Author: Denis Avetisyan
A new approach to search assistance keeps your data private by running powerful AI models entirely within your web browser.
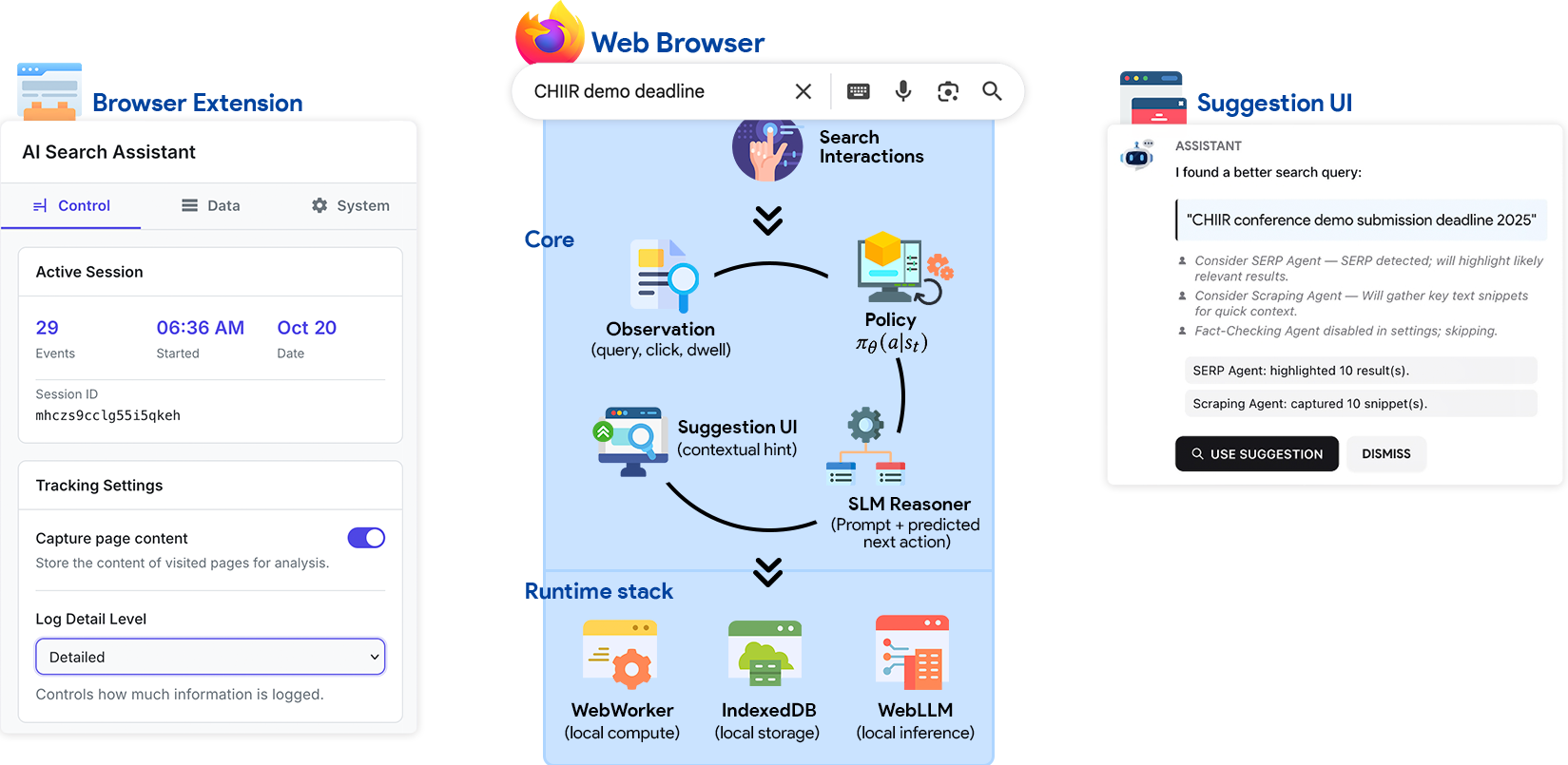
This review explores the design and implementation of client-side agents leveraging small language models and probabilistic user modeling for privacy-preserving personalized search.
The increasing demand for intelligent web search assistance clashes with growing user concerns about data privacy. This tension motivates the research presented in ‘In-Browser Agents for Search Assistance’, which introduces a fully client-side browser extension offering personalized search support without transmitting data to external servers. By combining adaptive user modeling with a small language model operating locally, this approach achieves significant improvements in search efficiency while preserving user control. Could this paradigm of in-browser, privacy-preserving AI unlock a new era of truly personalized and secure online experiences?
The Illusion of Search: Beyond Keyword Matching
Conventional search engines, while remarkably efficient at indexing vast quantities of information, frequently present users with a one-size-fits-all response, irrespective of their unique context or prior interests. This approach stems from a reliance on broad keyword matches and page ranking algorithms that prioritize popularity over personal relevance. Consequently, a query for “jaguar” might yield results concerning the car brand, the animal, or even the Jacksonville Jaguars football team – forcing the user to manually sift through irrelevant options. The limitations of these generic systems highlight a growing need for search technology that moves beyond simply finding documents containing specific terms, and instead anticipates the user’s intent and delivers tailored results aligned with their individual profile, search history, and evolving needs. This disconnect between generalized results and specific user expectations underscores the central challenge driving advancements in personalized search.
Truly effective search personalization transcends the limitations of keyword matching by striving to model the nuances of individual user intent and context. Modern approaches delve into behavioral signals – the patterns of past searches, dwell times on results, click-through rates, and even the sequence of queries – to infer underlying information needs. This goes beyond simply identifying what a user typed; it attempts to understand why they searched for it. Consequently, algorithms leverage techniques like collaborative filtering and machine learning to predict relevance based not just on the query itself, but also on the profiles of users with similar behaviors. The goal is to anticipate information needs and deliver results that align with a user’s evolving interests, even before those interests are explicitly stated in a search query, creating a more intuitive and efficient search experience.
The promise of tailored search experiences for millions necessitates overcoming substantial computational hurdles. Traditional methods of personalization, while effective for small user groups, quickly become impractical as scale increases. Each query requires not simply matching keywords, but assessing individual user profiles – encompassing past searches, browsing history, location, and even time of day – to predict relevance. This demands innovative algorithmic approaches, such as collaborative filtering and machine learning models, optimized for speed and efficiency. Researchers are actively exploring techniques like dimensionality reduction, caching strategies, and distributed computing frameworks to manage the massive datasets and complex calculations involved. The goal is to deliver personalized results in real-time, without compromising search speed or requiring prohibitive computational resources, ultimately making individualized information access a scalable reality.
Modeling the User: A Probability, Not a Profile
A Probabilistic User Model represents user preferences and predicts future actions by assigning probabilities to different potential behaviors, unlike static profiles which rely on fixed attributes. This model doesn’t define a user with concrete characteristics, but rather as a distribution of likely actions based on observed data. The probabilities are calculated and updated continuously through analysis of user interactions – such as clicks, purchases, or content consumption – allowing the system to adapt to evolving preferences. This approach allows for personalized recommendations and anticipatory system behavior, as the model predicts the likelihood of a user performing a specific action at a given time. The core benefit lies in its ability to handle uncertainty and represent the inherent variability in user behavior, resulting in more robust and accurate predictions than deterministic approaches.
The Probabilistic User Model utilizes Markov Decision Processes (MDPs) as its core structure, representing user behavior as a series of state transitions driven by actions and yielding rewards. This framework allows for the quantification of user preferences and prediction of future actions based on probabilities. The MDP is initially parameterized and then continuously refined through two primary data sources: historical user interaction data, used for offline training and model calibration, and real-time interaction data, which enables dynamic adaptation and immediate response to evolving user behavior. This iterative refinement process, incorporating both batch and streaming data, optimizes model parameters to improve prediction accuracy and personalize user experiences. The model’s state space represents user contexts, actions represent user interactions, and rewards quantify the desirability of those interactions, all learned from observed data.
Click models and Markov models enhance user intent representation by analyzing sequential user interactions. Click models statistically determine the probability of a user selecting a specific item from a set, based on factors like position and relevance. Markov models extend this by considering the probability of transitioning between different states – in this context, different actions or content consumed – based on previous states. Combining these approaches allows the system to predict future actions with increased accuracy by identifying patterns in user behavior and weighting recent interactions more heavily than distant ones. This probabilistic assessment of user intent is crucial for improving recommendation systems, search relevance, and personalized content delivery.
The Browser as a Nervous System: In-Browser Intelligence
The browser extension functions as the primary interface for deploying the personalized search functionality directly within the user’s web browser. This extension encapsulates the user model – a representation of the user’s search preferences and behavior – and the associated algorithms for tailoring search results. By executing these components locally, within the browser environment, the system avoids constant communication with a remote server for every search query. This architecture allows for real-time adaptation of search results based on the user model, without incurring network latency. The extension handles data input from user search activity, processes it using the locally-hosted algorithms, and dynamically modifies the displayed search results before they are presented to the user.
To optimize performance and scalability, the system leverages Web Workers for in-browser execution of the user model and search algorithms. Web Workers enable JavaScript code to run in the background, separate from the main browser thread, preventing blocking of the user interface and ensuring responsiveness during computationally intensive tasks. By processing data locally, this approach significantly reduces reliance on server-side processing, minimizing server load and associated latency. The resulting architecture facilitates rapid response times for personalized search results, as data does not require round-trip communication with a remote server for evaluation.
The system employs an adaptive policy to personalize search results through real-time adjustments informed by user interactions. This policy is trained using the REINFORCE algorithm, a model-free reinforcement learning method. REINFORCE operates by observing user actions – such as clicks, dwell time, and subsequent queries – following a search result presentation. These interactions are treated as rewards, and the algorithm adjusts the policy to increase the probability of presenting results that maximize these observed rewards. The result is a dynamic ranking of search results tailored to individual user behavior, without requiring pre-defined rules or explicit user profiles, and continuously refining its performance based on ongoing feedback.
IndexedDB is employed as the system for persistent storage of user behavioral data directly within the browser. This local database facilitates the accumulation of interaction logs – including search queries, click-through rates, and dwell times – without requiring constant server communication. The resulting dataset is used to continuously refine the user model and the adaptive search algorithms. Because IndexedDB stores data locally, the system avoids latency associated with network requests and enables the model to learn and improve its predictions over time, directly impacting the relevance of search results as the user interacts with the system.
The Illusion of Intelligence: Efficient Language Models
The pursuit of personalized results in language models doesn’t necessarily require massive computational resources. Recent advancements demonstrate that smaller models, exemplified by the Phi family, can achieve a compelling balance between performance and efficiency. These models, characterized by a focus on quality data and strategic architecture, prove surprisingly adept at understanding user intent and delivering relevant information. Unlike their larger counterparts, these compact models demand significantly less processing power and memory, making them ideally suited for deployment in resource-constrained environments, and opening doors to faster response times and wider accessibility. This shift towards efficient models represents a pragmatic approach to personalized information seeking, prioritizing practical implementation alongside high-quality results.
The efficient execution of small language models hinges on optimized hardware acceleration, and recent advancements utilize WebGPU to bring natural language processing directly into the browser. WebGPU, a modern graphics API, allows for parallel computation on the computer’s GPU, bypassing the need for constant communication with remote servers. This localized processing dramatically reduces latency when responding to user queries, as the model operates directly on the user’s machine. Consequently, complex natural language tasks, such as understanding user intent and retrieving personalized information, can be performed with remarkable speed and responsiveness, enhancing the user experience and minimizing reliance on network connectivity. This approach not only improves performance but also addresses privacy concerns by keeping data processing local.
LLM-Driven Information Seeking represents a shift in how users interact with data, employing large language models not merely as text generators, but as intelligent interpreters of need. This approach moves beyond simple keyword matching to genuinely understand the intent behind a query, allowing for the retrieval of information that is contextually relevant, even if it doesn’t contain the exact terms used. The system analyzes the nuances of language, deciphering what a user truly seeks, and then accesses information stores to deliver results that are not just factually correct, but also aligned with the user’s underlying goal. By focusing on semantic understanding, this method significantly enhances the precision and usefulness of information retrieval, offering a more intuitive and effective search experience.
Recent evaluations reveal substantial gains in personalized information retrieval through the implementation of an in-browser language model. Specifically, the study documented a 24.0% enhancement in next-action prediction accuracy when contrasted with established generic baseline models. This indicates a marked improvement in the model’s capacity to anticipate user needs and suggest relevant subsequent actions. Furthermore, the model achieved a Mean Reciprocal Rank (MRR) of 0.47, representing a 20.5% increase over comparative methods; this metric signifies a heightened ability to deliver highly relevant results at the very top of the search rankings, ultimately improving the user experience and efficiency of information seeking.
The System’s Reflection: Evaluating Usability and Performance
The browser extension’s usability underwent rigorous evaluation utilizing the System Usability Scale (SUS), a widely recognized method for assessing perceived ease of use. The resulting score of 82.5 signifies an excellent rating, demonstrating a high degree of user satisfaction and intuitiveness. This outcome suggests that users readily adapted to the extension’s interface and functionalities without significant difficulty, indicating successful design choices and a smooth user experience. Such positive feedback is crucial, as usability directly impacts user engagement and the overall effectiveness of the personalized search system.
The architecture leverages a confluence of techniques to move beyond conventional search paradigms. User modeling establishes a dynamic profile of individual information needs and preferences, while in-browser computation allows for immediate processing of search queries and personalization without reliance on remote servers. Crucially, this is coupled with the deployment of efficient language models, carefully optimized to balance accuracy with computational cost. This integrated approach doesn’t simply retrieve relevant documents; it proactively tailors the search experience to each user, presenting information in a manner uniquely suited to their established profile and current context, ultimately showcasing a viable route to genuinely personalized search functionality.
Analysis revealed a substantial improvement in search efficiency with the implemented system. Users completed searches requiring, on average, only 5.2 queries, a marked decrease from the 6.8 queries typically needed prior to the system’s integration. This reduction represents a statistically significant shift, suggesting the personalized approach effectively streamlines the information-seeking process. By anticipating user needs and refining results with each interaction, the system demonstrably minimizes the cognitive load and time investment associated with locating relevant information, fostering a more efficient and satisfying search experience.
Continued development centers on refining the system’s understanding of individual user needs and preferences. This involves broadening the scope of user modeling beyond current parameters, potentially incorporating behavioral data and long-term search histories to create more nuanced user profiles. Simultaneously, researchers are investigating more sophisticated adaptive policies – algorithms that dynamically adjust search results and recommendations based on evolving user behavior and feedback. The aim is to move beyond simple personalization towards a truly anticipatory system, proactively delivering information tailored to each user’s immediate and future needs, ultimately enhancing search efficiency and user satisfaction.
The pursuit of localized, client-side intelligence, as demonstrated in this work, echoes a fundamental truth about complex systems. It’s not about imposing order, but enabling adaptation. This research, focused on in-browser agents and privacy-preserving AI, suggests a path where personalization doesn’t necessitate centralized control. As John von Neumann observed, “There is no possibility of absolute knowledge.” This aligns with the paper’s core idea of adaptive user modeling; the system doesn’t know the user perfectly, but probabilistically learns and adjusts, accepting inherent uncertainty and building resilience through forgiveness between components. The garden grows not by blueprint, but by careful tending and allowing for emergent properties.
What’s Next?
The pursuit of client-side intelligence, as demonstrated by this work, isn’t a destination so much as a shifting of burdens. It trades reliance on distant servers for reliance on the evolving capabilities – and limitations – of the browser itself. Every architectural choice promises freedom from data exfiltration until it demands increasingly complex resource management and a constant negotiation with the browser’s own internal constraints. The true cost isn’t merely computational, but the inevitable drift between intended personalization and accidental echo chambers, built from the incomplete signals available locally.
Future iterations will undoubtedly focus on refining these probabilistic user models, striving for accuracy without sacrificing the very privacy they aim to protect. However, the fundamental tension remains: every model is a simplification, and every personalization narrows the scope of serendipity. The challenge isn’t simply to build a better assistant, but to accept that any such system will always be a flawed reflection of the user, amplifying some preferences while obscuring others.
Order, in this context, is merely a temporary cache between failures. The long game isn’t about achieving perfect personalization, but about building systems that gracefully degrade, allowing users to reclaim agency when the assistant’s predictions inevitably miss the mark. The real innovation won’t be in the algorithms themselves, but in the interfaces that empower users to understand – and override – the assistant’s internal logic.
Original article: https://arxiv.org/pdf/2601.09928.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- How to find the Roaming Oak Tree in Heartopia
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- ATHENA: Blood Twins Hero Tier List
- Sunday City: Life RolePlay redeem codes and how to use them (November 2025)
- How To Watch Tell Me Lies Season 3 Online And Stream The Hit Hulu Drama From Anywhere
2026-01-16 22:39