Author: Denis Avetisyan
Researchers have developed a powerful new AI that combines visual and textual data to accelerate discoveries in science and chemistry.

Innovator-VL is a multimodal large language model demonstrating data efficiency and improved scientific reasoning through transparent reinforcement learning.
Despite the increasing scale of large language models, achieving robust scientific reasoning often demands extensive domain-specific data and opaque training procedures. This work introduces ‘Innovator-VL: A Multimodal Large Language Model for Scientific Discovery’, which demonstrates competitive performance on diverse scientific benchmarks-including chemical structure recognition-with substantially reduced data requirements through a transparent and reproducible training pipeline. Innovator-VL achieves this data efficiency not by simply scaling model size, but through principled data selection and a unified architecture capable of both general visual understanding and scientific reasoning. Could this approach pave the way for more accessible and adaptable scientific AI systems, democratizing innovation across disciplines?
Unveiling Patterns: The Limitations of Isolated Scientific Data
Historically, scientific inquiry has frequently compartmentalized information, treating textual reports, visual data like microscopy images, and numerical datasets as separate entities for analysis. This isolation, while practical in some instances, fundamentally limits a complete understanding of complex phenomena; crucial connections and patterns existing between these modalities often remain obscured. For example, a researcher might analyze a graph detailing experimental results independently from the accompanying textual description of the methodology or the images documenting the observed process. This fragmented approach hinders the ability to formulate holistic hypotheses and can lead to incomplete or even misleading interpretations, ultimately slowing the pace of scientific discovery by preventing a truly integrated view of the evidence.
The core of scientific advancement lies in synthesizing information from varied sources, yet traditional analytical approaches frequently compartmentalize data into isolated modalities – text, images, and numerical datasets. Truly effective scientific reasoning necessitates a departure from this fragmented perspective; it demands models capable of not merely processing these diverse data types, but of actively integrating them and reasoning across their combined information. This integrative capacity is crucial because scientific phenomena are rarely, if ever, fully described by a single modality; a comprehensive understanding often emerges only when patterns are identified across multiple representations. Consequently, the ability to correlate textual descriptions with visual evidence and quantitative measurements is paramount for tasks ranging from hypothesis generation to experimental validation, and ultimately, for accelerating the pace of scientific discovery.
Despite remarkable advancements in natural language processing, current Large Language Models (LLMs) exhibit limitations when faced with the nuanced demands of scientific reasoning across multiple data types. While proficient at processing textual information, these models often struggle to reliably integrate and interpret data presented in visual or numerical formats – a critical shortcoming given that scientific understanding frequently relies on synthesizing information from diverse sources. Specifically, LLMs demonstrate inconsistent performance in tasks requiring the correlation of image-based observations with textual descriptions, or the application of numerical data to validate hypotheses articulated in language. This inability to consistently perform complex multimodal reasoning hinders their potential to accelerate scientific discovery, as genuine breakthroughs often necessitate the holistic interpretation of multifaceted datasets – a challenge that demands more than just linguistic proficiency.
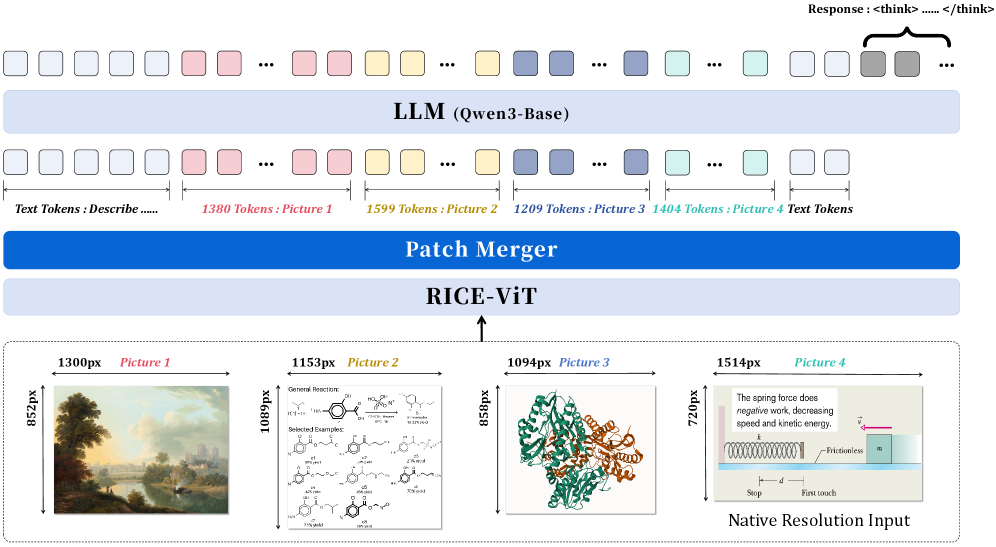
Innovator-VL-8B: A Foundation for Integrated Scientific Reasoning
Innovator-VL-8B is a large language model (LLM) designed for multimodal operation, accepting both visual and textual inputs to facilitate advanced reasoning capabilities within scientific contexts. This model distinguishes itself through its intent to move beyond simple pattern recognition and towards a deeper understanding of complex scientific data, supporting tasks such as hypothesis generation, data interpretation, and problem-solving. The architecture is specifically engineered to address the growing need for AI systems capable of integrating information from diverse sources, mirroring the interdisciplinary nature of modern scientific inquiry. Its development represents a step towards AI tools that can actively assist researchers in accelerating discovery across various scientific fields.
The Innovator-VL-8B model employs a two-part architecture for multimodal processing. Visual information is initially processed by RICE-ViT (Region-aware Image Captioning and Embedding Vision Transformer), which generates region-aware representations by identifying and encoding distinct areas within an image. These visual representations are then fed into Qwen3-8B-Base, a large language model serving as the decoder. Qwen3-8B-Base processes the encoded visual information alongside textual input, enabling the model to generate coherent and contextually relevant outputs that integrate both modalities. This combination facilitates reasoning and understanding across scientific data presented in both image and text formats.
The PatchMerger component within Innovator-VL-8B addresses computational demands by efficiently consolidating visual patches extracted by the RICE-ViT encoder. This process reduces the dimensionality of the visual representation, creating a more compact feature map for the language decoder. Specifically, PatchMerger aggregates information from multiple patches into fewer, higher-level representations, thereby decreasing the number of computations required during downstream processing. This reduction in computational load directly translates to faster processing speeds and lower memory requirements, enabling the model to handle complex visual inputs with improved efficiency and reduced resource consumption.
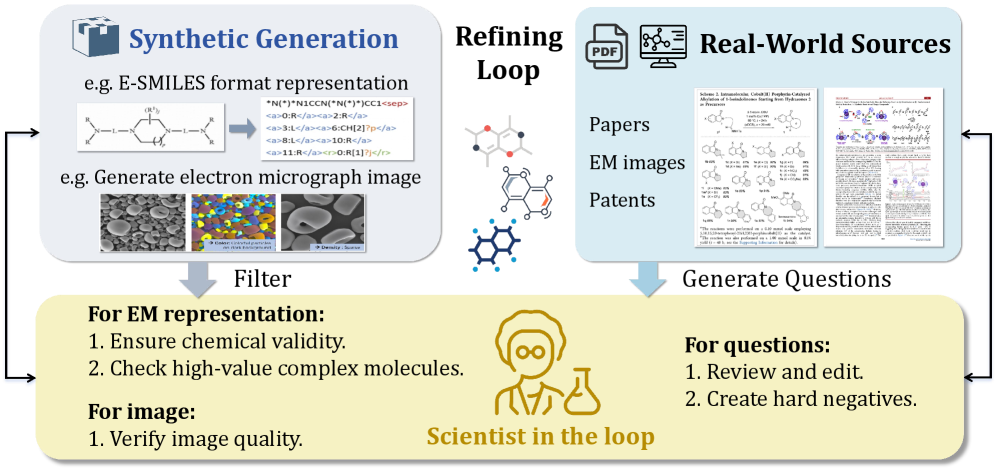
Cultivating Scientific Expertise: A Three-Stage Training Protocol
Mid-training involves exposing the model to a large-scale, multimodal corpus designed to instill a broad base of scientific knowledge. This corpus incorporates diverse data types, including text, images, and potentially other modalities, representing a wide range of scientific disciplines and concepts. The objective is to move beyond initial pre-training and proactively introduce the model to the breadth of information expected of a scientifically proficient system. This phase differs from subsequent fine-tuning stages by focusing on general knowledge acquisition rather than task-specific performance optimization, establishing a foundation for later specialization and complex reasoning.
Supervised Fine-Tuning (SFT) builds upon the foundational knowledge acquired during initial training by specializing the model for particular scientific applications. This process utilizes datasets composed of Extended SMILES (E-SMILES) strings, a standardized textual representation of molecular structures that includes information beyond basic connectivity, such as stereochemistry and ring systems. By training on these E-SMILES datasets, the model learns to accurately predict and generate chemical structures, enabling improved performance on tasks like molecular property prediction, reaction outcome forecasting, and de novo molecular design. The use of E-SMILES ensures consistent and unambiguous representation of chemical information, facilitating robust and reliable model training and evaluation.
Reinforcement Learning (RL) was implemented to enhance the model’s capacity for long-horizon reasoning, specifically through the use of a Discrepancy-Driven RL Dataset and Group Sequence Policy Optimization (GSPO). The Discrepancy-Driven RL Dataset consists of examples designed to reward the model for identifying inconsistencies or discrepancies within scientific data, encouraging more thorough analysis. GSPO is a policy optimization algorithm that improves sample efficiency by grouping similar states and actions, allowing for more effective learning of sequential decision-making processes. This combination facilitated the model’s ability to maintain coherence and accuracy over extended reasoning chains, surpassing the limitations of shorter-context approaches.
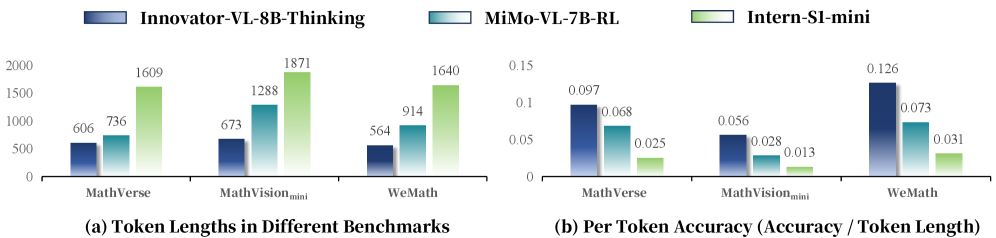
Unlocking Scientific Potential: Efficiency and Reasoning with Innovator-VL-8B
Innovator-VL-8B exhibits a marked advancement in multimodal reasoning capabilities, consistently outperforming prior models on complex scientific challenges. Evaluations across a diverse suite of benchmarks reveal an average score of 61.83%, indicating a substantial leap in its ability to integrate and interpret information from multiple data types-such as images, charts, and text-to arrive at scientifically sound conclusions. This enhanced reasoning isn’t limited to a single domain; the model demonstrates proficiency in areas ranging from chemistry and biology to physics and materials science, suggesting a broadly applicable intelligence capable of assisting researchers in a variety of disciplines. The consistently high scores underscore its potential to not only automate certain analytical processes, but also to generate novel hypotheses and accelerate the pace of scientific discovery.
Innovator-VL-8B distinguishes itself through a deliberate focus on token efficiency, a design choice that dramatically reduces computational demands without sacrificing performance. Traditional large language models often require extensive processing due to their massive size and the number of tokens – the basic units of text – they handle. This model, however, achieves strong results by maximizing the information extracted from each token, allowing it to perform complex scientific tasks with fewer computational resources. This efficiency isn’t merely about speed; it translates directly into reduced energy consumption and lower hardware costs, making advanced multimodal reasoning more accessible to a wider range of researchers and institutions. By prioritizing a leaner architecture, Innovator-VL-8B demonstrates that powerful AI doesn’t necessarily require massive scale, paving the way for sustainable and practical applications in scientific discovery.
Innovator-VL-8B represents a notable advancement in the pursuit of automated scientific discovery due to its unique synergy of capabilities. The model doesn’t simply process data; it effectively reasons with multimodal inputs – images, text, and potentially other data types – to arrive at conclusions relevant to complex scientific challenges. Crucially, this enhanced reasoning isn’t achieved at the expense of computational resources; instead, Innovator-VL-8B is designed for token efficiency, meaning it achieves strong performance using fewer processing steps. This combination unlocks the potential for broader accessibility and faster iteration in research, allowing scientists to explore hypotheses and analyze data with a powerful, yet pragmatic, artificial intelligence assistant. The resulting acceleration promises to reshape timelines in fields ranging from materials science to drug discovery, ultimately fostering a more rapid pace of innovation.

The development of Innovator-VL highlights a crucial aspect of modern AI research: the need to move beyond mere pattern recognition towards genuine scientific reasoning. As Yann LeCun aptly stated, “Everything we do in AI is about finding patterns.” This search for patterns is powerfully demonstrated in Innovator-VL’s ability to interpret complex scientific data, particularly chemical structures, and generate meaningful insights. The model’s data efficiency, achieved through careful training methodologies, further underscores the importance of avoiding spurious correlations – carefully checking data boundaries, as it were – to ensure the identified patterns represent true underlying relationships within the scientific domain. This focus on transparent training and robust reasoning capabilities is essential for building AI systems that can genuinely contribute to scientific discovery.
What Lies Ahead?
The emergence of Innovator-VL prompts a reconsideration of what constitutes ‘understanding’ within a large language model. The model’s proficiency in chemical structure recognition and scientific reasoning isn’t simply a matter of pattern matching, though that remains the fundamental mechanism. Rather, it highlights a curious echo of inductive reasoning – the system anticipates relationships based on observed correlations. The question isn’t whether it knows chemistry, but whether its predictive power is functionally equivalent, and where the limits of that equivalence lie.
Future work must move beyond benchmarks. Current evaluations largely assess performance on pre-defined tasks, effectively testing memorization and extrapolation within a constrained space. A more revealing test would involve presenting the model with genuinely novel scientific problems – those lacking sufficient training data – and observing not just the accuracy of its response, but the nature of its hypotheses. Does the system propose plausible, testable avenues for investigation, or simply recombine existing knowledge in increasingly complex arrangements?
Ultimately, the challenge isn’t building models that mimic scientific discovery, but understanding the very process of discovery itself. Innovator-VL, and its successors, may serve as a mirror, reflecting back our own cognitive biases and illuminating the subtle interplay between observation, inference, and the construction of scientific narratives. The data efficiency demonstrated here is promising, but the true metric of success won’t be speed or accuracy, but the capacity to surprise – to generate insights that even its creators did not anticipate.
Original article: https://arxiv.org/pdf/2601.19325.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Gold Rate Forecast
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
2026-01-28 17:24