Author: Denis Avetisyan
A new approach combines the strengths of neural networks and symbolic reasoning to allow robots to overcome obstacles and learn in real-world, unpredictable environments.
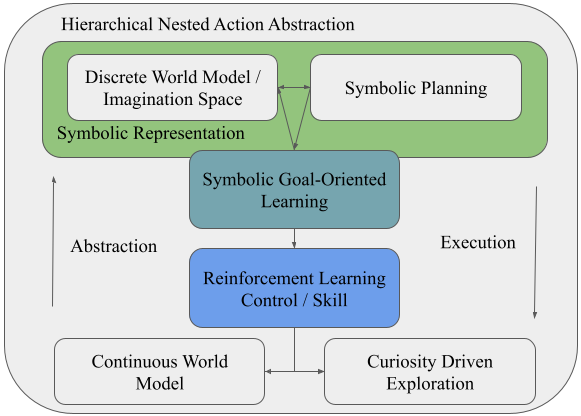
This work presents a neuro-symbolic framework leveraging hierarchical learning, curiosity-driven exploration, and action abstraction for robust robot adaptation in open-world settings.
Autonomous systems struggle to adapt to the unforeseen complexities of real-world environments, creating a persistent bottleneck in robotics research. This challenge is addressed in ‘Breaking Task Impasses Quickly: Adaptive Neuro-Symbolic Learning for Open-World Robotics’, which introduces a novel framework integrating hierarchical abstractions, symbolic planning, and reinforcement learning. The resulting architecture demonstrably accelerates adaptation through a combination of goal-oriented learning and curiosity-driven exploration, achieving improved sample efficiency and robustness. Could this neuro-symbolic approach unlock truly generalized robotic intelligence capable of thriving in dynamic, open-world scenarios?
The Inherent Fragility of Conventional Robotic Systems
Conventional robotic systems often falter when confronted with the inherent unpredictability of real-world environments. These robots are typically designed for static or narrowly defined scenarios, relying on precise models and pre-programmed sequences of actions. However, dynamic environments-those characterized by moving obstacles, changing lighting, or unexpected events-present a significant challenge to this approach. The rigidity of these systems stems from their limited capacity to perceive and react to deviations from anticipated conditions; even minor alterations can disrupt carefully calibrated movements and lead to failures in task completion. This lack of adaptability hinders their deployment in complex settings like homes, hospitals, or disaster zones, where unforeseen circumstances are commonplace and require a degree of flexibility beyond the capabilities of many existing robotic platforms.
Robotic systems historically built upon meticulously pre-programmed behaviors often exhibit a significant vulnerability when encountering unforeseen circumstances. This ‘brittleness’ stems from a limited capacity to generalize beyond explicitly defined parameters; a robot designed for a static environment may falter when presented with even minor deviations, such as an unexpected obstacle or altered lighting. Consequently, these systems struggle with ‘novelty’ – any situation outside of their training data – and demonstrate a lack of robustness in dynamic, real-world scenarios. The reliance on fixed sequences of actions hinders their ability to adapt, making them susceptible to failure when faced with the inherent unpredictability of complex environments and necessitating the development of more flexible and adaptive planning strategies.
Truly robust robotic planning transcends simple reactive behaviors, demanding agents that actively forecast potential environmental changes and preemptively modify their strategies. This proactive approach necessitates the development of algorithms capable of building internal models – not just of the static world, but of how that world is likely to evolve. Such systems integrate predictive modeling with continuous replanning, allowing a robot to simulate possible future states and select actions that optimize outcomes across a range of scenarios. Instead of solely responding to immediate stimuli, the agent anticipates consequences, mitigates risks, and capitalizes on opportunities – a crucial distinction for deployment in complex, real-world environments where unpredictability is the norm and successful operation hinges on foresight, not just reaction time.
A Synthesis of Symbolic Reasoning and Learned Adaptation
A hybrid approach integrating symbolic planning and reinforcement learning addresses limitations inherent in each method when applied in isolation. Symbolic planning excels at high-level reasoning and task decomposition, but struggles with the complexities of real-world state spaces and imprecise actions. Reinforcement learning, conversely, effectively handles these complexities through trial-and-error, but often requires extensive training and lacks the capacity for abstract reasoning or long-term planning. Combining these approaches allows agents to leverage symbolic representations for efficient goal specification and task structuring, while utilizing reinforcement learning algorithms to refine low-level control policies and adapt to dynamic environments. This synergy results in systems exhibiting both robust performance and improved sample efficiency compared to implementations relying on a single paradigm.
Combining symbolic representations with reinforcement learning allows agents to partition problem-solving into discrete levels of abstraction. Symbolic reasoning facilitates high-level planning and decision-making by operating on abstract concepts and pre-defined knowledge, enabling efficient exploration of the solution space and generalization to novel situations. Reinforcement learning then manages low-level control and execution, handling the complexities of the environment and optimizing actions through trial and error. This division of labor results in increased efficiency as the symbolic component reduces the dimensionality of the state space for the reinforcement learning algorithm, and improved robustness by allowing the agent to leverage prior knowledge and adapt to unforeseen circumstances more effectively than either approach could independently.
Symbolic Goal-Oriented Learning and Hierarchical Action Abstraction are task structuring methods designed to improve both the speed and adaptability of reinforcement learning agents. Symbolic Goal-Oriented Learning decomposes a complex task into a sequence of sub-goals represented symbolically, allowing the agent to learn relationships between actions and high-level objectives. Hierarchical Action Abstraction builds upon this by defining actions at multiple levels of granularity; lower levels execute primitive actions while higher levels select sequences of lower-level actions, effectively creating options for the agent. This hierarchical structure reduces the state and action spaces encountered during learning, accelerating convergence and enabling the agent to generalize learned behaviors to novel situations or variations in task parameters by composing existing sub-policies.
Empirical Validation Through Integrated Frameworks and Exploration
The Integrated Planning Task Framework is designed as a unified platform to assess the performance of combined methodologies in robotic task planning. This framework facilitates systematic testing by providing a standardized environment for implementing and comparing different approaches – including those leveraging curiosity-driven exploration and intrinsic rewards. It centralizes key components such as simulation environments, task definitions, and evaluation metrics, allowing researchers to isolate variables and accurately measure the effectiveness of novel planning algorithms. The framework supports integration with simulation tools like RoboSuite and CARLA, enabling scalable and reproducible experimentation across diverse robotic scenarios, such as pick and place tasks, and providing quantifiable results like the reported 80% success rate.
Curiosity-driven exploration utilizes intrinsic rewards to motivate agents to actively seek out and learn from novel experiences within their environment. Unlike traditional reinforcement learning which relies on external rewards, intrinsic rewards are generated internally by the agent based on the novelty or unpredictability of its experiences. This encourages the agent to explore states and actions it wouldn’t otherwise encounter, leading to improved adaptability and generalization capabilities, particularly in complex or sparse-reward environments. The agent is effectively rewarded for reducing its uncertainty about the environment, fostering a continuous learning process independent of specific task goals.
The testing framework leverages simulation environments RoboSuite and CARLA to enable systematic evaluation of combined methods, specifically on the ‘Pick and Place Task’ and related scenarios. Rigorous testing within these platforms yielded an 80% success rate, indicating the framework’s capability to consistently achieve task completion. These platforms provide repeatable and controlled conditions for performance analysis, facilitating iterative development and comparative assessments of different algorithmic approaches.
Demonstrable Advancement and the Trajectory of Intelligent Systems
Rigorous testing reveals that the integration of these hybrid techniques demonstrably elevates performance in complex scenarios. The proposed framework consistently surpasses established baseline models, achieving superior results in thirteen out of fifteen tested situations. This improvement isn’t merely qualitative; quantitative analysis confirms a significant reduction in the time required for the system to reach a stable solution – the ‘Convergence Time’ – alongside a notable increase in the ‘Success Rate’ of task completion. These empirical findings suggest a substantial leap forward in the efficiency and reliability of the developed system, positioning it as a promising solution for challenging real-world applications requiring robust and adaptive performance.
A predictive world model fundamentally alters an agent’s capacity for effective planning. Rather than reacting solely to immediate sensory input, the system constructs an internal representation of the environment, enabling it to simulate potential future states. This allows for the evaluation of different action sequences before they are executed in the real world, a process akin to mental rehearsal. By anticipating the consequences of its choices, the agent can proactively select strategies that maximize success and minimize risk, significantly improving its ability to navigate complex scenarios and achieve long-term goals. This internal predictive capability moves the agent beyond simple reactive behavior towards a more sophisticated form of proactive, goal-directed action.
The framework’s efficiency is significantly boosted through the implementation of Hindsight Experience Replay, a technique allowing agents to learn more effectively from a limited number of experiences. In simulations using the ‘CARLA’ driving environment, the system reached its maximum training step limit after just 22,000,000 steps – a testament to its rapid learning capability. This approach delivered substantial improvements in training speed, achieving a 54% reduction in the time required for agents to reach proficiency, and concurrently improved overall performance by an average of 20%. By reinterpreting past experiences as successes, even when the initial outcome differed from the goal, the system maximizes the value of each training iteration and accelerates the learning process.
The presented work champions a system where robotic problem-solving isn’t merely about achieving results, but about constructing solutions founded on logical completeness. This pursuit mirrors the ideals of formal verification; the framework’s integration of symbolic planning and hierarchical abstraction ensures a level of transparency and provability often absent in purely data-driven approaches. As Edsger W. Dijkstra stated, “It’s not enough to show that something works, you must show why it works.” The neuro-symbolic system detailed in this research strives for that ‘why,’ creating adaptable agents capable of navigating open-world complexities not simply through trial and error, but through reasoned, mathematically grounded actions. This emphasis on correctness, rather than mere functionality, is paramount to building truly robust and reliable robotic systems.
What Lies Ahead?
The presented framework, while demonstrating a convergence of neuro-symbolic and reinforcement learning, ultimately underscores a persistent challenge: the formalization of ‘open-world’ itself. The notion of adaptability is trivial without a rigorous definition of the space within which adaptation must occur. One suspects the current reliance on curiosity-driven exploration, while functional, remains a heuristic – a convenient substitute for a provably optimal search strategy. True elegance will demand a means of representing and reasoning about environmental constraints a priori, rather than discovering them through trial and error.
Furthermore, the coupling of hierarchical action abstraction with symbolic planning introduces a new class of potential errors. The translation between continuous sensorimotor data and discrete symbolic representations is inherently lossy. It remains to be seen whether this loss can be systematically bounded, or if the system will inevitably succumb to accumulated inaccuracies. The pursuit of robustness must therefore prioritize verifiable transformations, not merely empirical performance gains.
Future work should concentrate on establishing formal guarantees of correctness, rather than merely demonstrating improved efficiency. A system that ‘works’ on a benchmark is a curiosity; a system whose behavior can be mathematically predicted is a foundation. The ultimate goal is not to create robots that mimic intelligence, but to construct systems whose operations are demonstrably logical, even if that logic diverges from human intuition.
Original article: https://arxiv.org/pdf/2601.16985.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
2026-01-27 19:18