Author: Denis Avetisyan
Researchers are harnessing the power of large AI models to understand human actions and their relationships with objects in images, even without prior training on those specific interactions.
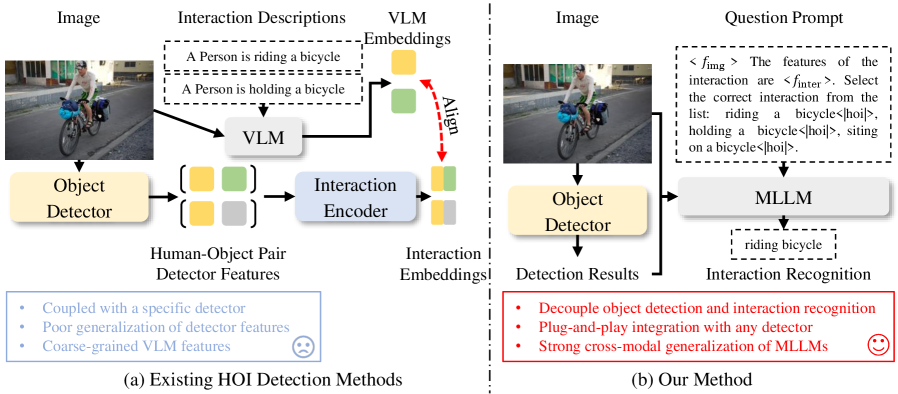
A novel decoupled framework leverages multi-modal large language models for zero-shot human-object interaction detection, achieving state-of-the-art performance through deterministic generation and spatial-aware pooling.
Recognizing human-object interactions (HOIs) remains a challenge despite advances in object detection, largely due to the vast combinatorial possibilities of such interactions. This paper, ‘Zero-shot HOI Detection with MLLM-based Detector-agnostic Interaction Recognition’, introduces a novel decoupled framework that leverages multi-modal large language models (MLLMs) to perform zero-shot HOI detection by separating object detection from interaction recognition. The core innovation lies in formulating interaction recognition as a visual question answering task with deterministic generation, enabling accurate and efficient zero-shot performance without retraining. Could this detector-agnostic approach and reliance on MLLMs unlock a new era of generalizable and adaptable HOI detection systems?
Unveiling Relational Understanding: The Core of Visual Intelligence
The automated recognition of human-object interaction within visual data presents a persistent difficulty for computer vision systems. While algorithms excel at identifying individual elements – a person, a chair, a cup – discerning how these entities relate functionally proves far more complex. Systems must move beyond simple object detection to infer actions and intentions from visual cues, accounting for variations in pose, lighting, and viewpoint. This requires not merely recognizing ‘a person near a table’ but understanding if that person is ‘placing an object on the table’, ‘reaching for an object’, or ‘sitting at the table’. Consequently, developing algorithms capable of accurately interpreting these dynamic relationships remains central to advancements in robotics, autonomous navigation, and assistive technologies.
Conventional computer vision techniques frequently falter when confronted with intricate visual scenarios. These methods often rely on isolated object recognition, proving insufficient for deciphering the interplay between objects and their surroundings. A truly comprehensive understanding demands more than just identifying what is present; it necessitates discerning where objects are in relation to one another – their spatial relationships – and interpreting these arrangements within the broader context of the scene. For instance, a system must not only recognize a person and a chair, but also understand if the person is seated on the chair, leaning towards a table, or positioned near a doorway, all of which require a nuanced grasp of both geometry and semantic meaning to accurately interpret the visual information.
A primary limitation of current computer vision systems lies in their difficulty generalizing to novel situations-specifically, recognizing interactions involving objects or actions not explicitly encountered during training. While a system might reliably identify a person handing an apple to another person, it may falter when presented with a person offering a banana, or interacting with a previously unseen object like a drone. This lack of adaptability hinders deployment in real-world scenarios, which are inherently unpredictable and diverse; robust performance demands an ability to infer relationships and apply learned knowledge to entirely new combinations of objects and actions. Overcoming this generalization hurdle requires moving beyond simple pattern recognition toward systems capable of abstract reasoning and contextual understanding, enabling them to interpret scenes with the same flexibility and intuition as a human observer.
Bridging Perception and Language: A New Paradigm for Interaction Understanding
Multi-Modal Large Language Models (MLLMs) represent a significant advancement in Human-Object Interaction (HOI) detection by integrating visual and textual data processing. Traditionally, HOI detection relied on models trained specifically on labeled images of human-object interactions. MLLMs, however, leverage the power of large language models pre-trained on extensive text corpora and combine this with visual encoders to process image data. This fusion allows the model to understand relationships between humans and objects based on both visual features and semantic knowledge derived from language. The architecture typically involves extracting visual features from images and then mapping these features into a shared embedding space with textual representations, enabling the model to reason about interactions described in natural language and generalize to unseen scenarios.
CLIP (Contrastive Language-Image Pre-training) establishes a connection between visual and textual representations by learning to align images with their corresponding text descriptions. This is achieved through a contrastive learning objective, where the model is trained to maximize the similarity between the embeddings of matching image-text pairs and minimize the similarity between non-matching pairs. Consequently, CLIP generates image and text embeddings in a shared vector space, enabling zero-shot transfer to tasks like HOI detection. By leveraging pre-trained semantic knowledge encoded in the language domain, CLIP can recognize HOIs in images without requiring specific training data for those interactions, significantly improving generalization to novel or unseen scenarios and object combinations.
Zero-shot Human-Object Interaction (HOI) detection leverages the capabilities of multi-modal large language models to identify interactions between humans and objects without requiring task-specific training data. Traditional HOI detection relies on extensive labeled datasets for each interaction type; however, these models utilize pre-trained knowledge acquired from vast amounts of image-text pairings to generalize to unseen interactions. This is achieved by framing HOI detection as a language modeling task, where the model predicts the interaction given visual features and a textual prompt. Performance is evaluated on datasets containing interaction types not present during training, demonstrating the model’s ability to extrapolate and recognize novel HOIs, representing a key advancement towards more adaptable and generalized artificial intelligence systems.

Streamlining Inference: Efficiency Through Deterministic Mapping
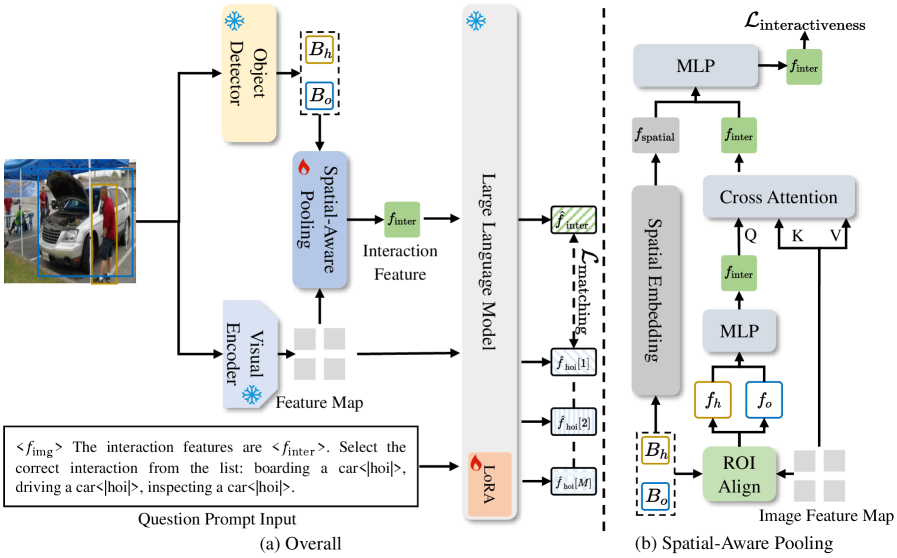
One-Pass Deterministic Matching addresses computational limitations in interaction prediction by shifting the paradigm from sequential decoding to a feature matching task. Traditional methods often require iterative search and evaluation of possible interactions, which scales poorly with complexity. This approach instead transforms the problem into identifying the most similar feature vector representing a potential interaction within a pre-defined set of candidates. By formulating interaction prediction as a nearest neighbor search in feature space, inference speed is significantly improved, as it bypasses the need for computationally expensive decoding steps and allows for efficient parallel processing of candidate interactions. This method effectively reduces the algorithmic complexity, enabling real-time or near real-time inference on resource-constrained devices.
Spatial-Aware Pooling improves the reliability of interaction recognition by explicitly incorporating both the spatial relationships and visual characteristics of interacting agents. This technique moves beyond treating agents as isolated entities by calculating features based on pairwise comparisons, effectively modeling how their positions relative to each other influence interaction probabilities. Specifically, it integrates spatial information – such as distance and relative bearing – with appearance features extracted from each agent, creating a more comprehensive representation for downstream interaction classification. This integration allows the model to better discern meaningful interactions even under conditions of occlusion, varying viewpoints, or cluttered scenes, ultimately enhancing the robustness of the system.
Parameter-efficient fine-tuning, specifically employing the Low-Rank Adaptation (LoRA) method, significantly reduces the computational cost associated with adapting Multimodal Large Language Models (MLLMs) to new tasks or datasets. LoRA achieves this by freezing the pre-trained model weights and introducing a smaller set of trainable, low-rank matrices. This approach drastically reduces the number of trainable parameters – often by orders of magnitude – compared to full fine-tuning, enabling faster adaptation with limited computational resources and minimizing the risk of catastrophic forgetting. Consequently, MLLMs can be rapidly customized for specific applications without requiring extensive retraining of the entire model.

Demonstrating Robustness: Benchmarking and Generalization Capabilities
The efficacy of this human-object interaction (HOI) detection framework is rigorously confirmed through evaluations on established benchmark datasets, notably HICO-DET and V-COCO. These datasets provide a standardized and challenging environment for assessing the model’s ability to accurately identify interactions between humans and objects in complex scenes. Competitive results on both datasets demonstrate the framework’s robust performance and its capacity to generalize to diverse visual scenarios. Specifically, successful validation against these benchmarks underscores the model’s potential for practical application in areas like robotics, video surveillance, and augmented reality, where reliable HOI detection is crucial for contextual understanding.
A critical aspect of this research involves assessing the model’s adaptability beyond a specific training configuration, achieved through evaluation in a cross-detector setting. This rigorous process involves training the human-object interaction (HOI) detection framework with one object detection pipeline and then testing its performance when paired with entirely different detectors. Such evaluation moves beyond simply demonstrating performance within a controlled environment; it reveals the model’s capacity to generalize its understanding of interactions, irrespective of how individual objects are initially identified. This is crucial for practical deployment, as real-world applications rarely permit exclusive control over the object detection component, and a robust HOI detector must function effectively with a variety of upstream detectors to be truly useful. The ability to maintain high accuracy across diverse detection pipelines signifies a more versatile and deployable system, addressing a key limitation of previous HOI detection methods.
The newly proposed framework establishes a new benchmark in human-object interaction (HOI) detection, achieving a state-of-the-art mean Average Precision (mAP) of 59.91% on the highly competitive V-COCO dataset. This performance represents a significant advancement over previously established methods, indicating a substantial improvement in the framework’s ability to accurately identify and categorize interactions between humans and objects in complex visual scenes. The V-COCO dataset is particularly challenging due to its scale and diversity, encompassing a wide range of interactions and requiring robust generalization capabilities; therefore, this result underscores the framework’s effectiveness and potential for real-world application in areas such as robotics, video surveillance, and assistive technologies. The demonstrated improvement isn’t incremental, but rather positions the framework as a leading solution in the field of HOI detection.
The proposed framework showcases substantial advancement in fully supervised human-object interaction (HOI) detection, achieving a mean Average Precision (mAP) of 44.58% on the challenging HICO-DET dataset. This performance signifies a marked improvement over existing methodologies, indicating the framework’s enhanced ability to accurately identify and categorize interactions between humans and objects. HICO-DET’s complexity stems from its large-scale nature and diverse range of interactions, making this result particularly noteworthy as it demonstrates robust generalization across a wide spectrum of scenarios. The achieved mAP not only validates the framework’s efficacy but also positions it as a strong contender for practical HOI detection applications requiring high accuracy in controlled, labeled environments.

The pursuit of robust zero-shot HOI detection, as detailed in this work, mirrors a fundamental principle of understanding any complex system: identifying core patterns independent of specific instances. This research champions a decoupled framework, separating object detection from interaction recognition – a logical dissection allowing for greater adaptability. Geoffrey Hinton once stated, “The problem with deep learning is that it’s a black box – we don’t really understand how it works.” While this paper doesn’t necessarily solve the black box problem, the deterministic generation approach-a key aspect of the proposed method-represents a step towards increased explainability, allowing researchers to more confidently interpret the reasoning behind the model’s interaction predictions and move beyond purely performance-based evaluations.
Beyond the Immediate Horizon
The decoupling of object detection from interaction recognition, as demonstrated, presents a compelling architecture, yet the reliance on MLLMs introduces a fascinating bottleneck. While deterministic generation improves upon the stochastic nature of many large models, it merely addresses a symptom. The true challenge lies in the models’ inherent understanding – or lack thereof – of physical plausibility. A system can accurately label ‘person holding banana,’ but possesses no intrinsic comprehension of gravitational forces, material properties, or the practical limitations of human dexterity. Future iterations must incorporate mechanisms for validating interactions against a rudimentary ‘physics engine’ – a grounding in the real world to counteract the purely statistical nature of current approaches.
Furthermore, the zero-shot capability, while impressive, reveals the limitations of relying solely on language-based knowledge transfer. The system excels when interactions align with commonly expressed concepts, but struggles with novel or nuanced scenarios. A logical next step involves the integration of a dynamically updated ‘interaction graph’ – a knowledge base constructed not just from textual data, but from visual observations, allowing the model to infer relationships and generalize to previously unseen combinations.
Ultimately, this work highlights a broader philosophical point: intelligence isn’t about memorizing labels, but about building predictive models of the world. The current framework offers a promising step towards this goal, but the path forward requires a shift in focus – from simply recognizing interactions to understanding them, and ultimately, anticipating them.
Original article: https://arxiv.org/pdf/2602.15124.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Gold Rate Forecast
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
2026-02-18 16:49