Author: Denis Avetisyan
A new framework bridges the gap between natural language and robotic action, allowing robots to perform complex tasks based on spoken instructions.
Language Movement Primitives combine vision-language models with dynamic movement primitives for improved robot manipulation and task decomposition.
Despite advances in robotic problem-solving, bridging the semantic gap between high-level task instructions and low-level motor control remains a central challenge. This work, ‘Language Movement Primitives: Grounding Language Models in Robot Motion’, introduces a framework that grounds vision-language model reasoning directly in the parameterization of dynamic movement primitives, enabling robots to interpret natural language and execute complex tabletop manipulations. By leveraging the interpretable parameters of DMPs, we demonstrate that large language models can effectively specify diverse and stable trajectories for zero-shot robot manipulation. Could this neuro-symbolic approach unlock a new era of intuitive and adaptable robotic assistants?
The Inherent Limitations of Embodied Intelligence
Conventional robotic systems frequently encounter difficulties when operating in real-world settings characterized by unpredictability and a lack of pre-defined structure. These limitations stem from a reliance on low-level control-precisely dictating motor movements-without possessing an overarching comprehension of the environment or the objects within it. Consequently, robots often fail to generalize beyond highly controlled scenarios, struggling with tasks that require adaptability, problem-solving, or the interpretation of ambiguous situations. This deficiency in high-level understanding hinders a robot’s ability to effectively navigate cluttered spaces, manipulate diverse objects, or respond intelligently to unexpected changes, ultimately restricting its practical application in complex, unstructured environments.
For robots to truly interact with the physical world, skillful movement is insufficient; a deeper comprehension of what is being manipulated and why is crucial. Effective manipulation necessitates semantic reasoning – the ability to understand objects not just as shapes and sizes, but as entities with properties and functions, and to infer the likely consequences of actions upon them. This involves processing information about an object’s affordances – what it enables the robot to do – and integrating that knowledge with the intended goal. Consider a simple task like setting a table: a robot equipped with semantic reasoning doesn’t merely move a cylindrical object from point A to point B; it identifies the object as a “cup,” understands its purpose for holding liquids, and places it appropriately near a plate and cutlery, anticipating the needs of a diner. Without this level of understanding, robotic actions remain brittle and easily disrupted by the inherent complexities of real-world environments.
Despite advancements in natural language processing and robotics, reliably converting human instructions into robotic action remains a significant challenge. Existing systems frequently stumble over ambiguity inherent in everyday language, struggling to discern the intended meaning beyond the literal words. A robot presented with “Bring me the apple from the kitchen” may fail if multiple apples are present, or if the kitchen contains obstructions – nuances easily understood by humans but difficult for algorithms to process. Furthermore, these systems often lack the ‘common sense’ knowledge necessary to infer unstated assumptions – for example, understanding that an apple should be grasped gently, not squeezed tightly. Consequently, current approaches typically require highly constrained vocabularies, simplified instructions, or extensive pre-programming, limiting a robot’s adaptability and hindering truly intuitive human-robot interaction.

Vision-Language Models: A Necessary Foundation for Intelligent Action
Vision-Language Models (VLMs) establish a critical interface between robotic perception and action by jointly embedding visual and linguistic data into a shared representational space. This allows robots to process both visual input from cameras and natural language commands from users, enabling them to understand instructions referencing objects and actions within the visual scene. Specifically, VLMs utilize architectures, often based on transformers, to learn correlations between image features and textual descriptions, facilitating tasks such as visual grounding – identifying objects mentioned in language – and generating appropriate actions based on the combined understanding of visual context and linguistic intent. The ability to connect these modalities is fundamental for creating robots capable of complex, human-guided operation in unstructured environments.
Recent advancements in vision-language models (VLMs) are exemplified by RT-2 and Pi-0.5, which demonstrate the capability of robotic systems to translate natural language instructions into actionable plans. RT-2, utilizing a “large language model as a robotic brain,” achieves zero-shot task execution by grounding language in visual inputs, enabling it to perform tasks without specific training examples for each new scenario. Similarly, Pi-0.5 leverages a similar architecture to achieve robust performance in both simulation and real-world environments, successfully completing complex multi-step instructions. These models achieve this functionality by combining visual encoders, which process image data, with large language models that interpret language and generate task sequences, effectively bridging the gap between human instruction and robotic action.
Open-Vocabulary Classifiers extend the functionality of Vision-Language Models (VLMs) by decoupling object recognition from the limitations of pre-defined training categories. Traditional VLMs require explicit training data for each object they are expected to identify. In contrast, open-vocabulary classifiers utilize techniques like contrastive learning and CLIP (Contrastive Language-Image Pre-training) to establish a shared embedding space between visual and textual data. This allows the VLM to recognize objects described in natural language, even if those objects were not present in the original training dataset. The classifier achieves this by comparing the visual features of an observed object to the textual embedding of a descriptive phrase, enabling zero-shot transfer to novel object recognition tasks without requiring additional training examples.
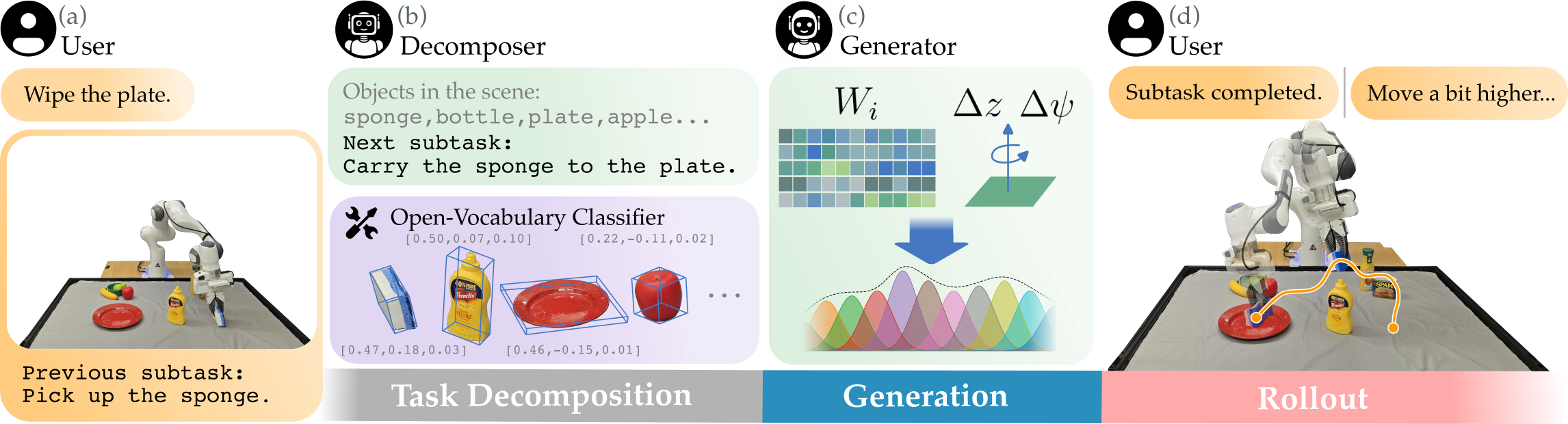
Language Movement Primitives: A Framework for Actionable Understanding
Language Movement Primitives (LMPs) represent a novel framework that integrates Vision-Language Models (VLMs) with Dynamic Movement Primitives (DMPs) to facilitate robotic task execution. VLMs provide the capability to interpret natural language instructions, translating them into high-level task specifications. These specifications are then processed by DMPs, a motion planning technique that generates smooth, dynamically feasible trajectories for robotic manipulators. By combining these two technologies, LMPs enable robots to understand and execute complex tasks defined through language, leveraging the perceptual abilities of VLMs and the precise control offered by DMPs. This approach contrasts with traditional robotic programming, which often requires explicit, low-level specification of movements.
Task Decomposition, as implemented within Language Movement Primitives (LMPs), involves breaking down a complex, language-directed task into a series of simpler, sequential actions. This process allows a robot to interpret natural language instructions and translate them into a feasible plan of movement primitives. Each primitive represents a specific, achievable action – such as grasping, lifting, or placing – and is executed in order. By structuring tasks in this modular fashion, LMPs facilitate the execution of multi-step manipulations, enabling robots to perform intricate procedures described through language input without requiring pre-programmed sequences for each specific task.
Evaluations conducted on a suite of 20 tabletop manipulation tasks yielded an 80% success rate when utilizing Language Movement Primitives. This performance represents a substantial improvement over existing state-of-the-art baseline methods, which achieved success rates ranging from 30% to 31% on the same task set. The quantitative results demonstrate the efficacy of the proposed framework in complex manipulation scenarios and highlight its ability to reliably execute a diverse range of actions specified through natural language instructions.
Zero-shot generalization, facilitated by the integration of Language Movement Primitives (LMPs), enables robotic task completion without requiring task-specific training data. This capability is achieved by leveraging the learned relationships between language instructions and fundamental movement patterns. The system effectively composes these pre-learned primitives to address novel tasks described through natural language, avoiding the need for extensive re-training or fine-tuning for each new objective. This approach contrasts with traditional robotic systems which typically require dedicated training datasets for each task, and allows for increased adaptability and deployment flexibility in dynamic or unpredictable environments.
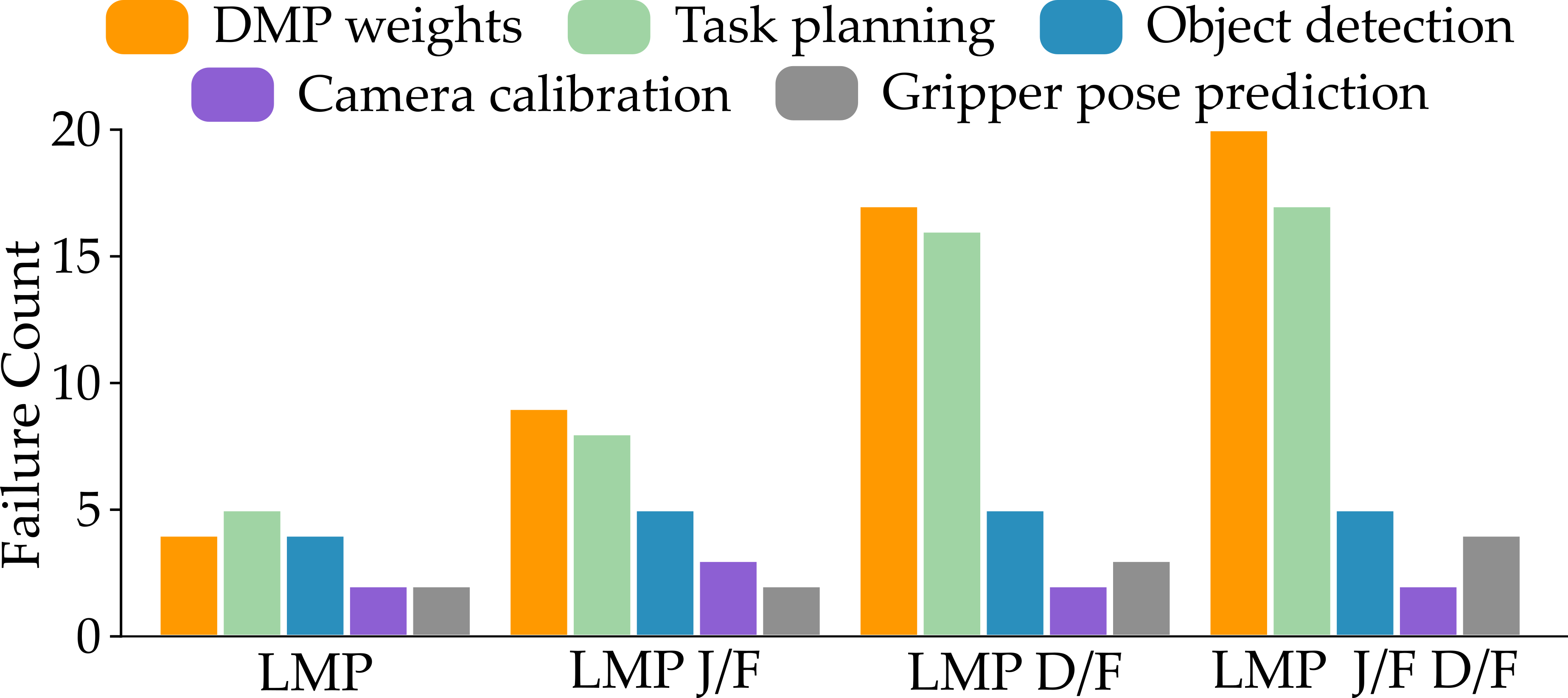
The Importance of Rigorous Failure Analysis for Robust Robotic Systems
A systematic approach to failure analysis proves indispensable for elevating robotic performance. Identifying the root causes of malfunctions – whether stemming from sensor inaccuracies, actuator limitations, or algorithmic flaws – allows engineers to pinpoint vulnerabilities within a system. This process isn’t merely about correcting errors; it’s a pathway to proactive refinement. By meticulously documenting and analyzing failure modes, developers can implement targeted improvements, bolstering a robot’s resilience and adaptability. Such analysis informs design modifications, strengthens control algorithms, and ultimately leads to more reliable and efficient robotic operation across diverse and unpredictable environments. The insights gained translate directly into enhanced robustness and a reduction in unexpected downtime, ensuring consistent performance even under challenging conditions.
Robot trajectory generation, the process of planning a path for a robot to follow, benefits significantly from advanced techniques like Latent Motion Primitives (LMPs). These LMPs allow robots to learn and reuse common movement patterns, resulting in smoother, more natural motions and increased efficiency. Unlike traditional methods that often produce jerky or inefficient paths, LMPs represent movements as points in a lower-dimensional space, enabling the robot to adapt quickly to changing circumstances and generate complex actions from a relatively small set of learned components. This approach not only reduces computational demands but also improves the robot’s ability to navigate dynamic environments and perform tasks with greater precision and fluidity – effectively bridging the gap between pre-programmed actions and real-world adaptability.
Robotic systems are increasingly designed to learn and adapt through interactions described in everyday language. This capability, leveraging natural language feedback, allows robots to iteratively refine their actions without explicit reprogramming. Instead of relying on pre-defined parameters, a robot can receive guidance such as “move slightly to the left” or “grasp the object more gently”, and integrate this feedback into its ongoing performance. This approach is particularly valuable in dynamic or unpredictable environments where pre-programmed routines may prove insufficient, enabling robots to tailor their behavior to specific user preferences and unforeseen circumstances. Consequently, robots become more versatile and user-friendly, moving beyond rigid automation towards true collaborative assistance.
Systematic evaluation reveals the critical roles of both judgement and task decomposition in achieving reliable robotic performance. Experiments demonstrate a significant decline in success rates when these components are removed from the operational framework; specifically, eliminating the judge results in a 31% reduction, bringing the success rate to 69%, while the absence of the task decomposer proves even more detrimental, dropping performance to just 46%. Complete removal of both elements yields a remarkably low success rate of 27%, underscoring their combined necessity for robust operation and highlighting that effective robotic systems require not only action execution, but also careful evaluation of outcomes and a structured approach to breaking down complex objectives into manageable steps.
Toward Scalable Intelligence: The Future of Robot Learning
The emergence of robotics foundation models represents a significant shift towards more versatile and adaptable robots. Inspired by large language models, these models are trained on massive datasets of robotic data – encompassing visual inputs, motor commands, and sensor readings – allowing robots to generalize to new tasks with minimal task-specific training. Rather than being programmed for a single purpose, a robot leveraging a foundation model can rapidly acquire new skills, such as manipulating unfamiliar objects or navigating previously unseen environments, through a process akin to “in-context learning.” This approach dramatically reduces the time and resources required to deploy robots in diverse real-world applications, promising a future where robots are not specialized tools, but broadly capable assistants capable of handling a wide spectrum of challenges.
Neuro-symbolic approaches represent a significant advancement in robot intelligence by strategically integrating the capabilities of neural networks and symbolic reasoning. Neural networks excel at perception and pattern recognition – tasks like identifying objects or navigating visually complex spaces – but often lack the capacity for abstract thought or logical deduction. Conversely, symbolic reasoning provides robots with the ability to manipulate knowledge, plan sequences of actions, and generalize from limited data, yet struggles with noisy or incomplete sensory input. By combining these strengths, neuro-symbolic systems enable robots to not only see and react to their environment, but also to understand it, reason about potential outcomes, and adapt their behavior accordingly. This fusion allows for more robust, explainable, and efficient robot control, particularly in dynamic and unpredictable real-world scenarios where pre-programmed responses are insufficient.
The pursuit of truly autonomous robotics hinges on sustained innovation in several key areas, ultimately aiming to bridge the gap between controlled laboratory settings and the unpredictable nature of real-world environments. Current research focuses on bolstering a robot’s ability to perceive, plan, and act effectively even when confronted with incomplete information, dynamic obstacles, and previously unseen scenarios. This involves developing more robust algorithms for sensor data interpretation, advanced motion planning techniques capable of navigating cluttered spaces, and adaptive control systems that can compensate for disturbances and uncertainties. Success in these endeavors will not only expand the range of tasks robots can perform independently – from search and rescue operations to in-home assistance – but also foster increased trust and reliability in their performance, paving the way for seamless integration into human-centric environments and unlocking the full potential of robotic automation.
The pursuit of robust robotic systems, as demonstrated by Language Movement Primitives, necessitates a commitment to verifiable results. Robert Tarjan aptly stated, “The most valuable skill a programmer can acquire is the ability to understand and articulate the problem being solved.” This echoes the article’s emphasis on task decomposition and grounding language instructions in executable robot motions. Just as a mathematically sound algorithm demands rigorous proof, the success of LMPs hinges on the ability to translate natural language into a deterministic sequence of actions – a sequence that can be reliably reproduced and verified against desired outcomes. The framework’s strength lies in its capacity to bridge the gap between linguistic intent and physical execution, ensuring that each step is logically sound and demonstrably correct.
What Lies Ahead?
The present work, while demonstrating a functional integration of linguistic parsing and motor control, merely scratches the surface of a deeper, more fundamental challenge. The demonstrated success relies, implicitly, on a conveniently constrained environment – tabletop manipulation. Scaling this approach requires a move beyond such artificial simplicity. The true test will be generalization: can this framework gracefully handle the inherent ambiguities of real-world instructions and the chaotic nature of unstructured environments? Current methods, elegantly bridging vision and action, still falter when confronted with unforeseen circumstances – a persistent indictment of purely data-driven solutions.
A critical, often overlooked, aspect concerns the provability of the learned policies. Demonstrating that a robot can execute a task is insufficient; one must prove, mathematically, that the chosen trajectory is optimal – or at least, demonstrably safe. The current reliance on neural networks, while achieving impressive empirical results, provides no such guarantee. Future research must explore hybrid neuro-symbolic approaches that integrate the strengths of both paradigms – the adaptability of neural networks with the rigor of formal verification.
Ultimately, the pursuit of truly intelligent robotics necessitates a shift in focus. The goal should not be to merely mimic human behavior, but to create systems capable of genuine understanding and reasoning. Language, in this context, is not simply a means of issuing commands, but a tool for constructing a shared model of the world. Until robotic systems can demonstrate such cognitive depth, they will remain, at best, sophisticated automatons – elegantly programmed, but fundamentally lacking in true intelligence.
Original article: https://arxiv.org/pdf/2602.02839.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
2026-02-04 15:57