Author: Denis Avetisyan
New research introduces a system allowing robots to plan and execute complex scientific experiments autonomously, bridging the challenge of long-term task completion.
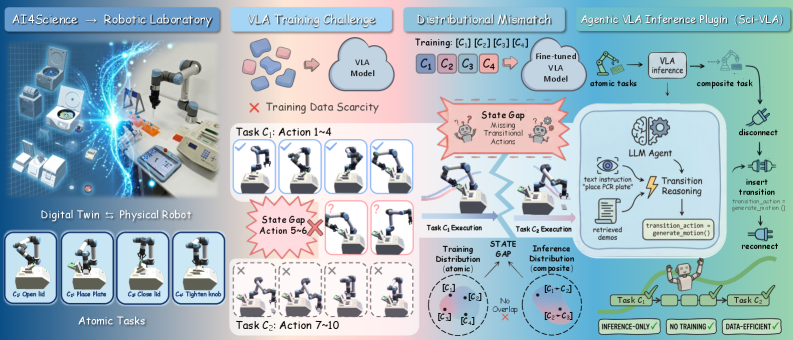
An agentic Vision-Language-Action inference plugin enables robotic laboratories to perform long-horizon tasks without requiring additional training, by generating necessary transitional actions.
While robotic laboratories promise scalable scientific discovery, existing vision-language-action (VLA) models struggle with complex, multi-step experiments due to a disconnect between training and real-world task execution. This work, ‘Sci-VLA: Agentic VLA Inference Plugin for Long-Horizon Tasks in Scientific Experiments’, introduces an agentic inference plugin that bridges this ‘state gap’ by generating necessary transitional actions during execution. Our method enables VLA models to reliably perform long-horizon scientific workflows without requiring additional training data, increasing success rates by 42% in simulated experiments and demonstrating transfer to real-world robotic labs. Could this approach unlock fully autonomous, open-ended scientific exploration?
The Inherent Instability of Extended Robotic Action
Traditional robotic systems often falter when faced with tasks demanding a sequence of coordinated actions, not because of any single catastrophic failure, but due to the gradual accumulation of small errors. Each movement, perception reading, or control adjustment introduces a degree of imprecision; while individually negligible, these errors compound over time, ultimately derailing the entire operation. Furthermore, conventional robotic planning algorithms struggle with the computational complexity of anticipating and mitigating these errors across extended task horizons. The robot must not only determine the correct first step, but also accurately predict how each subsequent action will affect its future state – a challenge that quickly becomes intractable as the number of steps increases. This inherent difficulty limits the robot’s ability to reliably execute complex procedures requiring sustained, precise control over longer durations.
The difficulty of coordinating robotic action intensifies dramatically when tasks demand sustained performance over extended periods – scenarios known as ‘long-horizon tasks’. Unlike short, discrete actions, these undertakings-such as assembling a complex object, navigating a cluttered environment for an extended duration, or providing long-term care-require a robot to maintain consistent performance across numerous sequential steps. Each action builds upon the last, meaning even minor errors accumulate, potentially derailing the entire process. This presents a significant challenge for current robotic systems, as their ability to plan and execute sequences of actions degrades with increasing task length, demanding robust strategies for error recovery and adaptation that go beyond simple reactive behaviors. Successfully tackling long-horizon tasks represents a crucial step toward deploying robots in real-world applications requiring sustained, reliable autonomy.
Traditional approaches to robotic control, such as Reinforcement Learning, frequently encounter difficulties when tackling intricate, multi-stage tasks. While effective in simpler environments, these methods often exhibit a lack of robustness when confronted with the complexities of real-world scenarios demanding prolonged, coordinated action. The core issue lies in the compounding of errors over extended time horizons; small inaccuracies in early steps can propagate and significantly degrade performance later on. Moreover, the computational demands of planning and learning in high-dimensional state spaces become prohibitive, leading to inefficient exploration and slow convergence. Consequently, systems trained using these techniques often struggle to generalize to novel situations or adapt to unforeseen changes, hindering their practical application in dynamic, unpredictable environments.
Current Vision-Language-Action Models frequently encounter difficulty when translating perceived states into effective actions due to a phenomenon termed the ‘State Gap’. This gap arises from the inherent discontinuity between visual observations and the robotic actions required to navigate complex environments; a subtle change in visual input can necessitate a drastically different motor command, creating a fragmented action space. Consequently, models struggle to generalize learned behaviors across even minor variations in initial conditions or environmental configurations. This discontinuity hinders the model’s ability to predict future states accurately and plan a coherent sequence of actions for long-horizon tasks, as even small errors in state interpretation accumulate rapidly, leading to task failure. Bridging this gap requires innovative approaches to state representation and action prediction, enabling a smoother transition between perception and execution.

LLM-Based Agentic Inference: A Logical Bridge
LLM-based Agentic Inference utilizes the advanced reasoning capabilities inherent in large language models, specifically architectures like GPT-5.2, to enhance task completion in complex scenarios. These models are employed not as direct action generators, but as inference engines capable of analyzing task objectives and environmental states to determine optimal behavioral sequences. The strength of this approach resides in the LLM’s capacity for contextual understanding and its ability to extrapolate logical steps beyond immediately observable data, enabling proactive planning and adaptation during task execution. This contrasts with traditional methods reliant on pre-defined action sets or reactive policies, offering a more flexible and robust framework for agentic behavior.
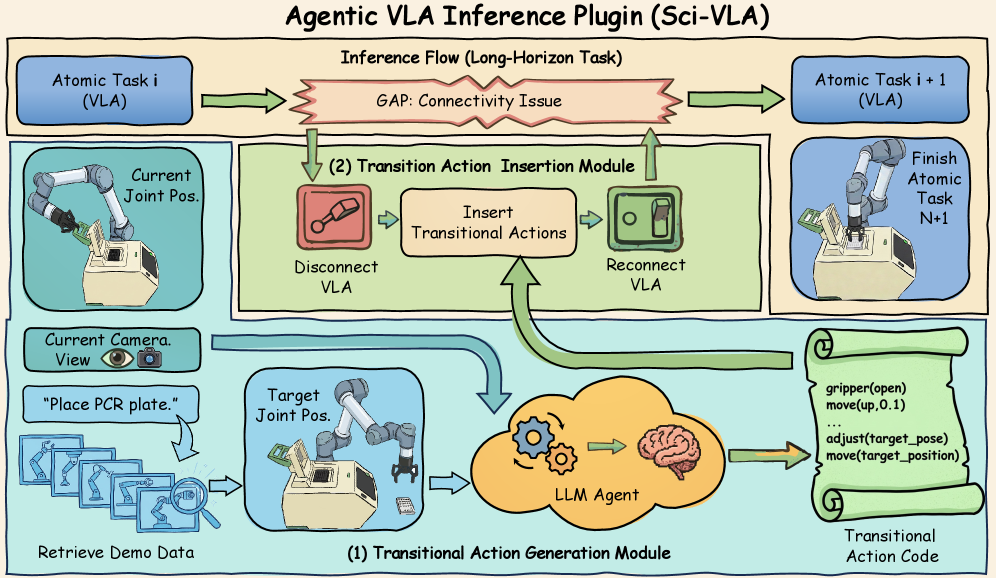
The generation of ‘Transitional Actions’ represents a core component of this methodology, addressing the limitations of direct mapping between high-level goals and discrete, executable actions. These actions are not themselves final steps towards task completion, but rather intermediate behaviors inferred by the LLM to bridge the gaps between atomic tasks. Specifically, the system predicts actions that establish preconditions for subsequent steps or re-orient the agent within its environment. By decomposing complex tasks into a sequence including these inferred transitional behaviors, the agent avoids situations where a direct action request is invalid or inefficient given the current state, ultimately improving the robustness and success rate of long-horizon tasks.
The implementation of transitional actions within LLM-based agentic inference directly addresses the ‘State Gap’ – the discrepancy between an agent’s current state and the preconditions required for subsequent actions – thereby enhancing performance in extended, multi-step tasks. Empirical results demonstrate an approximate 42% improvement in success rates when utilizing this method across a range of Vision-Language-Action (VLA) models. This improvement is attributed to the system’s ability to proactively generate intermediate steps, reducing the likelihood of action failures caused by incomplete or inaccurate state assessments during long-horizon task execution. The quantifiable gain in success rate validates the efficacy of inferring transitional actions as a means of bridging the state gap and improving overall agent performance.
Existing Vision-Language-Action (VLA) models typically execute tasks by directly mapping visual input and language instructions to specific actions. This approach often struggles with complex, multi-step tasks requiring intricate planning. LLM-based agentic inference enhances VLA capabilities by introducing an intermediary action planning stage. Rather than directly generating final actions, the system first infers a sequence of ‘Transitional Actions’ – smaller, more manageable steps – that bridge the gap between high-level instructions and low-level execution. This decomposition allows for more flexible and robust action planning, particularly in scenarios demanding long-horizon reasoning and adaptation to unforeseen circumstances, ultimately improving task success rates as demonstrated by a reported 42% increase across various VLA models.
Virtual Laboratories: A Foundation for Rigorous Testing
The Autobio system employs a ‘Digital Twin’ – a virtual replica of the physical laboratory environment – to facilitate the development and iterative improvement of robotic systems. This digital environment allows for comprehensive testing of robotic behaviors and workflows without requiring physical resources or posing risks to hardware. The Digital Twin accurately models the lab’s geometry, object placements, and relevant physical properties, enabling realistic simulations of robotic tasks. Through this virtual testing ground, developers can rapidly prototype, debug, and optimize robotic control strategies before deployment to a physical robot, significantly accelerating the development lifecycle and reducing costs.
The system’s simulation environment facilitates accelerated development of ‘Transitional Actions’ – the sequences of movements required for a robot to move between high-level task steps – by removing limitations inherent in physical experimentation. This capability allows for iterative refinement of these actions through repeated virtual testing, enabling optimization of parameters such as speed, trajectory, and force without the time and resource costs associated with building and re-testing physical prototypes. Consequently, a greater number of action variations can be explored, leading to improved robustness and efficiency prior to deployment on a physical robot. The simulated environment also allows for safe testing of actions that might pose a risk to equipment or personnel in a real-world setting.
Autoregression-based Virtual Labs (VLAs) and Diffusion Models enhance the system’s capabilities through predictive modeling of robotic actions. Autoregression allows the system to forecast subsequent actions based on a sequence of previous states and actions, effectively learning the dynamics of the laboratory environment. Diffusion Models contribute by generating plausible action sequences, particularly useful in scenarios with high dimensionality or uncertainty. These models are trained on datasets of successful robotic operations, enabling the prediction of optimal actions for completing tasks within the simulated environment, and ultimately improving the efficiency of the robotic system’s performance. The combination of these two approaches allows for both short-term action prediction and the generation of longer, more complex action plans.
The Vision-Language-Action (VLA) Model enables robotic system navigation within the simulated laboratory environment by processing both visual input and natural language instructions to determine appropriate actions. This integration allows the system to interpret scenes, understand task goals communicated through language, and execute the necessary robotic manipulations. Specifically, the VLA model leverages visual data to identify objects and their spatial relationships, while simultaneously parsing language commands to establish task objectives. The combined understanding informs the selection and execution of actions, creating a closed-loop system for autonomous operation within the simulation.
![The end-effector trajectory (yellow lines) demonstrates that the base model [latex]\pi_0[/latex] successfully executes the cleaning task-picking three objects into a basket-in both simulated and real-world environments, with transitional actions highlighted by the dashed box.](https://arxiv.org/html/2602.09430v1/x6.png)
AI4Science: Towards Autonomous Scientific Inquiry
The burgeoning field of AI4Science is rapidly advancing through the synergistic integration of several key technologies. Large Language Models (LLMs) now function as ‘agentic inferencers’, capable of formulating hypotheses and designing experiments. These designs are increasingly tested not in physical labs immediately, but within sophisticated virtual laboratory simulations – offering a safe, cost-effective, and accelerated testing ground. Crucially, these simulations are coupled with advanced Vision-Language-Action (VLA) models, enabling the AI to ‘see’ experimental results – interpreting images and data – and then autonomously determine the next steps in the research process. This closed-loop system, where LLMs reason, simulations execute, and VLAs interpret, constitutes the core of the AI4Science paradigm, promising to reshape scientific investigation by automating complex workflows and accelerating the rate of discovery.
The emerging AI4Science paradigm envisions a future where substantial portions of the scientific method are automated, dramatically reducing the need for direct human involvement in experimentation. This isn’t about replacing scientists, but rather augmenting their capabilities by handling repetitive tasks, analyzing vast datasets, and even formulating hypotheses for testing. By leveraging large language models and advanced simulation tools, systems can independently design experiments, interpret results, and refine approaches – a process previously requiring significant researcher time and expertise. The anticipated outcome is a substantial acceleration of the scientific discovery process, allowing researchers to focus on higher-level conceptualization and interpretation, and potentially unlocking breakthroughs at a rate unattainable with traditional methods. This automation extends beyond simple data analysis, encompassing the entire experimental workflow from initial planning to final conclusion, promising a new era of efficient and impactful research.
The advent of robotic laboratories, fueled by recent advances in artificial intelligence, is poised to redefine the landscape of scientific exploration. These systems integrate large language models, virtual experimentation platforms, and vision-language-action models to create a closed-loop discovery process. Unlike traditional research, where human scientists meticulously design, execute, and analyze experiments, these robotic labs operate with a remarkable degree of autonomy. They can formulate hypotheses, design experimental procedures, conduct the physical experiments using robotic hardware, interpret the resulting data through computer vision and natural language processing, and then refine their approach iteratively – all with minimal human intervention. This capability not only accelerates the pace of scientific investigation but also opens doors to exploring complex scientific questions that were previously intractable due to logistical or time constraints, promising a future where automated systems actively contribute to the expansion of human knowledge.
The emergence of self-directed experimentation signals a fundamental shift in how scientific research is conducted, moving beyond human-guided inquiry towards fully automated workflows. These systems, integrating artificial intelligence with robotic infrastructure, are not simply automating existing protocols but are capable of formulating hypotheses, designing experiments, interpreting data, and iterating on findings with minimal human intervention. This capability promises to dramatically accelerate the pace of discovery across disciplines, from materials science and drug development to fundamental physics and environmental monitoring. The potential for breakthroughs isn’t limited to incremental improvements; autonomous systems can explore vast experimental spaces and identify previously unforeseen relationships, offering the possibility of disruptive innovations and a deeper understanding of the natural world. Consequently, the automation of research promises to unlock scientific progress at a scale and speed previously unattainable.
The pursuit of robust scientific automation, as detailed in this work, demands a commitment to provable correctness over mere empirical success. The agentic VLA inference plugin directly addresses the ‘state gap’ by constructing a logical sequence of actions, a methodology that echoes the spirit of mathematical rigor. As Paul Erdős famously stated, “A mathematician knows all there is to know; a physicist knows some, but a computer scientist knows none.” This sentiment highlights the necessity for a foundation built on demonstrable truths, especially when scaling to complex, long-horizon tasks where even a single flawed assumption can derail an entire experiment. The plugin’s ability to generate transitional actions represents a step towards achieving that necessary logical framework, rather than relying on statistically likely but potentially incorrect heuristics.
What Lies Ahead?
The presented work addresses a practical, if somewhat messy, problem – the execution of lengthy procedures in automated laboratories. It is, however, crucial to acknowledge that bridging the ‘state gap’ with generated transitional actions is not a solution in the truest sense. It is a pragmatic workaround. A truly elegant system would derive those actions from first principles, from a formally defined model of the experimental domain. The current approach, while functional, lacks that inherent mathematical correctness.
Future investigations must therefore prioritize the development of formal representations of scientific protocols. The limitations of Large Language Models as reasoning engines are well-documented; their ability to simulate understanding should not be mistaken for genuine competence. A more robust architecture would integrate symbolic reasoning with the perceptual capabilities of VLA systems, creating a hybrid approach grounded in provable logic rather than statistical correlation.
Finally, the question of validation remains paramount. Demonstrating successful task completion on a limited set of benchmarks is insufficient. A rigorous evaluation requires formal verification – a demonstration that the system cannot fail under specified conditions. Only then can one claim a true advance, moving beyond empirical observation towards a genuinely scientific automation.
Original article: https://arxiv.org/pdf/2602.09430.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Gold Rate Forecast
- Magicmon: World redeem codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Seeing in the Dark: Event Cameras Guide Robots Through Low-Light Spaces
- Simulating Humans to Build Better Robots
2026-02-11 23:04