Author: Denis Avetisyan
New research shows that combining vision and language processing can significantly enhance the accuracy of activity recognition during critical moments of newborn care.
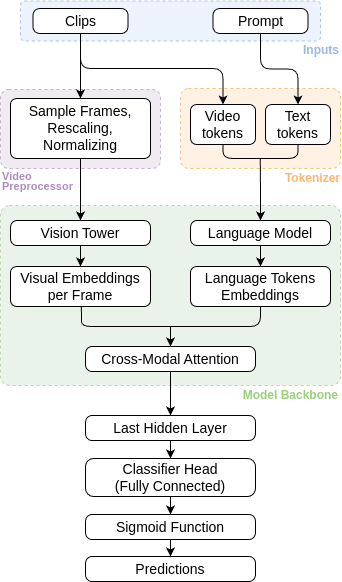
Fine-tuning a vision-language model with LoRA achieves state-of-the-art performance in recognizing fine-grained actions during newborn resuscitation, offering a privacy-preserving edge computing solution.
Accurate and automated analysis of complex procedural tasks remains a challenge despite advances in video understanding. This is explored in ‘Can Local Vision-Language Models improve Activity Recognition over Vision Transformers? — Case Study on Newborn Resuscitation’, which investigates the potential of localized vision-language models (VLMs) for recognizing fine-grained activities during newborn resuscitation. Results demonstrate that a fine-tuned LLaVA-NeXT Video model, optimized with a Low-Rank Adaptation (LoRA) classifier, achieves a state-of-the-art F1 score of 0.91-surpassing TimeSformer performance-and offers a pathway towards privacy-preserving, edge-based solutions. Could this approach unlock more robust and accessible automated assessment of critical medical procedures?
The Inevitable Mess of Newborn Resuscitation
Successful newborn resuscitation hinges on the swift and precise evaluation of an infant’s physiological state and the corresponding actions of the care team. Immediately following birth, a cascade of critical events demands continuous monitoring – assessing respiration, heart rate, and muscle tone are paramount. Delays or inaccuracies in these initial evaluations can significantly impact outcomes, potentially leading to avoidable morbidity or mortality. This assessment isn’t merely about recognizing distress; it’s a dynamic process requiring real-time interpretation of subtle cues to guide interventions, such as positive-pressure ventilation or chest compressions. Therefore, a robust system for timely and accurate appraisal is not simply desirable, but fundamentally essential for providing effective care during this vulnerable period.
Newborn resuscitation demands rapid and precise evaluations, yet manual assessments are inherently susceptible to inconsistencies and mistakes. The high-pressure environment of a delivery room significantly exacerbates these vulnerabilities; cognitive load and time constraints can lead to overlooked details or misinterpretations of infant status and caregiver actions. Studies demonstrate that even experienced clinicians exhibit variability in their assessments under stress, influencing critical decisions like the administration of positive pressure ventilation or chest compressions. This subjectivity isn’t necessarily indicative of incompetence, but rather a natural consequence of human cognitive limitations when faced with urgent, complex scenarios, underscoring the need for standardized, objective evaluation methods.
The potential for enhanced resuscitation outcomes hinges on the development and implementation of objective, automated assessment tools. Current neonatal resuscitation relies heavily on visual and auditory evaluation by caregivers, a process susceptible to inconsistencies and inaccuracies, especially under the duress of an emergency. Automated systems, utilizing sensors and algorithms to monitor vital signs and procedural adherence, offer a pathway to standardized, real-time feedback. Such tools not only improve the quality of care delivered to newborns but also revolutionize training methodologies. By providing precise, unbiased performance data, these systems allow healthcare professionals to identify areas for improvement and refine their skills in a safe, controlled environment, ultimately fostering greater competence and confidence in critical care scenarios.
ORAA-Net: A Layered Approach to Damage Control
The ORAA-Net framework generates a timeline of resuscitation events through a sequential process beginning with object detection to identify relevant actors and equipment within video footage. Following object detection, a region proposal stage narrows the focus to areas likely containing activity. Finally, activity recognition algorithms analyze these regions to classify specific actions performed during the resuscitation process. This combined approach allows ORAA-Net to move beyond simple object identification and create a temporally ordered log of events, providing a more complete understanding of the resuscitation scenario.
The ORAA-Net system employs a two-stage analysis process for object and action recognition. Initially, the YOLOv3 algorithm performs object detection, identifying potential relevant objects within the video frames. Subsequently, these identified regions are subjected to more detailed analysis using the i3D network, which captures spatio-temporal features, and optical flow estimation, which tracks motion patterns. This combination allows for a refined understanding of object interactions and actions, moving beyond simple object presence to inferring dynamic events occurring within the resuscitation video.
The multi-step activity recognition process employed by ORAA-Net addresses challenges inherent in complex video data by sequentially refining analysis. Initial broad object detection via YOLOv3 reduces the search space for subsequent steps, while the integration of i3D and optical flow provides detailed temporal and spatial information. This layered approach mitigates the impact of occlusion, varying lighting conditions, and camera motion, all common issues in resuscitation videos. By combining the strengths of multiple algorithms, the system achieves improved accuracy and resilience compared to single-stage methods, enabling reliable activity classification even in suboptimal recording environments.
The accurate identification of discrete actions within resuscitation videos, facilitated by ORAA-Net, enables the quantification of procedural performance. This detailed action recognition provides the necessary data for evaluating adherence to established resuscitation guidelines, such as those defined by the American Heart Association. Specifically, the system’s ability to detect and time-stamp events like chest compressions, defibrillation, and medication administration allows for objective measurement of key performance indicators – including compression rate, time to defibrillation, and adherence to drug delivery protocols. These metrics can then be used to generate automated performance reports, facilitating both individual and team training, and providing a basis for quality improvement initiatives in emergency medical care.
Vision-Language Models: Another Algorithm Walks Into a Hospital
Large Language Models (LLMs) and their multimodal counterparts, such as LLaVa, represent a significant advancement in artificial intelligence due to their capacity to process and integrate information from multiple data types. LLMs are trained on massive datasets of text, enabling them to generate human-quality text, translate languages, and answer questions in a comprehensive manner. Large Multimodal Models extend this capability by incorporating visual data, typically images or video, alongside textual input. This allows LMMs to not only understand the content of images but also to relate visual elements to corresponding textual descriptions, facilitating tasks requiring joint reasoning across modalities. The core architecture of these models typically involves transformer networks, which excel at capturing long-range dependencies within and between data streams, and attention mechanisms that allow the model to focus on the most relevant parts of the input when generating output.
The research explored the use of Large Multimodal Models (LMMs) for analyzing newborn resuscitation videos using zero-shot classification (ZSC) techniques. Three distinct ZSC approaches were evaluated: ZSC-CO, which utilizes a combined prompt of class names and visual features; ZS-B, employing a basic prompt focused on visual information; and ZSC-J, a more complex prompting strategy designed to improve contextual understanding. This methodology allows for activity classification without requiring pre-labeled training data, leveraging the LMM’s pre-existing knowledge to categorize actions observed in the resuscitation videos. Comparative analysis of these ZSC methods was performed to determine the most effective approach for initial performance assessment prior to fine-tuning.
To enhance performance on the newborn resuscitation video analysis task, several fine-tuning techniques were implemented. FT-LC utilizes a linear classification layer trained on top of the frozen LMM, providing a computationally efficient method for adaptation. FT-C-LoRA employs Low-Rank Adaptation (LoRA) alongside complete fine-tuning, reducing the number of trainable parameters while maintaining representational capacity. Specifically, LoRA introduces trainable low-rank matrices to approximate weight updates, significantly decreasing the memory footprint and computational cost associated with full parameter updates. Both FT-LC and FT-C-LoRA were evaluated to determine the optimal balance between performance gains and computational efficiency for this specialized medical application.
Evaluation of Large Multimodal Models (LMMs) for newborn resuscitation video analysis indicates a high degree of accuracy in classifying resuscitation activities with limited labeled data. The FT-C-LoRA fine-tuning technique achieved a macro-average F1 score of 0.91, representing a substantial performance improvement over the TimeSFormer baseline, which registered a macro-average F1 score of 0.7. This indicates that LMMs, when optimized with techniques like FT-C-LoRA, can effectively analyze resuscitation videos and identify key actions with a high degree of precision, even without large, manually annotated datasets.
Taking it to the Edge: Because Everything Ends Up There
The implementation of Large Multimodal Models (LMMs) directly on edge devices, facilitated by Edge-Based Visual Language Models (VLMs), represents a critical advancement in automated resuscitation training systems. This approach prioritizes patient data privacy by eliminating the need to transmit sensitive video data to cloud servers for processing. Real-time analysis becomes feasible as the entire assessment pipeline operates locally on the device, allowing for immediate feedback during training scenarios. This localized processing not only enhances data security but also overcomes limitations imposed by network latency or intermittent connectivity, making the system reliable and accessible even in challenging environments. The shift towards edge deployment signifies a move towards more robust, secure, and readily available automated healthcare training tools.
To effectively train and validate its automated assessment pipeline, the system leverages a carefully curated dataset of simulated resuscitation videos. These videos, depicting realistic medical emergency scenarios, are meticulously annotated using ELAN, a professional tool for multi-layered annotation of audio-visual data. This detailed annotation process allows for precise labeling of critical actions performed during resuscitation – such as chest compressions, ventilation, and defibrillation – providing the ‘ground truth’ necessary for evaluating the system’s accuracy. By training on this annotated data, the pipeline learns to reliably identify and classify these actions, ultimately enabling objective assessment of healthcare provider performance and facilitating targeted improvements in training protocols.
To rigorously assess the system’s ability to correctly identify resuscitation activities, researchers employed the Macro F1 Score as a primary metric. This score provides a balanced measure of both precision and recall across all classified actions, effectively quantifying the accuracy of the activity classification pipeline. Unlike simple accuracy, the Macro F1 Score accounts for potential imbalances in the dataset, ensuring that the performance isn’t skewed by disproportionately common activities. A high Macro F1 Score-in this case, 0.91-indicates the system reliably and consistently identifies each resuscitation step, providing a strong foundation for its use in automated training and performance evaluation of healthcare providers. This robust evaluation methodology confirms the system’s capability to provide dependable, objective feedback.
The automated resuscitation training system demonstrated a high degree of accuracy, achieving a macro-average F1 score of 0.91 – a notable advancement compared to existing methodologies. This performance indicates the system’s robust capability in correctly identifying and classifying resuscitation activities. Current development is directed toward expanding this technology into a complete, automated training platform intended for healthcare professionals. The envisioned platform will leverage the system’s accurate assessment capabilities to deliver individualized feedback, enabling targeted skill development and ultimately improving the quality of emergency care training. This personalized approach promises to address specific areas of weakness and optimize learning outcomes for trainees.
The pursuit of elegant architectures invariably collides with the messiness of deployment. This study, focused on newborn resuscitation and leveraging vision-language models, exemplifies that principle. Achieving state-of-the-art performance with LLaVA-NeXT Video and a LoRA adapter is a technical feat, yet it’s the practical implications – edge computing and privacy preservation – that truly define the work. As Yann LeCun once stated, “If it works in the lab, it’s a proof of concept. If it works in the real world, it’s a miracle.” The miracle here isn’t just recognition accuracy; it’s a system that functions without relying on constant cloud connectivity, a detail that will inevitably be tested by the unpredictable demands of a real-world clinical environment. Any system claiming self-sufficiency will eventually reveal its limitations; the team anticipates, and likely already catalogs, potential failure modes.
What’s Next?
The demonstrated efficacy of locally-executed vision-language models in a high-stakes scenario like newborn resuscitation is, predictably, not the finish line. The current architecture, while achieving state-of-the-art results, merely shifts the point of failure. The inevitable edge-case failures – the imperfect lighting, the obscured view, the novel procedural variation – will not be errors of recognition but of interpretation. The model will not fail to see an action, but to correctly categorize it within its training distribution. Every abstraction dies in production, and this one will be no different.
Future work will almost certainly focus on increasing robustness to these distribution shifts, likely through synthetic data generation or continual learning strategies. However, a more fundamental question remains: how does one quantify the cost of a misclassification in such a domain? Precision and recall become insufficient metrics when the consequences are measured in minutes, or even seconds.
Ultimately, the real challenge isn’t building a system that appears intelligent, but one that gracefully degrades when faced with the chaotic reality of a clinical setting. It is a temporary reprieve from cloud dependency, certainly, but every deployed system is merely accruing tech debt, waiting for the conditions that expose its limits. At least, it dies beautifully.
Original article: https://arxiv.org/pdf/2602.12002.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Invincible Creator on Why More Spin-offs Haven’t Happened Yet
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
2026-02-15 14:30