Author: Denis Avetisyan
Researchers have unveiled a comprehensive simulation suite designed to push the boundaries of continual reinforcement learning in robotics, addressing the challenge of catastrophic forgetting.
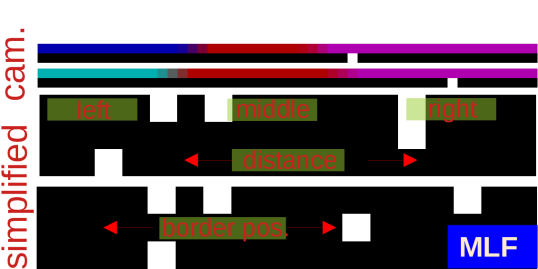
![The robot’s capacity to navigate complex tasks is demonstrated through benchmarks assessing both object manipulation-approaching geometrically varied shapes using forward-facing [latex]RGB[/latex] vision-and precision locomotion, where adherence to centered lines on a colored ground plane is achieved with a downwards-facing line camera, highlighting an adaptable sensing strategy for differing operational demands.](https://arxiv.org/html/2602.04868v1/figs/lf2.png)
CRoSS, a scalable robotic simulation suite, offers high task diversity and realistic physics to enable robust and transferable continual learning.
Existing continual reinforcement learning benchmarks often lack the task diversity and physical realism needed to thoroughly evaluate agents in complex robotic environments. To address this, we introduce ‘CRoSS: A Continual Robotic Simulation Suite for Scalable Reinforcement Learning with High Task Diversity and Realistic Physics Simulation’, a new suite built on the Gazebo simulator featuring both differential-drive mobile robots and seven-joint robotic arms. CRoSS enables controlled studies of continual learning with variations in visual parameters, object configurations, and control schemes-including both Cartesian and joint-angle based control-while offering fast, kinematics-only simulation options. Will this suite facilitate the development of more robust and adaptable continual learning algorithms capable of deployment in real-world robotic systems?
The Inevitable Drift: Confronting Catastrophic Forgetting
Traditional reinforcement learning algorithms demonstrate remarkable proficiency when applied to isolated tasks, achieving high performance through focused training. However, this success diminishes rapidly when confronted with the demand for continual learning – the ability to acquire new skills without erasing previously learned ones. This phenomenon, known as catastrophic forgetting, arises because standard algorithms update their internal parameters in a way that overwrites existing knowledge as they adapt to new information. Essentially, the robot ‘forgets’ how to perform older tasks as it masters new ones, creating a significant impediment to deploying robots in real-world scenarios requiring ongoing adaptation and a growing repertoire of skills. The core issue isn’t an inability to learn, but rather a lack of mechanisms to preserve valuable knowledge while embracing novelty, hindering the development of truly autonomous and versatile robotic systems.
The effective deployment of robots in real-world settings demands a capacity for continual learning – the ability to acquire new skills and adapt to evolving environments without succumbing to catastrophic forgetting. Unlike traditional machine learning approaches optimized for static tasks, a functional robot must build upon prior experience, retaining previously learned behaviors while seamlessly integrating new information. This presents a significant challenge, as neural networks, the foundation of many robotic control systems, often overwrite existing knowledge when trained on new data. Consequently, research focuses on developing techniques – such as experience replay, regularization methods, and modular network architectures – that allow robots to incrementally expand their skillset, preserving past learning and ensuring robust performance across a lifetime of operation in dynamic, unpredictable circumstances.
Robotic systems designed with current machine learning techniques frequently exhibit diminished performance when tasked with sequential learning – the ability to master new skills without forgetting established ones. This fragility stems from a lack of robustness and efficiency in handling the constantly shifting demands of complex, real-world environments. Studies reveal that as robots are exposed to successive tasks, previously learned behaviors degrade, a phenomenon known as catastrophic forgetting. Consequently, these systems struggle to operate autonomously in dynamic scenarios, requiring frequent retraining or intervention to maintain acceptable performance levels. Addressing this limitation is paramount to unlocking the full potential of robotics and enabling truly adaptive, intelligent machines capable of navigating and responding to the unpredictable nature of everyday life.
CRoSS: A Controlled Descent into Complexity
CRoSS is a benchmarking suite built on the Gazebo simulator, designed to assess continual reinforcement learning (CRL) algorithms. The environment provides a physically realistic simulation with varied scenes, lighting conditions, and object configurations to challenge agent generalization. The suite incorporates procedural content generation to create a diverse set of tasks and scenarios, exceeding the limitations of static, pre-defined environments commonly used in RL evaluation. This focus on dynamic complexity and environmental variation aims to better reflect the challenges of real-world robotic deployments and rigorously test an agent’s ability to learn and adapt over time without catastrophic forgetting.
The CRoSS benchmark suite incorporates two distinct robotic platforms: a two-wheeled differential-drive robot and a 7-degree-of-freedom robotic arm. This design choice facilitates evaluation of continual reinforcement learning algorithms across a broad spectrum of robotic morphologies and kinematic complexities. The differential-drive robot represents a simpler, mobile base commonly used in logistics and service applications, while the 7-d.o.f. arm introduces challenges related to manipulation, dexterity, and high-dimensional action spaces. By testing algorithms on both platforms, CRoSS provides insights into their generalizability and performance across different robotic systems and operational requirements.
CRoSS differentiates itself from traditional Reinforcement Learning (RL) benchmarks by emphasizing continual learning in dynamic environments. Unlike standard RL setups that typically focus on a single task, CRoSS presents agents with a sequence of distinct tasks, each requiring unique skills and strategies. Critically, agents are not permitted to revisit previously encountered environments or utilize data collected from prior tasks during the learning process for new tasks; this necessitates robust methods for knowledge transfer and adaptation without catastrophic forgetting. This sequential learning paradigm more accurately reflects real-world robotic applications where robots must continuously adapt to changing circumstances and learn new skills over time, without the benefit of retraining on previously mastered tasks.
The CRoSS benchmark utilizes Apptainer, a lightweight containerization tool, to simplify installation and ensure reproducible experimental setups across different systems. This addresses challenges associated with dependency management and differing software versions. Robot control and communication within the simulated environments are managed through the Robot Operating System (ROS), a widely adopted framework in robotics research. ROS provides a standardized interface for accessing robot sensors and actuators, as well as tools for message passing and data logging, facilitating modularity and interoperability within the CRoSS framework.
Diverse Tasks: Stress-Testing Robotic Resilience
The CRoSS benchmark suite includes the tasks of Multi-Task Line Following and Multi-Task Pushing Objects to specifically assess a robot’s ability to generalize and adapt to varying objectives within a single environment. Line Following requires the robot to navigate a predefined path, testing its path planning and low-level motor control. Multi-Task Pushing Objects challenges the robot to manipulate multiple objects with differing physical properties, evaluating its grasp planning, force control, and ability to switch between tasks. These tasks are designed to move beyond single-skill benchmarks and evaluate performance in more complex, real-world scenarios requiring flexible behavior and task switching capabilities.
The CRoSS benchmark for robotic arm manipulation incorporates both low-level and high-level reaching tasks to assess a range of control strategies. Low-level reaching utilizes joint space control, where the robot directly manipulates its joint angles to reach a target. Conversely, high-level reaching employs Cartesian control, specifying the desired end-effector position and orientation in 3D space, allowing the robot’s internal controllers to determine the necessary joint movements. This dual approach enables evaluation of algorithms operating directly on joint commands versus those utilizing higher-level, task-space planning, providing a comprehensive assessment of robotic arm control capabilities.
Kinematic simulation is a core component of the CRoSS benchmark, enabling researchers to conduct a high volume of experiments and rapidly iterate on algorithm designs without the constraints of real-world robotic hardware. This approach utilizes physics engines to model the robot’s dynamics and environment, allowing for parallelized testing and efficient parameter tuning. Simulated environments facilitate the collection of large datasets, critical for training reinforcement learning algorithms, and provide a safe and repeatable platform for evaluating performance across diverse tasks. The use of simulation significantly reduces the time and cost associated with physical experimentation, accelerating the development and validation of new robotic control strategies.
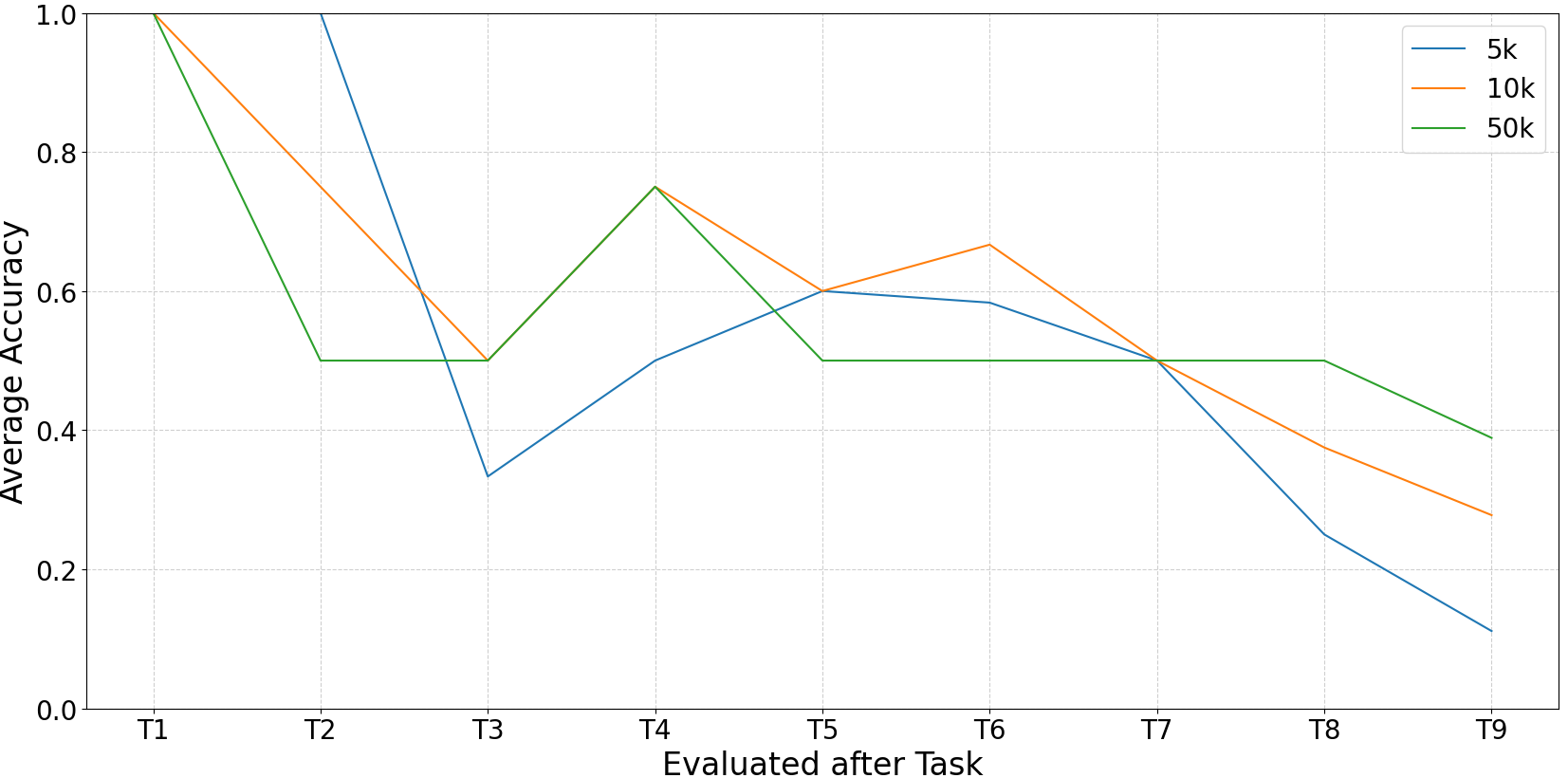
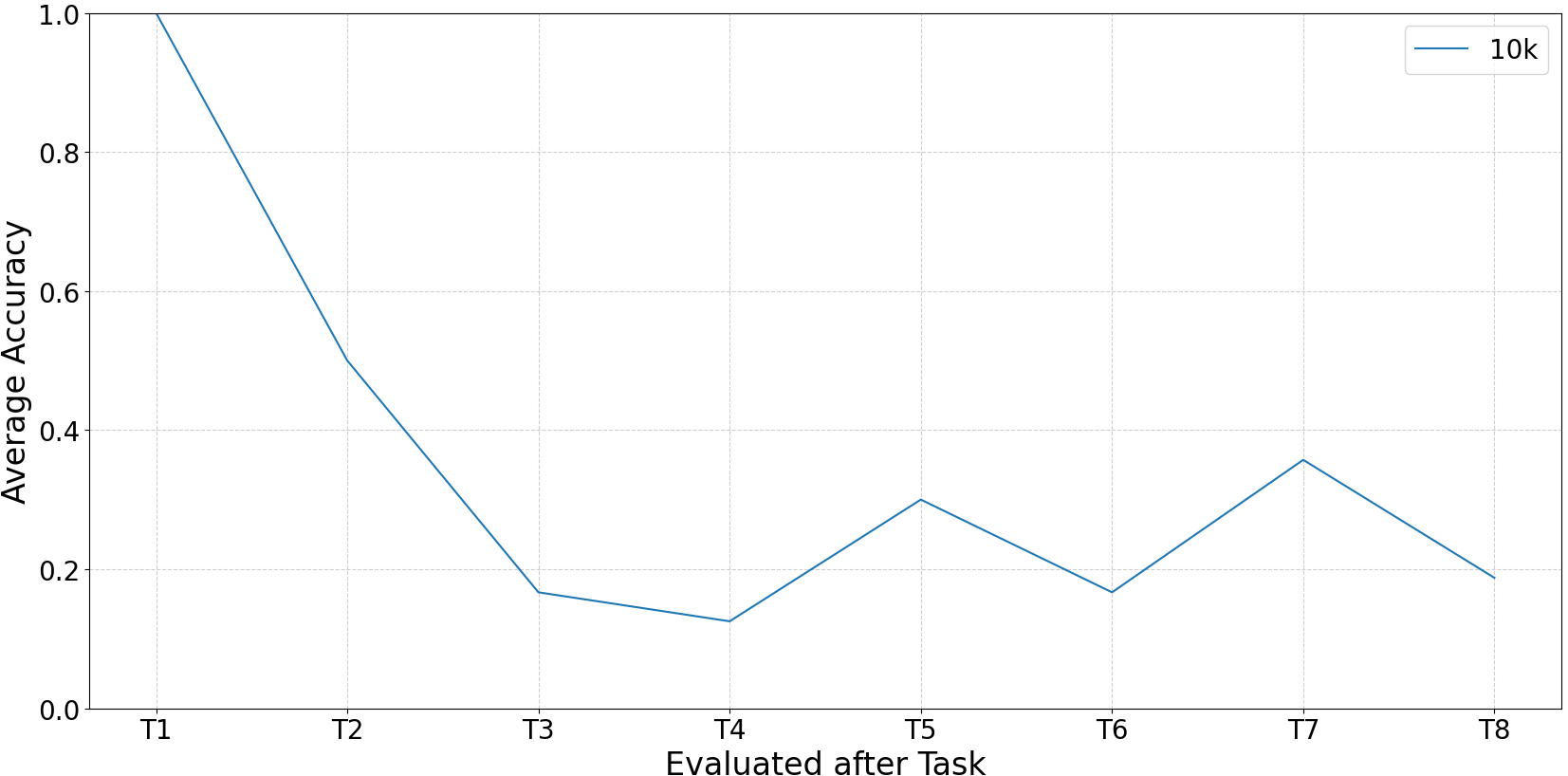
The CRoSS benchmark employs Deep Q-Networks (DQN) and REINFORCE as foundational reinforcement learning algorithms, augmented with reward shaping techniques to accelerate learning and improve initial performance across diverse tasks. Experimental results consistently demonstrate a decline in performance as the number of sequentially learned tasks increases; this degradation indicates the presence of catastrophic forgetting, where the acquisition of new skills negatively impacts retention of previously learned skills. While increasing replay buffer sizes from 5000 to 10000 or 20000 samples provides a marginal improvement in task retention, the overall trend of performance decline with each added task remains significant, emphasizing the need for more robust continual learning strategies.
Evaluation of replay buffer size demonstrated a correlation between capacity and retention of previously learned skills during multi-task learning. Specifically, robotic agents trained with replay buffers of 10,000 and 20,000 experiences exhibited marginally improved performance on previously mastered tasks compared to those utilizing a buffer size of 5,000 experiences. However, despite this slight improvement, all buffer sizes experienced performance degradation as new tasks were introduced, indicating that increased buffer capacity alone does not fully mitigate the problem of catastrophic forgetting in continuous learning scenarios.
CRoSS: Forging a Path Toward Adaptable Intelligence
The continual reinforcement learning field benefits significantly from the introduction of CRoSS, a benchmark designed to standardize and enhance reproducibility in robotic research. Prior to CRoSS, evaluating and comparing continual learning algorithms proved challenging due to a lack of common ground and consistent testing procedures. This benchmark addresses that issue by offering a unified platform with diverse and realistically complex robotic tasks. By providing a shared environment, CRoSS facilitates direct comparison of algorithms, accelerates the pace of innovation, and fosters greater collaboration among researchers. The availability of a standardized benchmark is expected to streamline the development of more robust and adaptable robotic systems capable of lifelong learning in dynamic, real-world scenarios.
The CRoSS benchmark isn’t simply a test of existing robotic algorithms; it’s designed to actively challenge them. By incorporating a diverse set of tasks – ranging from object manipulation to locomotion – and grounding these within a physically realistic simulation, CRoSS exposes the limitations of current approaches to continual learning. This deliberate push for realism, encompassing factors like friction, joint limits, and sensor noise, forces researchers to move beyond idealized scenarios and develop systems that can truly cope with the messiness of the real world. Consequently, the benchmark is driving innovation in areas like meta-learning, transfer learning, and experience replay, ultimately fostering the creation of robotic systems demonstrably more robust, adaptable, and capable of sustained performance in dynamic and unpredictable environments.
A central hurdle in creating truly intelligent robots lies in overcoming “catastrophic forgetting,” the tendency for machine learning models to abruptly lose previously learned skills when exposed to new information. The CRoSS benchmark directly confronts this challenge by providing a continual reinforcement learning environment where robotic agents must sequentially master diverse tasks without forgetting earlier ones. This sustained learning paradigm compels the development of algorithms that can retain knowledge while adapting to change, mirroring the adaptability seen in biological systems. Consequently, robots evaluated on CRoSS are not simply trained for a single purpose; instead, they exhibit the capacity to accumulate skills over time, improving performance and maintaining proficiency even as the environment and task demands evolve – a crucial step towards deployment in real-world, dynamic settings.
The development of continually learning robots, as facilitated by benchmarks like CRoSS, promises to reshape industries reliant on adaptable automation. In manufacturing, robots capable of continuously refining their processes could optimize production lines and reduce defects, while in logistics, they offer the potential for flexible warehouse management and delivery systems capable of responding to real-time demands. Perhaps most critically, the ability for robots to learn and adapt without explicit reprogramming is invaluable in unpredictable environments such as search and rescue operations, where navigating debris, locating victims, and responding to changing conditions requires a level of autonomy and resilience currently beyond the reach of most robotic systems. This advancement signifies a move towards robotic solutions that aren’t simply programmed for specific tasks, but can intelligently evolve and improve their performance over time, unlocking a new era of robotic versatility and effectiveness.
Recent investigations utilizing the CRoSS benchmark reveal a counterintuitive relationship between action space granularity and learning success in continual reinforcement learning for robotics. While increased precision might seem beneficial, results demonstrate that expanding the discrete action space – specifically, increasing the number of possible joint angles from five to nine – significantly hinders a robot’s ability to learn and adapt. Only two out of eight tested tasks were successfully completed with the higher granularity, a stark contrast to the successful learning observed with the coarser, five-angle action space. This suggests that an overly detailed action space introduces complexity that current algorithms struggle to navigate effectively, potentially leading to increased exploration challenges and slower convergence rates – highlighting a critical need for algorithms that can efficiently manage high-dimensional action spaces or benefit from carefully designed action abstractions.
The development of CRoSS, as detailed in the article, implicitly acknowledges the inevitable decay inherent in any complex system. While striving for scalable reinforcement learning and robust task diversity, the benchmark suite functions within the constraints of simulated physics and algorithmic limitations. This echoes Paul Erdős’ sentiment: “A mathematician knows a lot of things, but not everything.” CRoSS doesn’t claim to solve continual learning-it provides a platform to explore its challenges, acknowledging the inherent ‘latency’ in achieving true generalization and sim-to-real transfer. The suite, therefore, isn’t about achieving a static, perfect solution, but rather a framework for navigating the ongoing flux of robotic learning, accepting that stability is, indeed, a temporary illusion cached by time.
What Lies Ahead?
The introduction of CRoSS marks not an arrival, but a recalibration. Existing benchmarks, for all their utility, operate under the illusion of static challenges. CRoSS acknowledges the inevitable: systems, even simulated ones, are subject to the relentless pressure of temporal drift. Each new task isn’t merely an addition to a skill set, but a point of potential fracture, a moment where the past-the painstakingly learned policies-must negotiate with the present. Every bug revealed within the suite is, in essence, a moment of truth in the timeline of continual learning.
The true test will not be achieving high average performance across a diverse set of tasks, but in gracefully accommodating the accrual of technical debt. This suite, with its emphasis on realistic physics and potential for sim-to-real transfer, implicitly asks how much of the past can be salvaged as the present demands adaptation. The focus must shift from simply doing more, to remembering effectively while doing.
Future iterations will inevitably reveal the limits of current approaches to catastrophic forgetting. The question isn’t whether forgetting will occur – it always does – but whether systems can be engineered to forget elegantly, to shed obsolete knowledge without compromising core competencies. The longevity of any robotic intelligence will be measured not by its initial prowess, but by its capacity to age gracefully within a constantly evolving world.
Original article: https://arxiv.org/pdf/2602.04868.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
2026-02-06 03:16