Author: Denis Avetisyan
A new framework allows robots to dynamically prioritize sensory input, improving their ability to perform intricate, long-duration tasks without extensive human guidance.
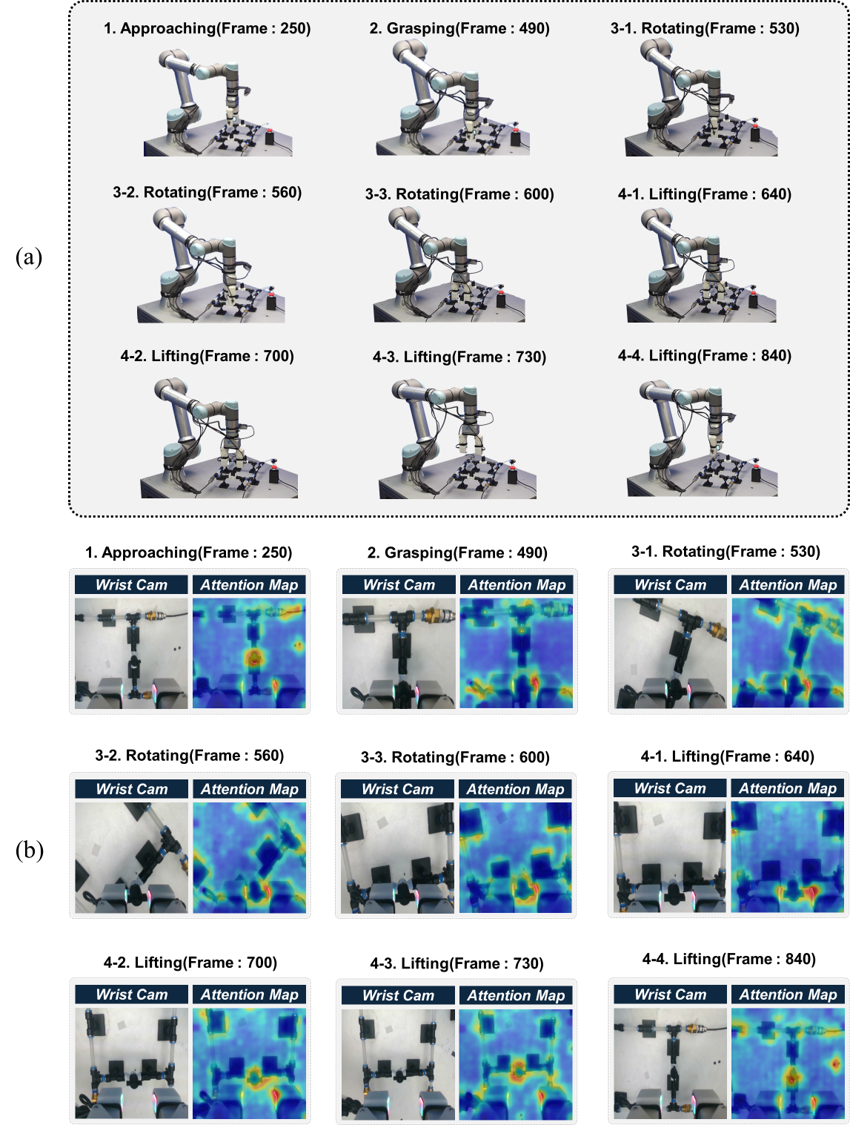
This work introduces a dynamic routing approach for multimodal Vision-Language-Action (VLA) data, enabling selective attention and reducing reliance on labeled datasets.
Processing all available sensory data is computationally expensive and often introduces noise in robotic systems, yet current Vision-Language-Action (VLA) models typically employ static multimodal fusion. This paper, ‘Selective Perception for Robot: Task-Aware Attention in Multimodal VLA’, introduces a dynamic routing framework that mimics human active perception by selectively integrating relevant visual information based on task demands. Our approach achieves improved inference efficiency and control performance through lightweight, adaptive routing and automated data labeling via Vision-Language Models. Could this task-aware attention mechanism pave the way for more robust and resource-efficient robotic manipulation in complex, real-world environments?
Decoding the Sensory Static: Why Robots Struggle to ‘See’ and ‘Feel’
Many robotic systems designed to interpret the world through multiple senses – vision, touch, audio, and more – encounter a surprising hurdle: inter-modality interference. This phenomenon occurs when information from one sensory stream actively hinders the processing of another, ultimately degrading overall performance. Imagine a robot attempting to grasp an object; visual data might falsely indicate a secure grip, even if tactile sensors report slippage. This mismatch isn’t simply noise, but an active disruption where irrelevant or poorly weighted sensory input overwhelms critical signals. Consequently, traditional multimodal systems, often relying on simple averaging or fixed weighting of inputs, struggle in dynamic environments and complex tasks, highlighting the need for more intelligent and adaptive fusion strategies that can discern and prioritize relevant information from the constant stream of sensory data.
Conventional multimodal systems frequently employ static fusion techniques, assigning predetermined weights to each sensory input – a methodology proving increasingly inadequate for intricate tasks. This rigid approach fails to account for the dynamic relevance of different modalities; for example, visual data might be paramount during object identification, while tactile feedback becomes crucial for precise grasping. Consequently, static weighting often leads to suboptimal performance, as irrelevant or less important sensory streams continue to exert undue influence, obscuring critical information and hindering the system’s ability to adapt to changing circumstances. The inability to dynamically prioritize information represents a significant bottleneck in achieving robust and versatile robotic intelligence, particularly in scenarios demanding nuanced, context-aware decision-making.
Successful robotic manipulation, particularly when dealing with extended sequences of actions, hinges on a robot’s ability to selectively focus on the most relevant sensory information. Unlike simple, immediate tasks, long-horizon manipulation – such as assembling a complex object or preparing a meal – demands continuous assessment of numerous inputs from vision, touch, and proprioception. A robot cannot process all data equally; instead, it must dynamically prioritize information streams, downplaying noise or irrelevant stimuli while amplifying signals critical for achieving distant goals. This intelligent prioritization isn’t merely about filtering data, but about weighting each sensory input based on its predictive value for future states and successful task completion, effectively allowing the robot to ‘look ahead’ and anticipate necessary actions based on a refined understanding of the environment.
A significant bottleneck in developing truly adaptable multimodal AI systems lies in the extensive need for human annotation. Current methodologies frequently demand that humans meticulously label and categorize data from various sensory inputs – vision, touch, audio, and more – to train algorithms to effectively integrate this information. This process is not only time-consuming and expensive but also fundamentally limits scalability; as the complexity of tasks increases and the variety of environments expands, the volume of required annotated data grows exponentially. Consequently, progress is often constrained by the availability of labeled datasets, preventing these systems from generalizing to new, unseen scenarios and hindering the development of robust, autonomous agents capable of operating in real-world complexity.
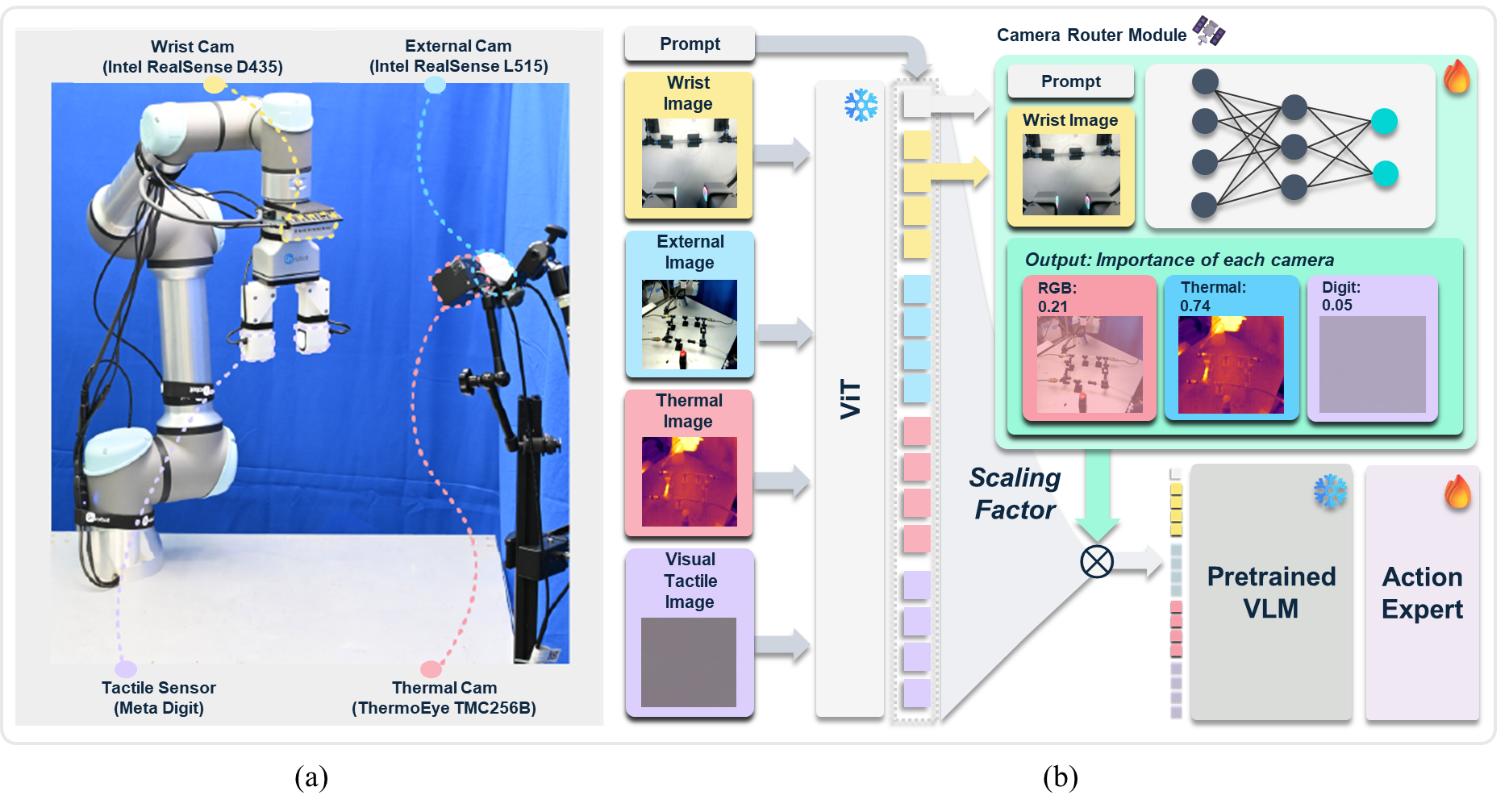
The Dynamic Router: A System That ‘Thinks’ About What It ‘Sees’
The Dynamic Router is a core component designed to assess and predict the relative importance of different input modalities – such as visual and linguistic data – during task execution. This prediction occurs in real-time, adapting to the specific requirements of the current task context. Rather than assigning fixed weights to each modality, the router dynamically adjusts these weights based on an analysis of the task at hand, allowing the system to focus computational resources on the most relevant information stream. This contextual adaptation is achieved through learned parameters that correlate task descriptions with modality importance, enabling the system to prioritize, for example, visual input when the task requires object recognition or linguistic input when the task is driven by textual instructions.
The Dynamic Router utilizes a wrist-mounted camera to capture visual data, serving as its primary source of visual input. This visual information is then processed in conjunction with language prompts provided by the user, which explicitly define the task at hand. The combination of these two input modalities – visual data from the camera and textual task requirements – allows the router to dynamically assess the relevance of each modality for accurate task completion. The language prompts provide contextual information, guiding the router in interpreting the visual input and determining which features are most pertinent to the current objective.
The Dynamic Router utilizes attention pooling for textual data and mean pooling for image data to extract relevant features for modality importance prediction. Attention pooling weights different parts of the language prompt based on their relevance to the current task, allowing the router to focus on key instructions. Simultaneously, mean pooling applied to the visual input from the wrist-mounted camera calculates the average feature vector across the image, providing a condensed representation of the visual scene. These pooling techniques reduce dimensionality and highlight the most salient information from each modality, facilitating accurate assessment of their respective contributions to task completion.
Focal Loss is implemented within the Dynamic Router training process to address potential data imbalances between modalities. This loss function assigns higher weights to misclassified examples from infrequent, yet crucial, modalities, thereby mitigating the dominance of easily classified data from prevalent modalities. Specifically, it down-weights the contribution of easily classified examples, focusing training on hard examples and improving the router’s ability to accurately identify and prioritize important modalities even when they are underrepresented in the training dataset. This approach ensures the router doesn’t simply favor the most frequently observed input type and instead learns a more robust and generalized prioritization strategy.
![The VLA framework utilizes a dynamic camera router to predict importance weights [latex]WW[/latex] for different views, enabling selective prioritization of task-relevant visual information during action training.](https://arxiv.org/html/2602.15543v1/figs/Fig2.png)
Vision, Language, and Action: Weaving Sensory Input Into Coherent Behavior
The Dynamic Router functions as an input to a Dynamic Routing system designed to modulate the contribution of various sensory inputs. This system operates by assigning weights to incoming data – visual, linguistic, or otherwise – and these weights are not static. Instead, the Dynamic Routing system adjusts these weights dynamically, based on predictions generated by the Dynamic Router itself. This predictive weighting allows the system to prioritize relevant sensory information and suppress noise, enabling more robust and efficient processing of complex environmental inputs. The resulting weighted data then informs downstream tasks within the broader Vision-Language-Action model.
The Vision-Language-Action (VLA) model facilitates robotic task completion by integrating three core data streams: visual input, natural language instructions, and sequential action data. This integration allows the robot to interpret environmental observations from cameras, process and understand spoken or written commands, and then generate or select appropriate action sequences to achieve a defined goal. The VLA model isn’t simply a concatenation of these inputs; it utilizes the relationships between them to contextualize actions. For example, the instruction “pick up the red block” is processed in conjunction with visual data to identify the target object, and then translated into a series of motor commands. This combined processing enables the robot to perform complex tasks requiring reasoning about both the environment and the desired outcome.
The Vision-Language-Action (VLA) model employs Flow Matching as its core mechanism for predicting sequential actions. Flow Matching operates by learning a continuous normalizing flow that maps data distributions to a simplified, tractable distribution, enabling efficient sampling of likely action sequences. To optimize the VLA model without incurring the computational cost of training all parameters, LoRA (Low-Rank Adaptation) is implemented. LoRA introduces trainable low-rank matrices to the existing model weights, significantly reducing the number of trainable parameters and associated memory requirements while maintaining performance comparable to full fine-tuning.
VLM-based auto-labeling automates aspects of data annotation traditionally performed by humans, increasing the scalability of training datasets for robotic systems. This process leverages Vision-Language Models (VLMs) to generate labels for visual data, reducing the need for manual intervention and associated costs. Specifically, the VLM analyzes visual input and predicts corresponding language descriptions, effectively creating labeled data points. This approach extends labeling to a broader range of scenarios and allows for the creation of larger datasets with reduced human effort, thereby accelerating the development and refinement of robotic control policies.
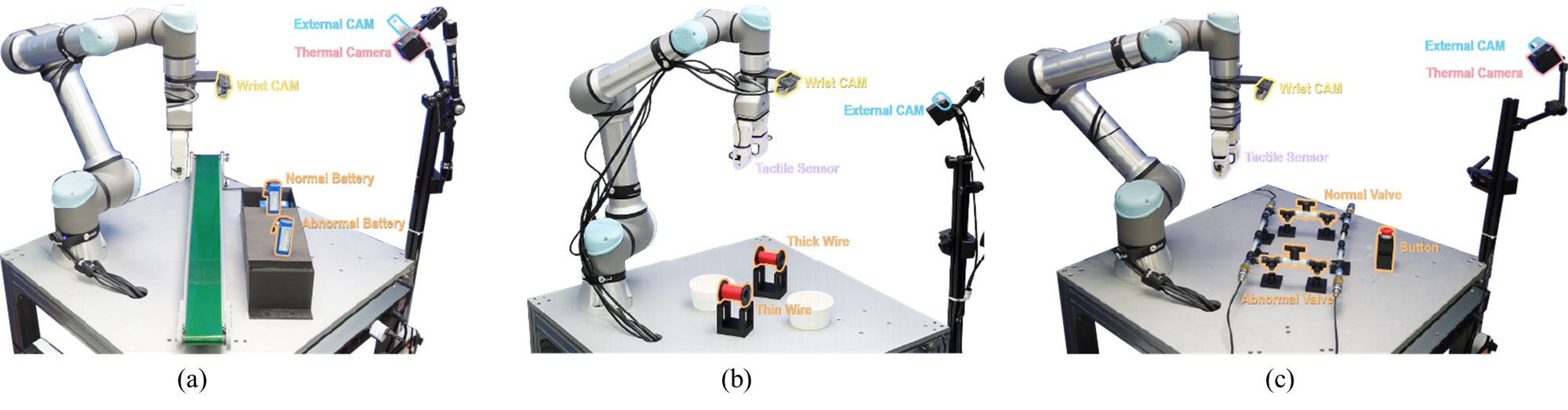
Toward Autonomous Systems: Reducing Reliance on Human Guidance
Robotic systems often struggle with the sheer volume of sensory input, facing challenges from redundant information and conflicting signals between modalities like vision and touch. This research addresses these issues through a novel system designed to intelligently filter and prioritize sensory data. By minimizing the impact of both information redundancy – where multiple sensors provide the same data – and inter-modality interference – where conflicting signals create uncertainty – the system achieves markedly more reliable performance in complex manipulation tasks. The approach doesn’t simply increase the amount of data processed, but rather refines how that data is utilized, allowing the robot to focus computational resources on the most pertinent information and execute tasks with greater consistency and accuracy, even in challenging or ambiguous environments.
The system’s efficiency stems from a dynamic routing mechanism that intelligently prioritizes sensory information. Rather than processing all available data equally, the robot selectively focuses on the most pertinent inputs for each specific task phase. This targeted approach reduces computational load and minimizes interference from irrelevant signals, allowing for quicker and more decisive actions. By dynamically adjusting which sensory streams are emphasized, the robot achieves heightened responsiveness to changing conditions and a more streamlined manipulation process. The result is a system capable of performing complex tasks with greater speed and reliability, mirroring the human ability to filter and prioritize information in real-time.
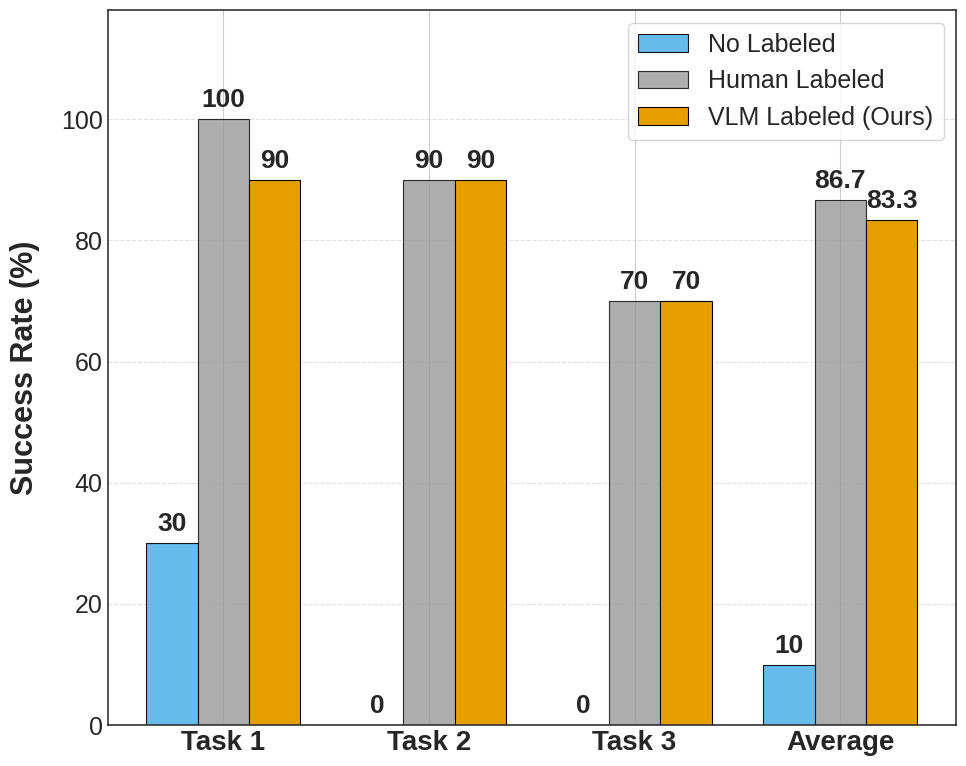
The proposed robotic system demonstrates a noteworthy capacity for complex task completion, achieving a 73.33% success rate across extended, multimodal robotic challenges. This performance level is particularly significant as it rivals the efficacy of systems trained with meticulously curated, human-labeled datasets. The ability to perform comparably without reliance on exhaustive manual annotation represents a substantial step toward more adaptable and broadly applicable robotic solutions, suggesting the system can effectively interpret and respond to a variety of sensory inputs during prolonged interaction with its environment. This milestone highlights the potential for autonomous robots to perform intricate tasks with a level of reliability previously attainable only with extensive human guidance.
The research demonstrates a compelling pathway toward reducing the reliance on costly and time-consuming human-labeled datasets for robotic manipulation. By leveraging Vision-Language Models (VLMs) to generate task labels, the system achieves an impressive 83.33% success rate on complex, long-horizon multimodal robotic tasks. This performance notably approaches the 86.67% success rate attained using traditional human-labeled data, signifying a substantial reduction in the performance gap. Critically, the VLM-assisted approach dramatically outperforms methods that operate without multimodal input, which registered a 0% success rate, highlighting the power of integrating visual and linguistic information for robust robotic control and adaptability.
The pursuit of efficient robotic manipulation, as detailed in this work, inherently demands a willingness to dismantle established approaches. This research doesn’t simply use multimodal data; it actively challenges the assumption that all sensory input is equally valuable. It’s a system designed to strategically ignore, to route around perceived irrelevance – a beautifully destructive process. Ada Lovelace observed that “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This parallels the framework presented; the robot doesn’t magically understand tasks, it systematically prioritizes information, effectively reverse-engineering the necessary steps through selective attention and dynamic routing, guided by the ‘orders’ of the learned task parameters.
Beyond the Horizon
The presented framework, while demonstrating a capacity for selective attention in multimodal robotic systems, merely scratches the surface of genuine sensory integration. The reliance on VLM auto-labeling, a clever circumvention of the labeling bottleneck, simultaneously highlights the field’s persistent dependence on pre-trained knowledge. Future work must address the limits of this borrowed intelligence; can a robot truly understand an action, or only mimic a statistical correlation? The current architecture treats sensory inhibition as a routing problem, but the brain doesn’t simply route – it actively suppresses, reinterprets, and hallucinates.
A critical next step involves dismantling the assumption of a fixed “task” horizon. Long-horizon tasks aren’t sequences of discrete actions, but branching explorations of possibility. A truly adaptive system must not only select relevant information but also define relevance in real-time, based on internal models of uncertainty and potential reward. The current emphasis on dynamic routing feels almost quaint when considered against the backdrop of truly open-ended learning.
Ultimately, the challenge isn’t building a robot that can do things, but one that can decide what to do. This necessitates a move beyond supervised learning, towards systems capable of intrinsic motivation and self-directed exploration. The black box remains largely unopened; the illusion of intelligent action is easily maintained. The real work begins when the robot starts asking its own questions.
Original article: https://arxiv.org/pdf/2602.15543.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Total Football free codes and how to redeem them (March 2026)
- EMEA Masters Winter 2026 introduces official Qualifier for Esports World Cup
2026-02-18 13:13