensors remains challenged by limitations in capturing long-range dependencies and maintaining stable training dynamics. This paper introduces ‘MMA: A Momentum Mamba Architecture for Human Activity Recognition with Inertial Sensors’, a novel state-space model that augments traditional Mamba architectures with second-order dynamics via momentum recurrence. This approach demonstrably improves gradient stability, robustness, and performance on benchmark datasets, offering a favorable balance between accuracy and computational efficiency. Could momentum-augmented state-space models represent a scalable paradigm not only for human activity recognition, but for a broader class of sequence modeling tasks?
The Challenge of Temporal Dependencies in Human Activity Recognition
Human Activity Recognition systems fundamentally depend on understanding the relationships between sensor data points collected over time; a person’s gait, for example, isn’t defined by a single accelerometer reading, but by the sequence of movements. Traditional machine learning approaches often treat these data points as independent, or consider only short windows of time, failing to capture these crucial temporal dependencies. This limitation becomes particularly problematic when analyzing complex activities – such as navigating a building or performing a multi-step task – where relevant information may be spread across extended periods. The inability to model these long-range dependencies significantly impacts the accuracy of HAR systems, hindering their ability to differentiate between similar activities or recognize subtle changes in behavior, and prompting researchers to explore more sophisticated methods capable of retaining information over longer sequences.
While both Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs) have proven effective in various sequence modeling tasks, their ability to fully capture long-range dependencies in Human Activity Recognition (HAR) is often constrained. RNNs, though designed for sequential data, can struggle with very long sequences due to the vanishing gradient problem and difficulties in maintaining information over extended time steps. CNNs, traditionally employed for spatial data, require stacking numerous layers to increase their receptive field and capture broader temporal contexts, which can be computationally expensive and still may not fully encompass the necessary long-range interactions. Consequently, complex activities involving subtle cues spread across time-such as identifying a fall from a series of postural adjustments or differentiating between similar movements-can prove challenging, leading to decreased accuracy and reliability in HAR systems.
The training of deep neural networks, crucial for discerning complex patterns in human activity recognition, often encounters a significant obstacle: the vanishing gradient problem. During backpropagation, the gradients-signals used to adjust the network’s internal parameters-can become progressively smaller as they travel backward through numerous layers. This attenuation effectively prevents earlier layers from learning long-range dependencies within time series data, as their parameter updates become negligible. Consequently, the network struggles to correlate events separated by significant time intervals, limiting its ability to accurately recognize activities that unfold over extended periods. The issue isn’t a failure of the algorithm itself, but rather a limitation in its capacity to efficiently propagate learning signals across deep architectures, hindering the extraction of meaningful temporal relationships from sensor data.

Selective State Space Models: A Principled Approach to Sequence Modeling
Structured State Space Models (SSMs) present a computationally efficient alternative to recurrent and convolutional neural networks for sequence modeling. Traditional RNNs exhibit $O(T)$ complexity per step, where $T$ is the sequence length, while CNNs require $O(T)$ operations for each layer. SSMs, however, achieve linear time complexity, $O(T)$, by formulating the sequence modeling problem as a continuous-time system discretized for computation. This is accomplished through the use of state space representations, allowing for parallelization and efficient computation of hidden states. The linear scaling of SSMs with sequence length enables processing of substantially longer sequences compared to traditional methods, offering significant advantages in applications such as long-form text generation and high-resolution video processing.
Mamba implements selective recurrence by introducing a mechanism to dynamically modulate the hidden state based on input context. This is achieved through a learned selection function that determines which past states are relevant for processing the current input. Unlike traditional recurrent neural networks (RNNs) which process all past states at each step, or convolutional neural networks (CNNs) which have a fixed receptive field, Mamba’s selection mechanism allows it to adaptively focus on the most informative parts of the sequence. This selective approach reduces computational complexity, as only a subset of previous states actively contribute to the current hidden state, and improves performance by prioritizing relevant information, thereby enabling more efficient long-range dependency modeling. The selection is parameterized and learned during training, allowing the model to optimize its focusing strategy based on the characteristics of the input data.
Traditional Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs) encounter difficulties when modeling long sequences due to limitations in their ability to effectively propagate information across many time steps or capture relationships between distant elements. RNNs suffer from vanishing or exploding gradients, hindering learning of long-range dependencies, while CNNs require a large number of layers to achieve a sufficiently large receptive field, increasing computational cost. Mamba addresses these limitations by employing a selective state space model that dynamically focuses on the most relevant parts of the input sequence. This selective attention mechanism allows Mamba to prioritize crucial states, effectively bypassing irrelevant information and maintaining a strong signal for long-range dependencies, thereby improving performance and efficiency in sequence modeling tasks.

Momentum Mamba: Stabilizing Learning and Enhancing Performance
Momentum Mamba addresses the Vanishing Gradient Problem, a common issue in training deep neural networks, by incorporating momentum into the Mamba architecture. Traditional gradient descent can struggle with long sequences due to exponentially decaying gradients; momentum helps to accelerate gradient descent in the relevant direction and dampens oscillations. This is achieved by adding a fraction of the previous update vector to the current update vector, effectively accumulating velocity. By maintaining this ‘momentum’, the model can continue updating weights even when the current gradient is small, thereby improving gradient stability and enabling more effective learning, particularly in long-range dependencies within sequential data. This technique allows for more robust training and improved performance compared to standard Mamba implementations.
The integration of momentum into Momentum Mamba introduces second-order dynamics, effectively modeling the rate of change of the state alongside the state itself. This is achieved by accumulating a velocity vector that considers both the current gradient and the previous velocity, expressed as $v_t = \beta v_{t-1} + (1 – \beta) \nabla L(\theta_t)$. This mechanism allows the model to dampen oscillations and accelerate convergence during training, particularly beneficial when dealing with the complexities inherent in time series data. By considering not just the current error but also the history of updates, the model becomes more responsive to changes in the input sequence and exhibits enhanced stability, preventing abrupt shifts in the learned parameters.
Evaluations of Momentum Mamba on established Human Activity Recognition (HAR) datasets demonstrate significant performance gains. Specifically, the model achieved 98.43% accuracy on the MuWiGes dataset and 75.49% accuracy on the MMAct dataset. These results indicate that the integration of momentum enhances the model’s ability to accurately classify activities within these benchmark datasets, providing empirical validation of its effectiveness in HAR tasks.
Evaluations on the UESTC-MMEA-CL dataset demonstrate a statistically significant performance increase with Momentum Mamba. Specifically, Momentum Mamba achieved an accuracy improvement of +3.63% when compared to the Vanilla Mamba model on this dataset. This result indicates that the integration of momentum within the Mamba architecture contributes to a more robust and accurate model, particularly when applied to complex datasets like UESTC-MMEA-CL, which is designed to test the ability to model challenging time-series data.
Complex-Valued Momentum Mamba and Adam Momentum Mamba represent refinements to the core Momentum Mamba architecture. Complex-valued momentum introduces the capability for frequency-selective memory, allowing the model to prioritize and retain information at specific frequencies within the input data. Adam Momentum Mamba integrates the adaptive momentum scaling features of the Adam optimizer, dynamically adjusting the momentum coefficient for each parameter based on its historical gradients. This adaptive scaling improves training stability and convergence speed, ultimately leading to enhanced performance compared to standard momentum implementations. These modifications allow the model to more effectively capture temporal dependencies and improve accuracy on time series data.

Practical Implications and Future Directions for HAR
The convergence of Momentum Mamba with Inertial Measurement Units (IMUs) is poised to redefine the landscape of Human Activity Recognition (HAR). This integration facilitates remarkably accurate activity classification directly on the sensor, eliminating the need to transmit raw data to the cloud and thus preserving user privacy. Applications span a broad spectrum, from proactive healthcare solutions – such as fall detection and personalized rehabilitation programs – to intuitive human-computer interaction, enabling gesture-based control of devices and immersive virtual reality experiences. By processing data locally, Momentum Mamba not only safeguards sensitive information but also reduces latency, paving the way for real-time applications and broadening the scope of wearable and embedded sensor technologies.
The streamlined architecture of Momentum Mamba facilitates its implementation on devices with limited processing power and memory, opening doors for a wider range of applications in human activity recognition. This efficiency is crucial for extending the reach of wearable sensors – from fitness trackers and smartwatches to medical monitoring systems – and embedding intelligence directly into edge devices. Researchers envision a future where sophisticated activity analysis isn’t confined to cloud servers, but can occur locally, enhancing user privacy and reducing latency. The ability to perform complex computations directly on the device also promises lower energy consumption and increased responsiveness, paving the way for truly ubiquitous and personalized sensing experiences.
Performance evaluations reveal Momentum Mamba completes processing in 0.007 seconds, a slight increase compared to Vanilla Mamba’s 0.0052 seconds. While the difference appears marginal, it represents a crucial trade-off for enhanced accuracy and privacy within human activity recognition (HAR) systems. This timing demonstrates the model’s feasibility for real-time applications, allowing for responsive interactions in areas like healthcare monitoring and human-computer interfaces. Further optimization of the momentum mechanism could potentially bridge this gap, delivering both speed and improved performance, but the current processing time establishes Momentum Mamba as a viable solution for latency-sensitive HAR tasks.
Despite achieving comparable processing speeds to its predecessor, Vanilla Mamba, Momentum Mamba exhibits a slightly increased demand for Video Random Access Memory (VRAM). Evaluations reveal Momentum Mamba consumes 212.41 MB of VRAM during operation, exceeding Vanilla Mamba’s 188.41 MB. While this difference represents a modest increase, it’s a crucial consideration for deployments on devices with limited memory resources. Further optimization of the model architecture and memory management techniques could mitigate this increased VRAM usage, potentially unlocking broader applicability across a wider range of hardware platforms and embedded systems without compromising performance.
The future of human activity recognition and sequence modeling hinges on refining the momentum-based techniques demonstrated by Momentum Mamba. Ongoing investigation into adaptive learning algorithms, coupled with innovations in momentum application, promises to overcome limitations in processing sequential data, particularly when dealing with the inherent variability of human movement. These advancements aren’t limited to wearable sensors; the principles could be broadly applied to areas requiring time-series analysis, such as predictive maintenance in industrial settings, financial forecasting, and even natural language processing where understanding sequence is paramount. By dynamically adjusting to incoming data and optimizing momentum calculations, future systems will achieve greater accuracy, efficiency, and robustness, ultimately expanding the scope of applications reliant on understanding complex sequential patterns.

The pursuit of robust and reliable human activity recognition, as detailed in this work, echoes a fundamental tenet of mathematical rigor. The authors’ focus on gradient stability within the Momentum Mamba architecture, and its capacity to model long-range dependencies, is akin to establishing a solid axiomatic foundation. As David Hilbert famously stated, “One must be able to command a situation by having a clear plan of action.” This principle directly translates to the design of state-space models; a well-defined architecture, like Momentum Mamba, ensures predictable behavior and facilitates provable performance – moving beyond mere empirical success to a demonstrably correct solution. The integration of momentum-based recurrence is not simply an optimization, but a step towards mathematical elegance in signal processing.
Future Directions
The introduction of Momentum Mamba represents a step – a potentially significant one – toward rectifying the persistent issue of gradient instability within state-space models. However, elegance in architecture does not automatically translate to optimality. The model’s performance, while promising, remains fundamentally constrained by the inherent limitations of approximating continuous dynamics with discrete representations. The true test will lie in its scalability to datasets orders of magnitude larger and more complex than those currently employed – a domain where asymptotic behavior, not mere empirical success, will dictate viability.
A critical area for future investigation concerns the model’s sensitivity to hyperparameter selection. The current reliance on empirical tuning suggests a lack of deeper theoretical understanding of the interplay between recurrence, momentum, and selective mechanisms. A mathematically rigorous derivation of optimal parameter settings – one that transcends the need for exhaustive search – would elevate this work from engineering to science.
Finally, the field should address the question of whether the benefits of Momentum Mamba justify its increased architectural complexity. Simplicity, after all, possesses an inherent robustness. The pursuit of ever-more-intricate models must be tempered by a recognition that true progress lies not in adding layers, but in achieving greater insight with fewer assumptions.
Original article: https://arxiv.org/pdf/2511.21550.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- World Eternal Online promo codes and how to use them (September 2025)
- Clash Royale Season 79 “Fire and Ice” January 2026 Update and Balance Changes
- Best Arena 9 Decks in Clast Royale
- M7 Pass Event Guide: All you need to know
- Clash Royale Furnace Evolution best decks guide
- Best Hero Card Decks in Clash Royale
- Clash Royale Witch Evolution best decks guide
2025-11-28 18:19