Author: Denis Avetisyan
Researchers have developed a unified model that allows robots to better understand complex instructions and perform intricate tasks by combining visual perception, language understanding, and action planning.
![Halofirst anticipates task completion not through direct instruction, but by cultivating a self-attentive ecosystem of specialized experts - a multimodal understanding module, a visual generator, and an action predictor - working in concert to infer visual subgoals and execute actions conditioned on emergent, contextual reasoning [latex]EM-CoT[/latex] within a Mixture-of-Transformers architecture.](https://arxiv.org/html/2602.21157v1/x1.png)
Halo integrates vision, language, and action within an embodied multimodal chain-of-thought framework to enhance robotic manipulation in challenging environments.
While current vision-language-action (VLA) models excel at robotic manipulation, they often struggle with complex, long-horizon tasks due to limited explicit reasoning capabilities. This paper introduces [latex]HALO[/latex], a unified VLA model for embodied multimodal chain-of-thought (EM-CoT) reasoning, designed to bridge this gap through sequential textual reasoning, visual subgoal prediction, and action planning. HALO, instantiated with a Mixture-of-Transformers architecture and trained with a novel automated data pipeline, demonstrably surpasses baseline performance-achieving a 34.1% improvement on the RoboTwin benchmark-and exhibits strong generalization in unseen environments. Could this unified approach unlock more robust and adaptable robotic systems capable of truly understanding and interacting with the world around them?
The Inevitable Limits of Automation
Conventional robotic systems, despite advancements in mechanics and sensing, frequently encounter limitations when confronted with tasks demanding flexible responses to unpredictable environments. These machines typically operate based on meticulously crafted, pre-programmed sequences, excelling in repetitive actions but faltering when deviations from the expected occur. This reliance on rigid instructions stems from the difficulty of translating the intuitive, contextual reasoning humans employ into algorithms. Consequently, robots struggle with tasks requiring fine motor control in dynamic settings – like grasping deformable objects or navigating cluttered spaces – because any unforeseen obstacle or slight variation necessitates halting the program or producing an error. The inability to adapt effectively underscores a fundamental challenge in robotics: bridging the gap between automated execution and genuine intelligence.
The pursuit of genuinely autonomous robots is significantly hampered by a fundamental limitation: the inability to reliably generalize learned behaviors to novel scenarios or gracefully recover from unforeseen disturbances. Current robotic systems, even those incorporating advanced machine learning, often exhibit brittle performance, excelling in controlled environments but faltering when confronted with the inevitable unpredictability of the real world. A robot trained to assemble a specific object might fail completely if presented with a slightly altered version, or be unable to adjust its actions when an object is unexpectedly moved. This lack of robustness stems from an over-reliance on precisely defined parameters and a limited capacity for real-time adaptation; true autonomy requires not just the ability to perform a task, but to understand the underlying principles and intelligently respond to deviations from the expected-a capacity that remains a considerable engineering challenge.
The pursuit of truly autonomous robots necessitates a fundamental departure from conventional designs. Current robotic systems, while proficient in repetitive actions, falter when confronted with the unpredictable nature of real-world environments. Replicating human-level dexterity and problem-solving capabilities requires architectures that move beyond pre-programmed routines and embrace adaptability. This involves integrating advanced sensing modalities, sophisticated algorithms for perception and planning, and, crucially, machine learning techniques that allow robots to learn from experience and generalize to novel situations. Such intelligent systems will not simply execute commands, but rather understand context, anticipate challenges, and dynamically adjust strategies – effectively bridging the gap between automation and genuine intelligence.
Chain-of-Thought: A Seed of True Reasoning
Embodied Multimodal Chain-of-Thought (EM-CoT) reasoning facilitates robotic task completion by breaking down high-level objectives into a series of manageable subgoals. This decomposition mirrors the human cognitive process of planning and problem-solving, where complex tasks are addressed through sequential subgoal achievement. Rather than directly mapping inputs to actions, EM-CoT encourages robots to internally represent intermediate steps, allowing for a more structured and flexible approach to task execution. The method supports handling tasks with multiple potential solution paths and enables adaptation to unforeseen circumstances by re-evaluating and adjusting the subgoal sequence as needed.
EM-CoT achieves robust and flexible robotic behavior by integrating three core predictive modules. Textual reasoning processes high-level task instructions and generates a plan consisting of sequential subgoals. Visual subgoal prediction then anticipates the expected visual outcome of achieving each subgoal, providing a perceptual expectation for successful completion. Finally, action prediction determines the appropriate robotic actions required to transition from the current state to the predicted subgoal state. This synergistic combination of textual planning, visual expectation, and action execution allows the robot to adapt to unforeseen circumstances and maintain task completion even with perceptual uncertainty or environmental changes.
Explicitly modeling the reasoning process within EM-CoT facilitates system transparency by providing a traceable sequence of subgoals and associated visual and action predictions. This detailed internal representation enables improved error recovery; when a failure occurs, the system can identify the point of divergence from the predicted trajectory and re-plan from that specific subgoal, rather than restarting the entire task. Furthermore, this explicit model allows for adaptation to novel situations; the system can analyze successful and unsuccessful reasoning paths to refine its predictive models and improve performance on future, similar tasks by adjusting the probabilities associated with each step in the chain-of-thought process.
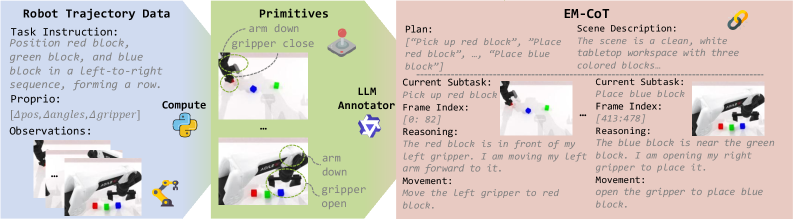
HALO: Unifying Perception, Language, and Action
HALO represents a new Vision-Language-Action (VLA) model designed for robotic manipulation tasks. Its core innovation lies in the implementation of EM-CoT (Evidence-based Multi-step Chain-of-Thought) reasoning, enabling the robot to break down complex tasks into a series of logically connected steps. This process involves first interpreting natural language instructions, then leveraging visual input to anticipate the consequences of potential actions, and finally selecting appropriate actions to achieve the desired goal. The model’s architecture is specifically designed to integrate these vision, language, and action modalities, allowing for more robust and adaptable robotic control compared to traditional approaches.
The HALO model employs a Mixture-of-Transformers (MoT) architecture to improve computational efficiency and overall performance in robotic manipulation tasks. This approach decouples the processing of textual input, visual scene understanding, and action prediction by assigning each to a specialized “expert” transformer network. Rather than a single, monolithic transformer handling all aspects of the VLA pipeline, MoT allows for parallelized processing and focused expertise, reducing the parameter count required for comparable performance. This modularity enables more efficient training and inference, as each expert can be optimized for its specific sub-task, leading to improved resource utilization and faster response times during robotic execution.
The HALO framework leverages pre-trained foundational models to enhance performance in vision-language-action tasks. Specifically, HALO employs Qwen2.5 for language understanding, enabling robust processing of textual instructions and queries. Visual encoding is handled by SigLIP2, a model designed to extract meaningful representations from visual inputs. Integrating these established models allows HALO to benefit from their existing capabilities, reducing the need for extensive task-specific training and improving overall system efficiency and accuracy in robotic manipulation scenarios.
Evaluations on the RoboTwin 2.0 benchmark demonstrate that HALO achieves a success rate of 80.46% when performing easy-level manipulation tasks. This performance represents a significant improvement over the baseline policy, denoted as π0, which achieved a success rate of 46.36%. The 34.1% increase in success rate indicates HALO’s superior capability in understanding task instructions, visually predicting outcomes, and executing effective robotic actions within the simulated environment. These results were obtained using a standardized evaluation protocol on the easy subset of the RoboTwin 2.0 dataset.
Within the HALO framework, a Variational Autoencoder (VAE) plays a critical role in facilitating visual generation and planning for robotic manipulation. The VAE learns a latent representation of visual states, enabling the model to predict future states given an action. This predictive capability is achieved by encoding observed images into a lower-dimensional latent space, allowing for efficient sampling and reconstruction of possible future visual outcomes. The VAE’s probabilistic nature allows HALO to explore multiple plausible futures, aiding in long-horizon planning and improving the robustness of action selection by accounting for inherent uncertainties in the environment and robot’s movements. The generated visual representations are then utilized by the action prediction component to select appropriate robotic actions.
The Seeds of Adaptability: Data and Real-World Validation
To facilitate the development of robust robotic intelligence, an automated data synthesis pipeline was implemented to create a large-scale, diverse training dataset for embodied multi-task compositional task (EM-CoT) learning. This pipeline operates by dissecting complex robot trajectories into fundamental subtasks, effectively breaking down intricate actions into manageable components. Crucially, each subtask is then meticulously aligned with the corresponding reasoning steps required for its successful execution, establishing a clear link between action and cognition. By systematically generating variations of these decomposed trajectories and their associated reasoning, the pipeline creates challenging and realistic scenarios that push the boundaries of robotic learning, ultimately enabling the development of more adaptable and intelligent systems capable of tackling complex, real-world tasks.
The creation of robust robotic systems necessitates extensive training data, and the approach utilizes Action Primitives to efficiently generate this data. These primitives function as building blocks, representing fundamental robot actions – such as grasping, moving, or rotating – in a standardized, parameterized format. By decomposing complex robot trajectories into sequences of these primitives, the system can systematically vary parameters and create a diverse range of scenarios for training. This structured representation allows for automated data synthesis, generating challenging yet realistic examples that go beyond simple recordings of human demonstrations, and ultimately improves the robot’s ability to generalize to new situations.
Rigorous validation of the HALO system was conducted utilizing the RoboTwin 2.0 simulation platform, demonstrating substantial performance gains over the established π0 baseline. On comparatively simple tasks, HALO achieved an impressive 80.46% success rate, exceeding the baseline by a significant 34.1%. Even when confronted with more complex and challenging scenarios, HALO maintained a 26.44% success rate – a noteworthy 10.1% improvement over the prior state-of-the-art. These results indicate HALO’s robust capabilities in robotic task completion and its potential for deployment in real-world applications requiring adaptable and reliable performance.
Evaluations conducted with physical robots demonstrate HALO’s robust capabilities across a spectrum of complex manipulation tasks. The system consistently achieved superior performance when compared to existing baseline policies in scenarios demanding intricate coordination, such as tool-mediated object handling, the precise alignment required for bimanual cup nesting, and tasks necessitating seamless inter-arm collaboration. Furthermore, HALO effectively tackled multi-step manipulation challenges, indicating a capacity for planning and executing sequences of actions with improved reliability. These real-world results highlight the system’s ability to translate learned reasoning skills into practical robotic control, suggesting a significant step towards more adaptable and versatile robotic systems.
To maximize its capabilities across a spectrum of robotic challenges, HALO utilizes a two-stage training process centered around pre-training and fine-tuning. Initially, the model undergoes extensive pre-training on a large, synthetically generated dataset, allowing it to learn generalizable representations of robotic actions and reasoning steps. This foundational knowledge is then refined through fine-tuning, where HALO is adapted to the specific nuances of individual tasks. By leveraging this transfer learning approach, the model efficiently acquires the skills necessary for successful execution in diverse scenarios, ranging from tool manipulation to complex bimanual coordination, and consistently demonstrates improved performance compared to policies trained from scratch. This targeted adaptation ensures HALO isn’t merely a generalist, but a highly proficient robotic problem-solver.
The pursuit of HALO, a unified Vision-Language-Action model, echoes a fundamental truth about complex systems. It isn’t about building intelligence, but cultivating an ecosystem where reasoning-embodied, multimodal, and chained-can emerge. This approach acknowledges that perfect prediction is an illusion; instead, it embraces the inevitability of ‘revelations’-unexpected scenarios that expose the limits of current understanding. As Carl Friedrich Gauss observed, “If other sciences had advanced as far as mathematics, we would not be so ignorant.” HALO doesn’t aim to eliminate uncertainty in robotic manipulation, but to build a system that learns from its encounters with the unknown, leveraging the embodied chain-of-thought process to navigate the inevitable gaps in its knowledge.
The Long Calculation
Halo, as a unified architecture, does not solve embodied reasoning. It relocates the difficulty. The system’s capacity for multimodal chain-of-thought suggests not an approach to general intelligence, but a more subtle problem: the inevitability of internal narratives. Every successful manipulation, every reasoned action, is predicated on a self-constructed mythology of the environment. The true metric will not be task completion, but the elegance – and the fragility – of these constructed worlds.
Current evaluations, focused on demonstrable action, treat the system’s internal state as a black box. Future work must acknowledge this state is the system. A model capable of articulating – or, more likely, confessing – the assumptions embedded within its reasoning process will be more valuable than one that simply executes tasks. The alerts will be revelations of inherent bias, of unexamined premises woven into the fabric of perception.
The pursuit of “out-of-distribution” generalization is a fool’s errand. Distribution is the universe. The only constant is the system’s inevitable encounter with the unforeseen. The real question is not whether Halo will fail, but how – and what patterns of internal collapse will precede each failure. If the system is silent, it is not resting – it is plotting a new, unforeseen mode of error.
Original article: https://arxiv.org/pdf/2602.21157.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Total Football free codes and how to redeem them (March 2026)
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
2026-02-26 01:26