Author: Denis Avetisyan
A new framework leverages the power of masked generative transformers to reconstruct accurate 3D human motion from video, even when parts of the body are hidden from view.
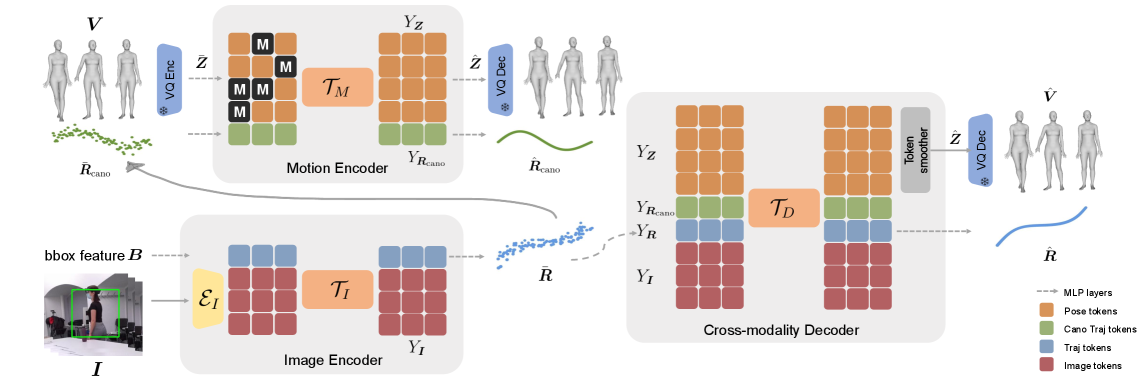
MoRo utilizes multi-modal learning and masked modeling to achieve robust 3D human pose estimation and trajectory reconstruction under challenging occlusion scenarios.
Accurate 3D human motion reconstruction from video remains a challenge when faced with real-world occlusions, often requiring a trade-off between robustness and computational efficiency. This paper introduces ‘Masked Modeling for Human Motion Recovery Under Occlusions’, a novel framework-MoRo-that leverages masked generative transformers and multi-modal learning to address this limitation. MoRo achieves robust and efficient reconstruction by formulating the task as video-conditioned masked modeling, effectively handling occlusions and integrating diverse motion and pose priors. Could this approach unlock more seamless and realistic human-computer interaction in AR/VR and robotics applications?
Whispers of Movement: The Challenge of Robust 3D Motion Capture
The ability to accurately translate human movement into digital 3D representations is becoming increasingly vital across a spectrum of rapidly evolving technologies. For augmented and virtual reality (AR/VR) systems, precise motion capture enables seamless interaction and realistic avatar control, enhancing immersion and user experience. Similarly, in the field of robotics, understanding and replicating human motion is fundamental for creating robots capable of intuitive collaboration, safe navigation in human environments, and even empathetic interaction. Beyond entertainment and automation, applications extend to biomechanical research, personalized healthcare – such as gait analysis and rehabilitation – and remote operation of complex machinery, all relying on the fidelity of captured 3D pose and motion data to function effectively.
Current 3D motion capture technologies frequently encounter difficulties when applied to realistic environments, largely due to the pervasive issue of self-occlusion and external obstructions. As a subject moves, their limbs and torso inevitably pass in front of one another, or are hidden by objects in the scene, causing visual data to be lost to tracking algorithms. This incomplete information forces systems to make estimations about obscured body parts, often leading to inaccuracies in reconstructed poses and movements. The problem is exacerbated by the limited viewpoints of typical camera setups; a single camera may not capture the full extent of a motion, while even multiple cameras can struggle with complex occlusions. Consequently, achieving robust and reliable 3D motion capture in unconstrained, real-world settings remains a significant technical hurdle, necessitating the development of techniques capable of intelligently inferring and reconstructing motion despite incomplete visual input.
Addressing the inherent difficulties of 3D motion capture requires a shift toward techniques that intelligently infer missing information during periods of self-occlusion or external obstruction. Researchers are increasingly focused on methods that move beyond simply tracking visible joints, instead leveraging learned priors about human biomechanics and motion patterns to predict plausible poses even when visual data is incomplete. This often involves incorporating generative models and statistical techniques that can ‘fill in the gaps’ by extrapolating from past observations and understanding the natural constraints of human movement. The goal is not merely to reproduce observed motion, but to create a complete and physically believable reconstruction, offering a robust solution for applications where uninterrupted tracking is paramount, such as immersive virtual reality or human-robot interaction.
The limitations of conventional 3D motion capture techniques become strikingly apparent when confronted with novel scenarios, hindering their widespread adoption in real-world applications. Existing systems, frequently reliant on meticulously curated datasets and rigid parameter settings, demonstrate a pronounced inability to accurately reconstruct motion outside of the specific poses and environments upon which they were trained. This lack of generalization stems from an over-reliance on memorization rather than true understanding of underlying biomechanical principles; a system proficient at recognizing a walking gait in a laboratory setting may falter when presented with an individual performing a dance or navigating uneven terrain. Consequently, these methods demand extensive re-calibration or data collection for each new context, significantly increasing costs and reducing the practicality of deploying 3D motion capture in dynamic, uncontrolled settings like augmented reality or remote robotics.
Sculpting Movement from Probability: Generative Approaches and Learned Motion Priors
Generative modeling addresses inherent ambiguities in 3D motion reconstruction by statistically representing the distribution of human movement. Unlike traditional methods that seek a single, optimal solution, generative approaches learn the probabilities of different poses and trajectories observed within a training dataset. This allows the system to produce multiple plausible reconstructions given incomplete or noisy input data, and to effectively handle cases where a unique solution cannot be determined. By characterizing the learned distribution, the model can sample likely poses, resulting in more robust and realistic motion reconstruction, particularly in scenarios with occlusion or limited sensor data.
Methods leveraging learned motion priors address the inherent ambiguity in 3D motion reconstruction by statistically predicting likely human poses and trajectories when sensor data, such as video or depth images, provides incomplete observations. These priors, derived from extensive motion capture data, effectively constrain the solution space, allowing algorithms to infer plausible configurations even in the presence of occlusions or noisy input. This predictive capability is based on the statistical likelihood of observed motion given the learned distribution, enabling the generation of complete and realistic motion sequences despite data limitations. The efficacy of this approach stems from the assumption that human movement adheres to certain patterns and constraints, which are captured by the learned prior.
Learned motion priors are commonly derived from extensive motion capture datasets, with AMASS being a prominent example, containing over 600 hours of multi-subject 3D motion data. Utilizing these large-scale datasets allows generative models to statistically represent a broad spectrum of human movements, encompassing diverse activities, styles, and anatomical variations. This data-driven approach enables the generation of motions that adhere to biomechanical plausibility and exhibit realistic characteristics, effectively addressing the ill-posed nature of 3D motion reconstruction and improving the quality of predicted poses and trajectories.
Vector Quantized Variational Autoencoders (VQ-VAEs) are utilized to compress high-dimensional human mesh data into a discrete latent space. This is achieved by learning a codebook of representative mesh embeddings; during encoding, the input mesh is mapped to the closest embedding in the codebook, resulting in a discrete latent representation. This discretization significantly reduces computational complexity during both training and inference, enabling more efficient learning of motion priors and faster generation of new poses. The discrete nature also encourages the model to learn a structured and organized representation of human body configurations, improving the quality and realism of generated motions.
MoRo: A Masked Modeling Framework for Robust Reconstruction
MoRo utilizes a masked modeling framework to address limitations in 3D human pose reconstruction when faced with occlusions. The approach involves randomly masking portions of the input data – specifically, features extracted from images – during the training process. The model is then tasked with reconstructing the missing, or masked, information. This forces the network to learn robust feature representations and develop an understanding of human motion that is less reliant on complete visual data, ultimately improving the accuracy and resilience of 3D pose estimations in scenarios with partial visibility. The technique effectively trains the model to infer plausible poses even when significant portions of the subject are obscured.
MoRo utilizes a masked modeling approach where portions of the input data-specifically, visual features-are randomly removed during the training process. The model is then tasked with reconstructing the masked regions based on the remaining visible information. This forces the network to learn robust representations and develop an understanding of underlying motion patterns, enabling it to infer plausible movement even when significant portions of the input are occluded or unavailable. This reconstruction capability is achieved through the prediction of missing features, effectively training the model to reason about and complete incomplete observations, thereby improving performance in scenarios with limited visibility.
The MoRo framework incorporates a pose prior derived from a Vision Transformer (ViT-H/16) architecture, pre-trained on image data to establish a strong understanding of human pose. This prior, conditioned on the input image, provides critical constraints during the 3D pose reconstruction process, effectively reducing ambiguity and improving accuracy, particularly in challenging scenarios involving occlusions or limited visibility. The ViT-H/16 model’s learned representations of pose are integrated as an inductive bias, guiding the reconstruction towards plausible solutions consistent with typical human anatomy and motion, and serving as a regularizer to prevent overfitting to incomplete or noisy input data.
The MoRo framework utilizes a spatial-temporal transformer to process both visual features extracted from the input imagery and the learned motion prior, enabling the model to capture temporal dependencies and contextual information crucial for accurate pose estimation. This transformer’s output is then fed into a cross-modality decoder which fuses the processed visual and motion data. The decoder’s architecture is designed to translate this combined representation into a final 3D pose estimation, effectively leveraging the strengths of both visual observation and the learned prior to achieve robust and accurate results even in challenging scenarios with occlusions or limited visibility.
Validating Performance and Demonstrating Generalization
MoRo establishes new state-of-the-art performance on the RICH and EgoBody datasets, both of which present significant challenges in 3D human pose and motion reconstruction. RICH is characterized by complex scenes and substantial occlusion, while EgoBody focuses on first-person, egocentric viewpoints with dynamic backgrounds. MoRo’s success on these datasets indicates its robustness to varying levels of self-occlusion and environmental complexity, demonstrating an ability to accurately reconstruct poses even when significant portions of the subject are obscured or the scene is visually cluttered. This performance is critical for applications requiring reliable pose estimation in real-world, unconstrained conditions.
Model performance was quantitatively assessed using a suite of established metrics for 3D human pose estimation. These included PA-MPJPE (Pose Accuracy – Mean Per Joint Position Error), which measures the average distance between predicted and ground truth joint positions; Per Vertex Error (PVE), quantifying error at the mesh vertex level; Global MPJPE, providing an overall error assessment across all joints; and RTE (Rotation Tracking Error), evaluating the accuracy of predicted joint rotations. Rigorous evaluation using these metrics consistently demonstrated improvements across all dimensions, indicating that the model achieves higher accuracy in both pose and motion reconstruction compared to baseline methods.
MoRo achieves a Mean Per Joint Position Error (MPJPE) of 16 millimeters when reconstructing occluded joints. This represents a 31% performance increase over the previously established best baseline for this metric. The MPJPE is calculated as the average Euclidean distance between the predicted 3D joint locations and the ground truth, specifically focusing on joints that are partially or fully obscured in the input data. This improvement indicates a significant enhancement in the model’s ability to accurately estimate the position of joints even when visual information is limited due to occlusion.
MoRo demonstrates a significant advancement in global human pose estimation, achieving a 58% reduction in Global Mean Joint Position Error (GMPJPE) compared to the RoHM model. GMPJPE, measured in millimeters, quantifies the average distance between predicted and ground truth 3D joint locations across all samples. This substantial improvement indicates MoRo’s superior ability to accurately reconstruct the overall 3D pose of a human subject, even with variations in pose and viewpoint. The metric is calculated as the Euclidean distance between corresponding joints, averaged across all joints and all test samples, providing a comprehensive assessment of pose reconstruction accuracy.
MoRo’s generalization capabilities are substantially improved through the implementation of masked modeling and visual information integration. Masked modeling involves randomly masking portions of the input data during training, forcing the model to learn robust representations and predict missing information – a process that enhances its resilience to data variations and incomplete observations. Simultaneously, the integration of visual information, specifically RGB data, provides crucial contextual cues that complement the skeletal input, allowing MoRo to better interpret ambiguous poses and extrapolate to novel environments. This combined approach enables the model to maintain accuracy and stability when processing previously unseen poses and navigating new, complex scenarios, resulting in improved performance across a range of evaluation metrics.
Evaluations on the RICH and EgoBody datasets demonstrate MoRo’s efficacy in 3D human pose and motion reconstruction under complex conditions. Specifically, the model achieves a 16mm Mean Per Joint Position Error (MPJPE) on occluded joints, representing a 31% performance gain over existing baselines. Furthermore, MoRo’s Global MPJPE is 58% lower than that of RoHM, and improvements are consistent across all evaluation metrics including PA-MPJPE, Per Vertex Error (PVE), and Root Translation Error (RTE). These quantitative results validate MoRo as a robust and accurate solution capable of generalizing to previously unseen poses and challenging real-world environments.

Toward Sentient Systems: Future Directions
Ongoing development prioritizes enhancing MoRo’s computational efficiency to achieve real-time performance, a critical step toward its integration into dynamic applications. This optimization involves streamlining the algorithms and leveraging parallel processing techniques to minimize latency, allowing for immediate responsiveness in interactive environments. The prospect of utilizing MoRo in virtual reality and robotics hinges on this speed, as both fields demand seamless, unnoticeable motion capture for realistic simulations and effective robot control. Ultimately, achieving real-time capabilities will transform MoRo from a research tool into a practical component for creating truly immersive experiences and intelligent robotic systems, broadening its impact beyond controlled laboratory settings.
The current framework’s performance stands to gain significantly from incorporating data beyond standard video input. Researchers are actively investigating the synergistic effects of combining visual information with data streams from depth sensors and inertial measurement units (IMUs). Depth sensors offer precise geometric information, resolving ambiguities present in 2D video and improving the accuracy of pose estimation, particularly in challenging scenarios like occlusions or low-light conditions. Simultaneously, IMUs provide direct measurements of the subject’s acceleration and angular velocity, offering a robust and complementary source of information regarding movement dynamics. By fusing these multi-modal inputs, the system aims to achieve a more resilient and precise 3D human motion capture, enabling reliable performance across a wider range of environments and activities.
Current 3D human motion capture systems often require extensive, manually labeled datasets – a significant bottleneck in terms of both cost and scalability. Researchers are now exploring self-supervised learning approaches to circumvent this limitation. These techniques enable the system to learn directly from unlabeled video data by creating artificial ‘labels’ based on the inherent structure of motion itself – for example, predicting future frames or reconstructing occluded body parts. This allows the system to develop a robust understanding of human movement without relying on painstakingly annotated examples, promising a more adaptable and scalable solution for real-world applications and facilitating deployment in diverse, data-scarce environments.
The convergence of optimized motion capture with advancements in computing promises a future where digital interfaces respond seamlessly to human movement, fostering genuinely immersive experiences. Addressing current limitations in real-time performance and data requirements will be pivotal in realizing this potential, extending beyond passive observation to enable active participation within virtual environments and intuitive control of robotic systems. Such advancements aren’t simply about replicating movement; they represent a paradigm shift in human-computer interaction, moving away from traditional input devices toward a more natural and embodied form of communication, ultimately unlocking applications in fields ranging from entertainment and education to healthcare and remote collaboration.
The pursuit of coherent motion from fragmented observation feels less like optimization and more like a careful domestication of chaos. This work, with its masked generative transformers, doesn’t simply predict trajectory; it conjures it from the whispers of available data, filling the voids left by occlusion. It’s a spell, elegantly cast to persuade the noise into something resembling grace. Fei-Fei Li once observed, “Data isn’t numbers – it’s whispers of chaos.” This sentiment rings true; MoRo doesn’t eliminate uncertainty, it learns to interpret it, coaxing a plausible narrative from the incomplete story a monocular video presents. The framework subtly acknowledges that complete knowledge is an illusion, and reconstruction is an act of informed storytelling.
What Shadows Remain?
The pursuit of complete motion recovery, even with frameworks like MoRo, remains a politely stated impossibility. Each reconstructed trajectory isn’t a revelation of truth, but a carefully constructed hallucination, persuasive because it feels correct. The architecture addresses occlusion, certainly, but the ghost in the machine isn’t a missing limb-it’s the inherent ambiguity of prediction. The model learns to fill voids, but it cannot resurrect information that was never truly present. Future work will inevitably focus on increasingly elaborate masking strategies, but the real challenge isn’t about seeing through obstructions-it’s about gracefully accepting the limits of visibility.
The integration of multi-modal learning is a promising avenue, yet the true power will lie not in simply adding more data streams, but in understanding their dissonances. Noise isn’t a flaw; it’s a signal of the world’s inherent messiness. A perfectly clean dataset is a fiction. The next generation of these models will need to embrace uncertainty, quantifying not just what is predicted, but how confident it is in its own imaginings. Precision, after all, is just a fear of error.
Ultimately, this isn’t about building a perfect digital double. It’s about crafting increasingly sophisticated illusions. The question isn’t whether the reconstruction is ‘correct,’ but whether it’s convincing. And in that space, between what is known and what is merely inferred, lies the true potential – and the beautiful, unsettling mystery – of motion prediction.
Original article: https://arxiv.org/pdf/2601.16079.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Gold Rate Forecast
2026-01-24 20:29