Author: Denis Avetisyan
Researchers have developed a multi-agent system that allows robots to collaboratively plan and execute intricate manipulations using visual feedback and continuous self-assessment.
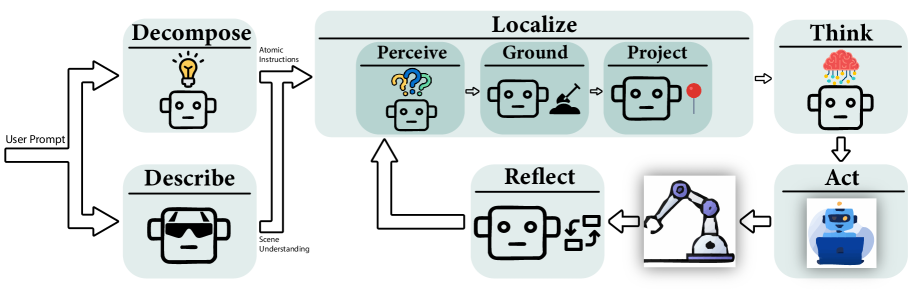
MALLVI is a framework leveraging specialized agents for perception, planning, and reflection to enable robust and adaptable robotic manipulation in real-world environments.
While large language models show promise in robotic control, current approaches often lack robustness in dynamic real-world settings due to open-loop operation and reliance on specialized, fine-tuned models. This paper introduces ‘MALLVI: a multi agent framework for integrated generalized robotics manipulation’, a novel multi-agent system that leverages closed-loop visual feedback to enhance adaptability and generalization in robotic manipulation tasks. By coordinating specialized agents for perception, planning, and reflection, MALLVi iteratively refines actions based on environmental feedback, achieving improved success rates in zero-shot scenarios. Could this framework represent a step towards more resilient and intelligent robotic systems capable of navigating complex, unstructured environments?
The Challenge of Embodied Intelligence
Conventional robotic systems frequently encounter difficulties when operating in real-world settings characterized by unpredictability and a lack of pre-defined structure. Unlike the controlled conditions of a factory floor, environments such as homes, disaster zones, or agricultural fields present a constant stream of novel objects, varying lighting conditions, and unpredictable obstacles. This necessitates a level of robust perception – the ability to accurately interpret sensory data despite noise and ambiguity – far exceeding the capabilities of many existing robots. Equally crucial is adaptable planning, allowing the robot to dynamically adjust its actions and goals in response to unforeseen circumstances, rather than rigidly following pre-programmed sequences. Successfully navigating these complex landscapes demands a shift away from systems reliant on precise maps and predictable scenarios, and towards those capable of learning and improvising in the face of uncertainty.
Many existing artificial intelligence systems, particularly those designed for physical embodiment in robots, are characterized by solutions meticulously crafted by human engineers for specific scenarios. This approach, while achieving success in controlled settings, frequently results in systems that are remarkably inflexible when confronted with the inherent variability of real-world tasks. A robot programmed to grasp a specific object under ideal lighting conditions, for example, may fail utterly when presented with a slightly different version of that object, or even the same object in dim light. This ‘brittleness’ stems from the reliance on explicitly programmed responses rather than the ability to learn and adapt, hindering the deployment of AI in dynamic, unpredictable environments and representing a significant obstacle to truly versatile robotic intelligence.
The development of truly intelligent artificial agents faces a significant hurdle: seamlessly uniting how a system perceives the world, how it reasons about that perception, and how it translates reasoning into physical action. Current AI often compartmentalizes these functions; a robot might accurately see an object but struggle to determine its relevance or how to manipulate it, or conversely, possess strong planning capabilities but fail when confronted with unexpected sensory input. This fractured approach limits adaptability and robustness, hindering performance in dynamic, real-world scenarios. Progress demands a unified architecture where perception directly informs reasoning, and reasoning swiftly guides action – a holistic system capable of continuous learning and responsive behavior, mirroring the integrated intelligence found in biological organisms.

A Multi-Agent Architecture for Robust Task Execution
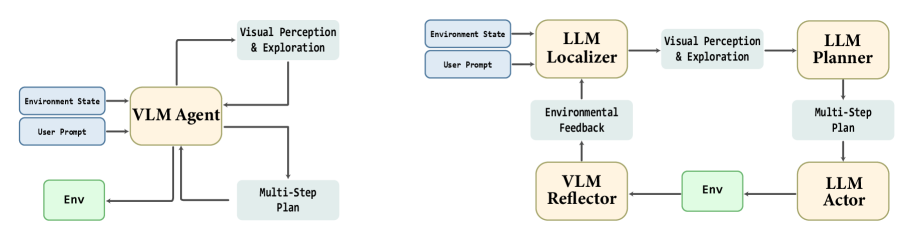
MALLVi utilizes a multi-agent framework to address complex robotic tasks by dividing them into smaller, independent sub-problems. This decomposition allows for the assignment of each sub-problem to a specialized agent, enabling parallel processing and focused expertise. Each agent operates with a defined scope – for example, one agent might be responsible for visual perception, while another handles motion planning – and communicates with other agents to achieve the overall task objective. This modularity contrasts with monolithic approaches and facilitates scalability and adaptability to new or changing environments and task requirements.
The MALLVi framework employs a modular design consisting of three core agents, each responsible for a distinct aspect of task completion. The Descriptor Agent analyzes the environment to generate a comprehensive scene understanding, providing contextual information for subsequent operations. Complementing this, the Localizer Agent identifies and locates objects within the scene, pinpointing their position for interaction. Finally, the Decomposer Agent breaks down complex tasks into a sequence of simpler, executable sub-problems. This specialization allows each agent to focus on its defined function, improving overall system efficiency and robustness compared to monolithic approaches.
MALLVi consistently achieves state-of-the-art performance across multiple robotic benchmarks. Evaluations on real-world tasks, the VIMABench suite, and the RLBench platform demonstrate that MALLVi surpasses existing systems in task completion rates. Specifically, MALLVi’s coordinated multi-agent architecture yields a statistically significant improvement in success rates compared to single-agent approaches and alternative multi-agent frameworks tested under identical conditions. These results indicate a substantial advancement in the robustness and adaptability of robotic systems for complex, real-world applications.

Closing the Loop: Error Detection and Recovery
The Reflector Agent functions as a dedicated monitoring system within the multi-agent framework, continuously observing the actions and states of other agents during task execution. This monitoring process isn’t passive; the Reflector Agent actively evaluates agent behavior against expected progress, identifying deviations that suggest potential errors or failures. Error identification is based on discrepancies between observed states and anticipated outcomes, allowing the Reflector Agent to detect stalled agents, incorrect object manipulations, or situations where an agent is unable to achieve its assigned subgoal. The data collected during this closed-loop feedback process is then used to trigger corrective actions, such as reactivating failing agents or re-allocating tasks, ensuring continued progress toward overall task completion.
The Reflector Agent employs visual feedback from the environment to monitor the operational status of other agents during task execution. When an agent fails to complete a required action – indicated by a discrepancy between expected and observed visual states – the Reflector Agent initiates reactivation protocols. This involves re-instantiating the failed agent and providing it with updated environmental information, allowing it to resume the task. This dynamic error recovery is particularly effective in complex and unpredictable environments, as the system doesn’t rely on pre-programmed solutions for anticipated failures, but instead reacts to observed issues in real-time, maintaining task completion rates.
System robustness is demonstrably improved through the implementation of an error recovery mechanism working in conjunction with specialized agents. Quantitative results on the RLBench benchmark suite, across nine distinct tasks, indicate performance gains when compared to three baseline methods: Multi-Agent Learning with Memory and Manipulation (MALMM), a Single-Agent approach, and a system configuration lacking the Reflector Agent. These comparative analyses establish the efficacy of the described architecture in maintaining task completion rates and overall system stability under varying conditions and potential failure scenarios.

Toward a Future of Collaborative Intelligence
The architecture of MALLVi represents a significant departure from traditional robotic control systems, moving beyond simple task execution through the implementation of multi-agent collaboration. Rather than a single, monolithic program dictating robotic actions, MALLVi utilizes a network of specialized agents that communicate and coordinate to achieve goals. This approach allows for a more nuanced and flexible response to complex scenarios, as individual agents can focus on specific sub-tasks and adapt to unforeseen circumstances. The system’s inherent modularity not only simplifies development and maintenance but also provides a clear pathway towards increasingly intelligent and adaptable robots capable of handling a wider range of tasks with greater efficiency and resilience, mirroring the distributed problem-solving capabilities observed in natural systems.
The MALLVi system achieves enhanced problem-solving capabilities through a division of labor between specialized agents. This architecture features ‘Thinker’ agents dedicated to high-level planning and reasoning, formulating strategies to address complex tasks, while ‘Actor’ agents focus on the precise execution of those plans within the robotic environment. This separation allows each agent to refine its specific skillset, boosting overall efficiency and precision compared to monolithic robotic systems. By coordinating the Thinker’s cognitive abilities with the Actor’s physical dexterity, MALLVi can navigate intricate challenges – such as those found in the VIMABench – with greater success, effectively breaking down complex problems into manageable, coordinated actions.
The architecture’s advanced reasoning stems from a novel combination of techniques, notably ‘Code-as-Policies’ and ‘Inner Monologue’. Code-as-Policies allows the system to generate and execute programmatic solutions to sub-tasks, effectively translating high-level goals into concrete actions. Complementing this, the ‘Inner Monologue’ facilitates a process of self-reflection, enabling the system to evaluate potential plans and refine its approach before execution. This synergistic combination has demonstrably improved performance; rigorous testing on the VIMABench revealed the highest success rates to date, consistently surpassing the capabilities of established collaborative robotics systems like Wonderful Team, CoTDiffusion, and PERIA across the majority of assessed categories. The result isn’t simply improved task completion, but a significant step towards robots capable of genuine problem-solving and adaptable intelligence.
The MALLVi framework, as detailed in the study, operates on the principle that complex robotic manipulation benefits from decomposition into specialized agents. This echoes a fundamental tenet of robust system design-divide and conquer. As Barbara Liskov stated, “Programs must be correct and usable, not just work.” MALLVi’s modularity, with agents dedicated to perception, planning, and reflection, aims for precisely that-a provably correct system, not merely one that functions adequately in limited test conditions. The iterative closed-loop control, incorporating visual feedback, represents an attempt to approach an invariant state, continually refining the system’s actions to achieve reliable performance as ‘N’ – the number of real-world variations – approaches infinity. This pursuit of invariant behavior is the hallmark of elegant and dependable engineering.
What’s Next?
The pursuit of generalized robotic manipulation, as exemplified by MALLVi, inevitably reveals the chasm between simulated elegance and the intractable messiness of the physical world. While multi-agent architectures offer a modularity appealing to the theoretically inclined, the true test lies not in task completion within controlled environments, but in predictable failure modes when confronted with genuine novelty. The framework’s reliance on visual feedback, while pragmatic, merely postpones the inevitable need for a more fundamental understanding of perception – a realm where current approaches remain largely heuristic.
Future work must confront the limitations of large language models as arbiters of action. Their proficiency in generating plausible sequences does not equate to genuine reasoning. The system’s ‘reflection’ agent, however sophisticated, operates within the confines of the model’s prior distribution; true adaptability demands the capacity for a priori knowledge revision, a capability currently beyond their reach. The challenge isn’t simply to increase the volume of training data, but to develop algorithms grounded in formal logic and provable guarantees.
In the chaos of data, only mathematical discipline endures. The field requires a shift from empirically ‘working’ systems to those that are demonstrably correct, even if that necessitates sacrificing short-term gains in performance. The pursuit of embodied AI will ultimately be judged not by its ability to mimic human behavior, but by its adherence to the immutable laws of physics and the rigor of formal verification.
Original article: https://arxiv.org/pdf/2602.16898.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- EMEA Masters Winter 2026 introduces official Qualifier for Esports World Cup
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
2026-02-20 22:39