Author: Denis Avetisyan
Researchers have developed a new framework that allows robots to continually learn new tasks without losing previously acquired abilities, paving the way for more adaptable and versatile robotic systems.
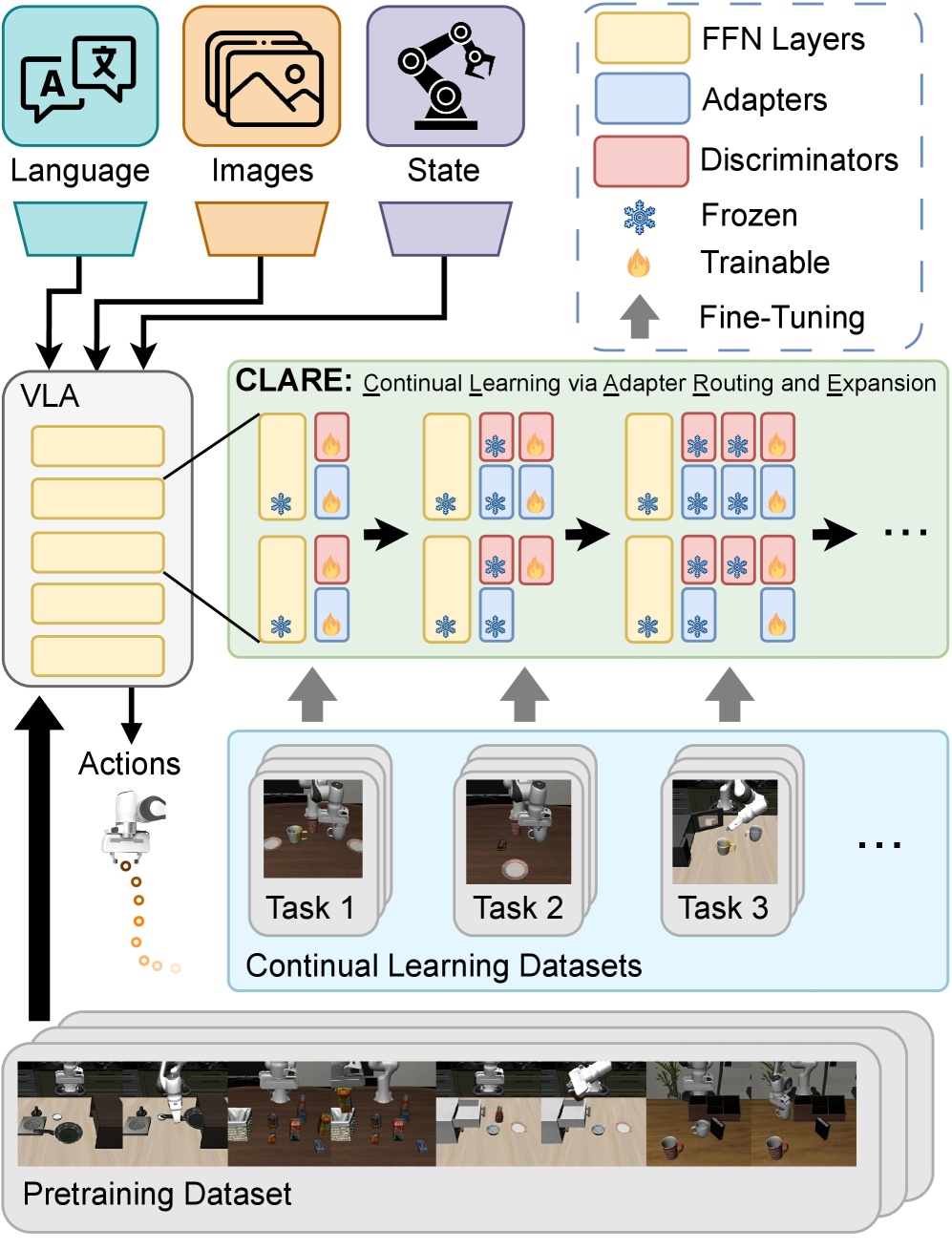
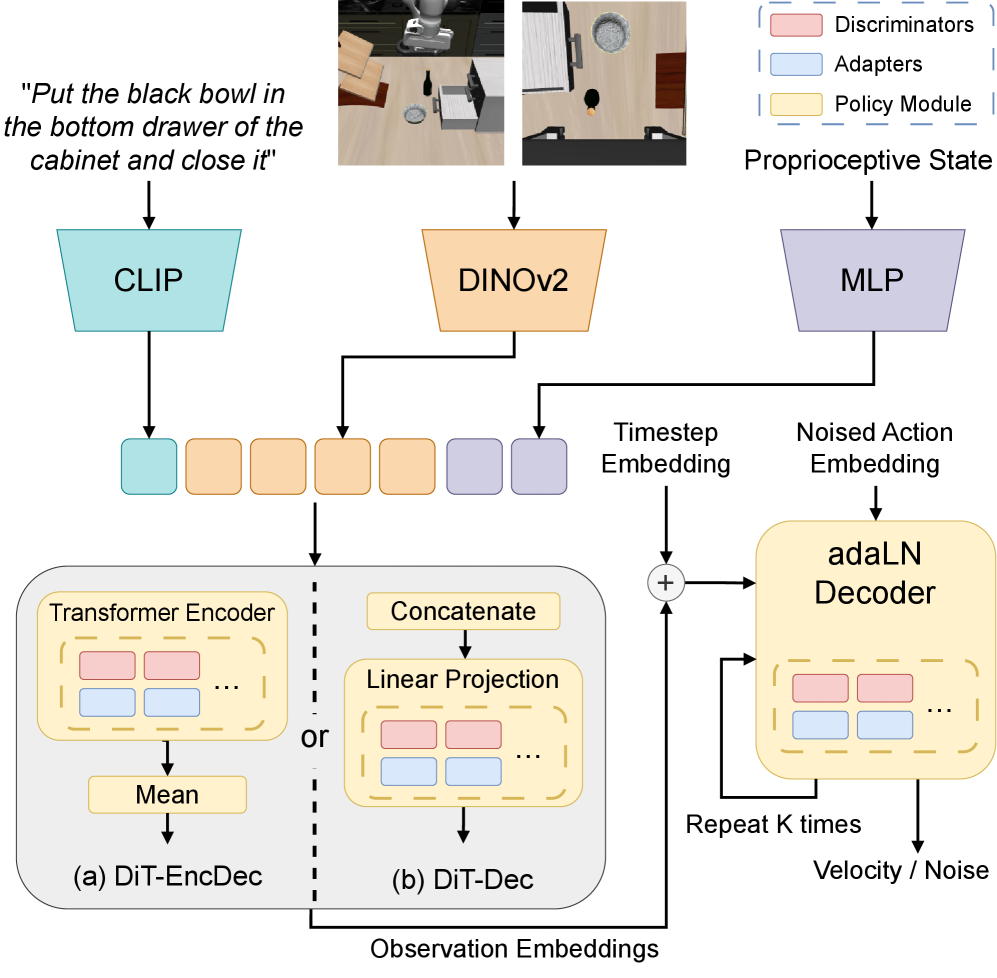
CLARE utilizes autonomous adapter routing and expansion based on feature similarity to enable continual learning in vision-language-action models for robotics.
While fine-tuning pre-trained vision-language-action models is common for robotic task learning, it suffers from catastrophic forgetting when adapting to new skills over time. To address this, we introduce ‘CLARE: Continual Learning for Vision-Language-Action Models via Autonomous Adapter Routing and Expansion’, a parameter-efficient framework that enables continual learning without storing past data. CLARE strategically expands model capacity with lightweight adapter modules, dynamically routing them based on feature similarity to previously learned tasks. Could this approach unlock truly lifelong learning capabilities for robots operating in complex, ever-changing environments?
The Persistence of Knowledge: Confronting Catastrophic Forgetting
Conventional machine learning systems, while adept at specific tasks, often exhibit a significant vulnerability known as catastrophic forgetting. This phenomenon describes the tendency of a trained neural network to abruptly and drastically lose previously learned information when exposed to new data or tasked with learning a new skill. Unlike human learning, which involves gradual refinement and knowledge consolidation, these models overwrite existing synaptic connections to accommodate novel inputs, effectively ‘forgetting’ what they previously knew. This poses a critical limitation in dynamic environments where continuous adaptation is essential, as each new learning experience can diminish performance on older, previously mastered tasks. Researchers are actively exploring methods – including regularization techniques, replay buffers, and architectural innovations – to mitigate this issue and enable machines to learn incrementally without sacrificing prior knowledge, moving closer to the flexible and robust learning capabilities of biological systems.
The demand for adaptable robotic systems highlights a critical challenge in machine learning: continual learning. Unlike traditional models trained on static datasets, robots operating in dynamic environments must constantly acquire new skills and refine existing ones. This requires a system capable of accumulating knowledge over time, a feat hindered by catastrophic forgetting – the tendency to abruptly lose previously learned information when exposed to new data. Consequently, a robot designed to perform a sequence of tasks – perhaps initially sorting objects, then assembling components, and finally navigating complex terrain – would struggle to integrate these skills without significant performance degradation. The inability to retain past experiences limits a robot’s autonomy and necessitates frequent retraining, a costly and impractical solution for long-term operation in real-world settings.
CLARE: A Framework for Dynamic Skill Acquisition
CLARE mitigates catastrophic forgetting in Vision-Language-Action Models (VLAs) through the implementation of lightweight adapter modules. These adapters are injected into the VLA architecture and dedicated to specific tasks, enabling task-specific learning without altering the weights of the pre-trained core model parameters. This approach preserves previously acquired knowledge while allowing for continuous learning of new skills. Adapters are typically small neural networks composed of down-projection, non-linear activation, and up-projection layers, significantly reducing the number of trainable parameters compared to full fine-tuning. Consequently, CLARE facilitates efficient knowledge transfer and avoids the performance degradation associated with overwriting existing knowledge during sequential learning.
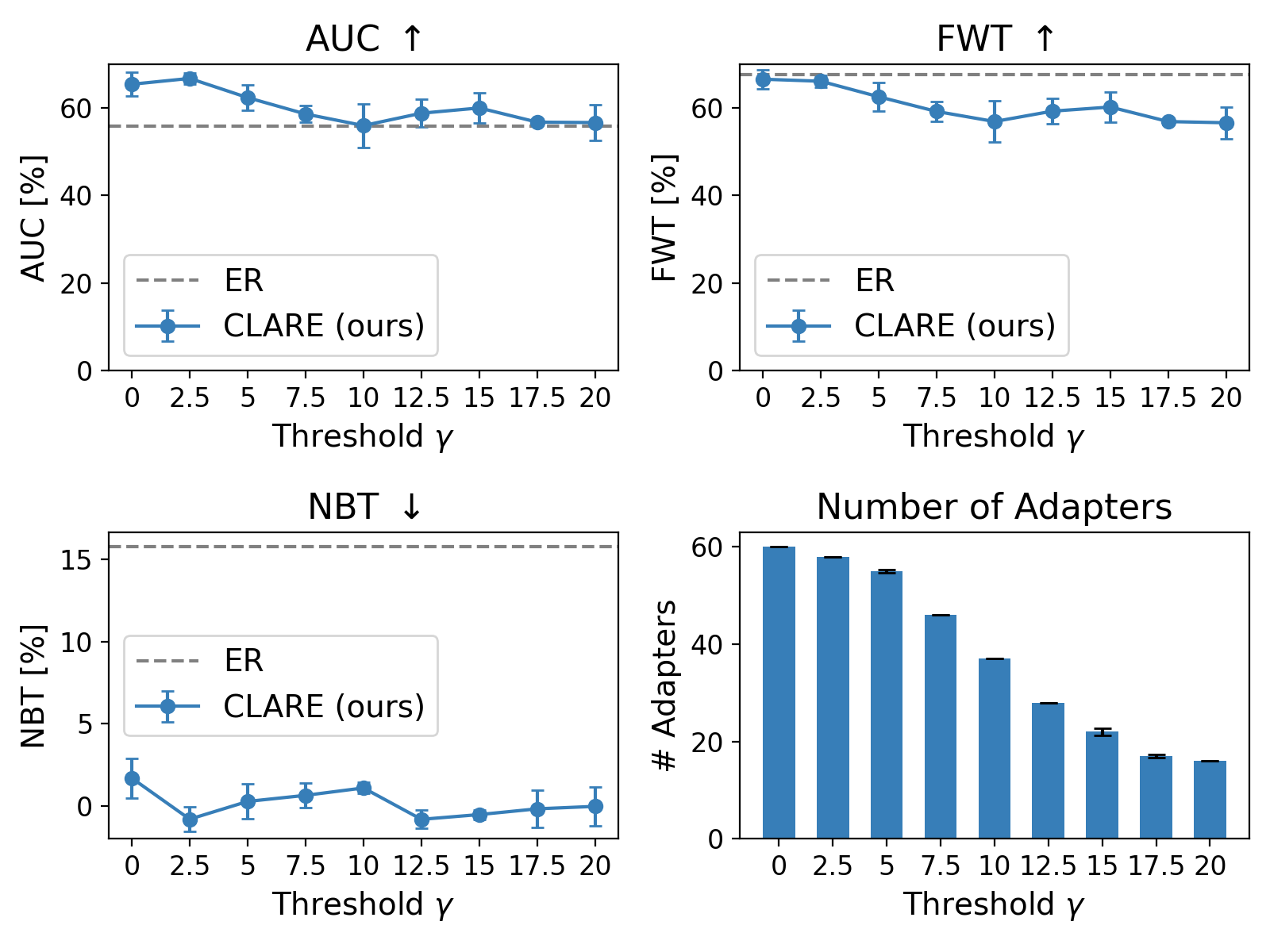
The CLARE framework utilizes a dynamic expansion strategy for adapter allocation, prioritizing resource efficiency. New adapters are added to the Vision-Language-Action Model (VLA) only upon detection of feature novelty in incoming data. This is achieved by monitoring the model’s internal feature representations; if an input exhibits features significantly different from those encountered during previous training, a new adapter is instantiated. This approach avoids the addition of redundant parameters for familiar data, limiting model growth and computational cost. Consequently, the system adapts to new tasks and data distributions without incurring the overhead of continually expanding the parameter space with unnecessary adapters.
Adapter selection within CLARE utilizes an autoencoder-based routing mechanism to dynamically determine the most appropriate adapter for each incoming input. This process involves encoding the input features into a latent space and then calculating the similarity between this latent representation and the learned embeddings of each adapter. The adapter with the highest similarity score is then activated, facilitating knowledge transfer specific to the input’s characteristics. This intelligent routing strategy avoids the need for all adapters to process every input, reducing computational cost and enhancing performance by focusing on task-relevant expertise. The autoencoder is trained to produce discriminative embeddings, ensuring that adapters are selected based on genuine feature novelty and task alignment, thereby promoting robust generalization across diverse tasks.
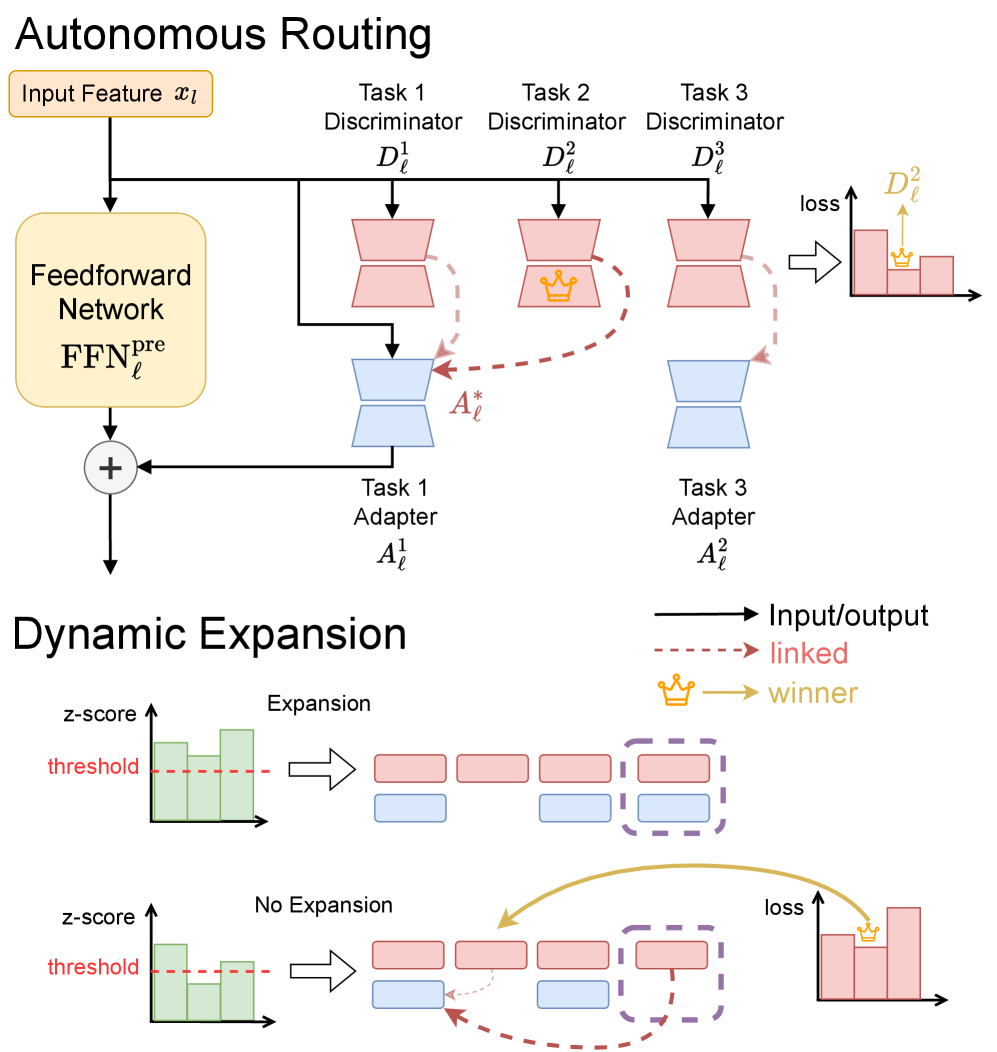
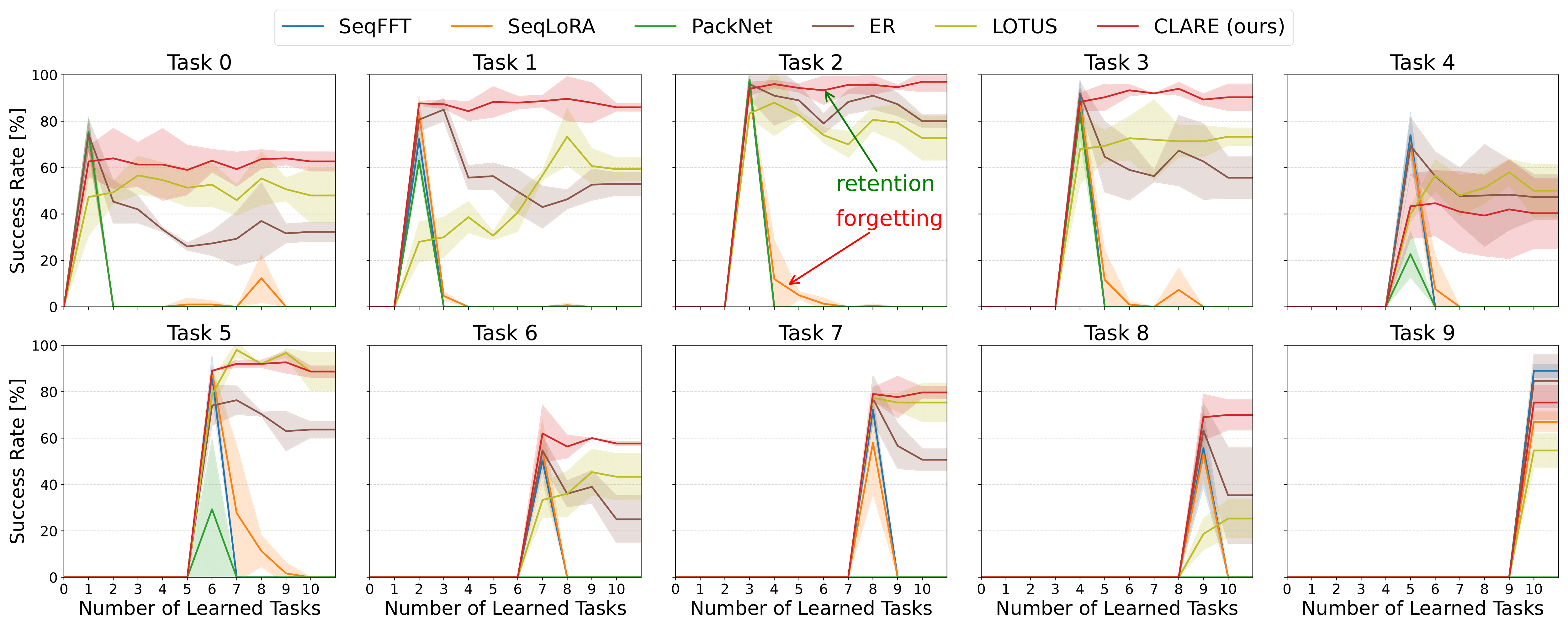
Empirical Validation: Performance on the LIBERO Benchmark
On the LIBERO benchmark, the CLARE method demonstrates statistically significant performance gains when compared to established continual learning techniques. Specifically, CLARE consistently surpasses Sequential Fully Fine-tuning (SeqFFT), Sequential Low-Rank Adaptation (SeqLoRA), and Experience Replay (ER) across key evaluation metrics. These results indicate CLARE’s enhanced ability to both acquire new skills and maintain performance on previously learned tasks, establishing it as a leading approach for continual learning scenarios where retaining prior knowledge is critical.
CLARE’s performance on the LIBERO benchmark is quantified by several key metrics demonstrating both forward and backward transfer capabilities. The Area Under the Success Rate Curve (AUC) for CLARE reaches 65%, indicating a strong ability to successfully learn new tasks. Comparative analysis shows CLARE outperforms the Experience Replay baseline by approximately 11-15% based on AUC measurements. Furthermore, CLARE exhibits positive Forward Transfer (FWT) at 67%, and minimizes Negative Backward Transfer (NBT), approaching a value of zero, indicating a low rate of catastrophic forgetting when learning subsequent tasks.
CLARE utilizes Diffusion Transformers (DiT) as its foundational policy, incorporating DINOv2 for visual feature extraction and CLIP for aligning visual and language embeddings; this architecture contributes to enhanced robustness and generalization. Performance evaluations on continual learning tasks demonstrate CLARE’s ability to minimize catastrophic forgetting, evidenced by a Negative Backward Transfer (NBT) value approaching zero. Furthermore, CLARE achieves a Forward Transfer rate of 67%, a result statistically comparable to that of Sequential Fully Fine-tuning (SeqFFT), indicating effective knowledge transfer between tasks.
CLARE exhibits high parameter efficiency during continual learning, increasing the total number of parameters by only 1.7% to 2.3% with the addition of each new task. This minimal parameter growth is a key characteristic of the model, contrasting with methods that require substantial parameter updates or the storage of entire models for each task. The low parameter overhead contributes to CLARE’s scalability and makes it suitable for deployment in resource-constrained environments, while maintaining performance comparable to methods with significantly higher parameter demands.
Beyond Robotics: Implications for Adaptive Intelligence
The persistent challenge of catastrophic forgetting – where newly learned information overwrites previously acquired knowledge – has long hindered the development of truly adaptable robots. However, the CLARE framework demonstrably mitigates this issue, paving the way for robots capable of operating effectively in complex, real-world scenarios. Unlike traditional machine learning models, CLARE allows robots to continuously learn from experience without sacrificing previously established skills. This is achieved through a dynamic network expansion strategy, enabling the addition of new knowledge without disrupting core competencies. Consequently, robots equipped with CLARE can navigate unpredictable environments, respond to novel situations, and refine their performance over time, representing a significant step towards robust and versatile autonomous systems.
The architecture leverages a dynamic expansion strategy within the Feedforward Networks (FFNs) of transformer models to achieve computationally efficient lifelong learning. Unlike traditional approaches that require retraining the entire network with each new task – a process demanding significant resources – this framework selectively expands the FFNs only when encountering novel information. This targeted growth allows the model to accommodate new knowledge without drastically increasing computational demands or succumbing to catastrophic forgetting – the tendency to lose previously learned information. By intelligently scaling network capacity based on incoming data complexity, the system maintains a balance between learning new skills and preserving existing ones, representing a significant step towards truly adaptive and sustainable artificial intelligence.
The principles underpinning CLARE extend significantly beyond the realm of robotics, offering a powerful solution for continual learning challenges across diverse fields. Consider personalized medicine, where adapting to a patient’s evolving health profile requires systems that can integrate new data without forgetting crucial past information; CLARE’s dynamic expansion strategy could enable models to refine diagnoses and treatment plans over a patient’s lifetime. Similarly, in autonomous systems – ranging from self-driving vehicles navigating changing road conditions to financial algorithms responding to market fluctuations – the ability to learn continuously and avoid catastrophic forgetting is paramount for reliable, long-term performance. This framework, therefore, provides a versatile architecture for any application demanding adaptive intelligence and robust knowledge retention in the face of ever-changing data streams.
The pursuit of continual learning, as demonstrated by CLARE, mirrors a fundamental principle of efficient systems. It prioritizes adaptation over wholesale reconstruction. This framework’s strategic addition of adapter modules, guided by feature similarity, embodies a minimalist approach to knowledge integration. Alan Turing observed, “Sometimes people who are unhappy tend to look at the world as if there is something wrong with it.” CLARE addresses a similar ‘wrongness’ – the inherent limitations of static models in a dynamic world – by continually refining its understanding through targeted expansion, rather than attempting a complete overhaul. The system achieves increased capability without sacrificing previously learned skills; clarity is the minimum viable kindness.
What Remains?
The proliferation of parameters, even when neatly arranged as ‘adapters’, remains a symptom, not a solution. CLARE rightly addresses the issue of continual learning, but the underlying assumption – that accumulating specialized modules approximates genuine intelligence – warrants further scrutiny. A system that requires ever-expanding architecture has, in a fundamental sense, failed to distill knowledge. The true test lies not in how much a model can learn, but in how little it needs to store.
Future work must prioritize mechanisms for functional abstraction. Feature similarity, as employed here, is a pragmatic approximation, but ultimately insufficient. The field should pursue methods that allow for the re-purposing of existing representations, rather than simply adding new ones. A genuinely robust system should demonstrate a diminishing return on added complexity, approaching a point of asymptotic performance.
The focus on robotic action, while grounding the research, also introduces inherent limitations. The messiness of the physical world provides convenient excuses for imperfect learning. A more revealing test would be to apply these principles to domains of pure information – to see if the system can achieve continual learning without the crutch of perceptual ambiguity. Clarity, after all, is courtesy; and a system that requires ever-increasing complexity is rarely extending any.
Original article: https://arxiv.org/pdf/2601.09512.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- How to find the Roaming Oak Tree in Heartopia
- World Eternal Online promo codes and how to use them (September 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Best Arena 9 Decks in Clast Royale
- ATHENA: Blood Twins Hero Tier List
- Brawl Stars December 2025 Brawl Talk: Two New Brawlers, Buffie, Vault, New Skins, Game Modes, and more
- Clash Royale Furnace Evolution best decks guide
- What If Spider-Man Was a Pirate?
2026-01-15 21:28