Author: Denis Avetisyan
New research demonstrates a powerful framework for robots to anticipate outcomes and adapt their actions, leading to more robust and generalizable manipulation skills.
![LingBot-VA constructs a predictive world model through pretraining on expansive video and robotic action data, achieving substantial performance gains on complex real-world manipulation tasks-including those involving deformable objects and precision control-and demonstrating emergent capabilities such as long-range temporal memory and few-shot adaptation beyond standard policy learning, effectively modeling visual dynamics and inferring inverse dynamics from robot videos-surpassing benchmarks like [latex]\pi_{0.5}[/latex].](https://arxiv.org/html/2601.21998v1/x1.png)
This paper introduces LingBot-VA, an autoregressive diffusion framework unifying video prediction and action inference for advanced robotic control and achieving state-of-the-art results in both simulation and real-world deployments.
Despite advances in robotic learning, achieving robust and generalizable control remains challenging due to the difficulty of anticipating future states. This work, ‘Causal World Modeling for Robot Control’, introduces LingBot-VA, an autoregressive diffusion framework that learns to predict video dynamics and infer optimal actions simultaneously, effectively building a causal understanding of the environment. By unifying video prediction and control within a shared latent space-driven by a Mixture-of-Transformers architecture and a closed-loop rollout mechanism-LingBot-VA demonstrates state-of-the-art performance in both simulation and real-world manipulation tasks. Could this approach pave the way for robots that proactively adapt to complex, dynamic environments with minimal human intervention?
Predicting the Dance: The Challenge of Visual Foresight
The ability to foresee upcoming visual information is fundamental to the operation of robots and autonomous systems navigating the physical world, yet achieving accurate video prediction proves remarkably difficult. Real-world dynamics are inherently complex, involving countless interacting elements and unpredictable events that defy simple modeling. A self-driving car, for instance, must anticipate not only the trajectory of other vehicles but also the actions of pedestrians, the shifting of light and shadows, and even the potential for unexpected obstacles-all from a stream of visual data. This demand for anticipating future states, coupled with the sheer volume of possible outcomes, creates a computational challenge that traditional computer vision techniques struggle to overcome, necessitating novel approaches to model and predict the ever-changing visual landscape.
Current video prediction techniques often falter when attempting to forecast events occurring far into the future, a limitation stemming from the inherent difficulty in modeling complex, real-world interactions over extended time scales. These methods frequently rely on learning patterns from specific training datasets, resulting in poor performance when confronted with novel situations or environments not previously encountered. This lack of generalization significantly impedes the deployment of these systems in dynamic, unpredictable settings – such as autonomous navigation or robotic manipulation – where the ability to anticipate and react to unforeseen circumstances is paramount for robust and reliable operation. Consequently, advancements are needed to create prediction models that are not only accurate in the short term, but also capable of extrapolating plausible future trajectories across a broader range of possibilities and adapting to previously unseen dynamic scenarios.
Truly effective robotic control transcends simply predicting a single future outcome; instead, it necessitates a nuanced, probabilistic grasp of all plausible futures. A robot operating in a dynamic environment – a bustling city street, a cluttered warehouse, or even a domestic home – will inevitably encounter uncertainty. Consequently, a system that can enumerate and assess the likelihood of multiple potential scenarios is far more robust than one reliant on a single, deterministic forecast. This approach allows for proactive planning, risk mitigation, and adaptable behavior; the robot doesn’t just react to what is happening, but anticipates what could happen, enabling it to select actions that maximize success across a range of possibilities. Such probabilistic foresight is paramount for safe, reliable, and truly autonomous operation in the real world.
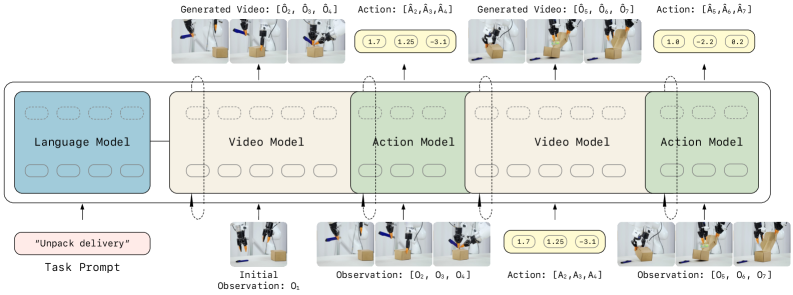
Weaving Action and Prediction: Introducing LingBot-VA
LingBot-VA employs an autoregressive diffusion framework to address robotic manipulation by simultaneously predicting future video dynamics and inferring the corresponding actions. This approach models both prediction and action inference within a single generative process, allowing the system to forecast how a scene will evolve and, crucially, to determine the robotic actions needed to influence that evolution. The framework utilizes diffusion models, iteratively refining a noisy initial state into a coherent prediction of future states, and then leverages this predicted trajectory to infer a sequence of actions. This integration streamlines the planning process, as the predicted dynamics directly inform action selection, eliminating the need for separate prediction and planning stages.
LingBot-VA employs a Mixture-of-Transformers (MoT) architecture to facilitate the concurrent processing of heterogeneous data modalities including visual inputs, natural language instructions, and robotic action sequences. This MoT framework consists of multiple transformer networks, each specializing in a particular modality, with a gating network dynamically selecting and combining the outputs of these specialized networks based on the input data. This allows the system to represent and integrate information from vision, language, and action within a shared embedding space, enabling cross-modal reasoning and coordinated action planning. The architecture supports variable-length inputs for each modality, improving adaptability to diverse task specifications and environmental conditions.
LingBot-VA’s integrated framework enables proactive action inference by conditioning action prediction on predicted future states. Rather than treating prediction and action planning as separate processes, the system jointly models both within a single autoregressive diffusion model. This allows the system to anticipate the consequences of potential actions and select those most likely to achieve a defined goal. Specifically, the predicted future states serve as contextual input for the action inference module, effectively creating a closed-loop system where predicted outcomes directly inform action selection, leading to more effective and goal-oriented robotic manipulation.
LingBot-VA utilizes Flow Matching and Autoregressive Diffusion as core components for predictive modeling. Flow Matching establishes a continuous normalizing flow to transform complex data distributions into simpler, tractable forms, enabling efficient density estimation and sampling. Autoregressive Diffusion, building upon this, iteratively refines predictions by progressively adding noise and then learning to reverse this process, effectively generating likely future states. This combination allows LingBot-VA to achieve robust predictions even with noisy or incomplete data, and facilitates efficient sampling of possible future trajectories – crucial for planning and control in robotic manipulation tasks. The system employs these techniques to model temporal dependencies within video data, predicting future frames and object states with improved accuracy and stability compared to traditional methods.

Building Resilience: Core Design Principles
LingBot-VA employs Noisy History Augmentation and Partial Denoising to improve both robustness and computational efficiency. Noisy History Augmentation introduces variations to the input history during training, exposing the model to a wider range of potential inputs and increasing its resilience to real-world noise and variations in user input. Partial Denoising specifically targets corrupted or incomplete input histories, training the model to reconstruct missing information and maintain performance even with imperfect data. These techniques collectively reduce the model’s sensitivity to input perturbations and improve generalization, while also contributing to a more stable and predictable inference process.
Causal Consistency within LingBot-VA is achieved by structuring the model to strictly adhere to the temporal sequence of events during both prediction and inference. This means that any predicted future state or inferred action is constrained by the established history; the model cannot generate outcomes that precede or violate the documented sequence of interactions. Specifically, the system maintains a clear record of event ordering and utilizes this information to filter and validate potential outputs, preventing illogical or inconsistent responses that could arise from autoregressive models without such constraints. This approach ensures that the model’s behavior remains logically sound and predictable, crucial for maintaining coherent dialogue and action sequences.
LingBot-VA employs asynchronous inference to improve throughput by overlapping the computation of different parts of the output sequence; rather than waiting for the completion of each step before initiating the next, processing is pipelined. This is coupled with a Key-Value (KV) cache which stores the results of prior computations, specifically the key and value matrices used in the attention mechanism. By retrieving these previously computed values instead of recalculating them, the KV cache significantly reduces redundant calculations, leading to lower latency and increased efficiency, particularly for longer sequences. The KV cache is essential as autoregressive models inherently revisit previously processed tokens during inference.
Autoregressive models, by their nature, process data sequentially, leading to computational bottlenecks as the sequence length increases; each new element requires recalculation based on all preceding elements. LingBot-VA mitigates this through techniques like Asynchronous Inference, which overlaps computation to improve throughput, and the implementation of a KV Cache, storing and reusing previously computed key-value pairs to avoid redundant calculations. These optimizations directly address the quadratic scaling issue inherent in autoregressive architectures, reducing both latency and computational cost, particularly for long-form generation and complex reasoning tasks.
![LingBot-VA exhibits consistently greater data efficiency than [latex]\pi_{0.5}[/latex] in post-training stages of the “Make Breakfast” task across varying data conditions.](https://arxiv.org/html/2601.21998v1/x8.png)
Validating the Vision: Real-World Benchmarking
To rigorously assess its capabilities, LingBot-VA underwent extensive evaluation using established robotic manipulation benchmarks, specifically RoboTwin 2.0 and LIBERO. These platforms present a significant challenge to robotic systems due to their complexity and the need for precise control and adaptability. RoboTwin 2.0 focuses on realistic simulation of industrial manipulation tasks, while LIBERO emphasizes learning from limited data and generalizing to novel scenarios. By testing LingBot-VA on these diverse and demanding benchmarks, researchers aimed to establish a clear understanding of its performance limits and demonstrate its readiness for real-world deployment. The selection of these particular benchmarks ensures a comprehensive evaluation of LingBot-VA’s ability to handle a broad spectrum of robotic manipulation challenges.
Rigorous testing of the LingBot-VA framework on industry-standard robotic manipulation benchmarks-RoboTwin 2.0 and LIBERO-reveals state-of-the-art performance capabilities. The system consistently achieves a 92.0% success rate on the complex tasks within RoboTwin 2.0, indicating a high degree of robustness and adaptability in simulated environments. Further validation on the LIBERO benchmark yields an even more impressive 98.5% success rate, demonstrating the framework’s capacity to reliably execute manipulation tasks with a high level of precision. These results collectively highlight LingBot-VA’s effectiveness and position it as a significant advancement in robotic control and automation.
LingBot-VA achieves robust performance in complex robotic manipulation through its capacity for predictive reasoning and action inference. The framework doesn’t merely react to current conditions; it anticipates the consequences of each movement, effectively simulating potential outcomes before execution. This predictive capability, coupled with an ability to deduce the most effective course of action, allows LingBot-VA to navigate intricate tasks with heightened reliability and efficiency. By internally modeling the physical world and the effects of its actions, the system minimizes errors, reduces the need for trial-and-error learning, and ultimately performs manipulation tasks with a level of foresight previously unattainable in robotic systems. This proactive approach represents a significant advancement, enabling the robot to handle unpredictable scenarios and achieve consistent success even in challenging environments.
LingBot-VA represents a significant advancement in robotic manipulation, demonstrably exceeding the performance of established methodologies like π0.5, particularly when faced with scenarios involving scarce adaptation data. Evaluations reveal an improvement of over 20% on complex tasks under these challenging conditions, suggesting a shift in how robots approach task completion. This enhanced capability stems from the framework’s ability to rapidly generalize from limited experience, enabling robust performance even when presented with novel situations or imperfect environmental information. The results highlight a new paradigm where robots aren’t simply programmed with specific solutions, but instead learn to adapt and solve problems with greater autonomy and efficiency, paving the way for more versatile and reliable robotic systems.

The pursuit of robotic manipulation, as demonstrated by LingBot-VA, isn’t about commanding machines, but about persuading chaos. This framework, weaving video prediction with action inference, doesn’t solve the problem of real-world interaction – it constructs a delicate spell, a generative model attempting to measure the darkness of unpredictable environments. Fei-Fei Li once observed, “AI is not about making machines smarter; it’s about making our lives better.” This echoes within LingBot-VA; the framework isn’t merely achieving state-of-the-art results, but attempting to bridge the gap between simulation and reality, to imbue robotic actions with a touch of persuasive grace. The model functions until it meets production, as all spells eventually do, and its robustness is measured not in accuracy, but in the fleeting moments where chaos yields to control.
What’s Next?
LingBot-VA, with its unified approach to video prediction and action inference, delivers performance. But any semblance of success merely indicates the questions weren’t asked with sufficient rigor. The model skillfully navigates the illusion of causality, promising a future where robots manipulate the world with foresight. Yet, the true test lies not in replicating observed actions, but in gracefully failing when the inevitable noise of reality intrudes. A perfect prediction is a phantom – a sign that the system is mirroring, not understanding.
The framework’s reliance on autoregressive diffusion is a clever incantation, but it doesn’t address the fundamental issue: the world isn’t a smoothly flowing video. It’s a cascade of discontinuities, a hail of improbable events. Future iterations will undoubtedly focus on injecting more ‘reality’ into the training data, but that’s like trying to contain chaos with finer mesh. The real breakthrough won’t be in building more elaborate predictors, but in accepting the inherent unpredictability and designing systems that are robustly unreliant on perfect knowledge.
One suspects the pursuit of ‘generalizable’ manipulation is a fool’s errand. Specificity, a willingness to embrace the limitations of a given task and environment, is the only path to genuine resilience. The goal shouldn’t be a robot that can ‘do anything,’ but one that knows precisely what it cannot do, and acts accordingly. After all, anything you can measure isn’t worth trusting.
Original article: https://arxiv.org/pdf/2601.21998.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
2026-02-01 07:11