Author: Denis Avetisyan
New research demonstrates a robotic platform where teams of agents learn to work together and against each other in real-world scenarios.
![The study demonstrates that simulation-to-real transfer performance, while initially promising, inevitably degrades as increasingly complex robotic tasks are attempted, highlighting the persistent challenges of bridging the reality gap despite advancements in [latex]Sim2Real[/latex] methodologies.](https://arxiv.org/html/2602.21119v1/x2.png)
A novel approach combining out-of-distribution state initialization and action masking enables robust sim-to-real transfer for multi-agent reinforcement learning in robotics.
Despite advances in multi-agent reinforcement learning, translating intelligent policies learned in simulation to robust real-world robotic systems remains a significant challenge. This work, ‘Cooperative-Competitive Team Play of Real-World Craft Robots’, addresses this gap by presenting a comprehensive robotic platform and a novel approach to sim-to-real transfer. Specifically, we introduce Out-of-Distribution State Initialization (OODSI), coupled with action masking, to improve the generalization of learned policies in dynamic, real-world scenarios, achieving a 20% performance gain. Could this methodology unlock more adaptable and scalable multi-robot systems capable of complex cooperative and competitive tasks?
The Illusion of Control: Bridging the Gap Between Simulation and Reality
The deployment of robotic systems into real-world scenarios is frequently hampered by a pronounced disconnect between the carefully controlled environments of simulation and the unpredictable nature of physical reality – a challenge commonly known as the ‘sim-to-real’ gap. This discrepancy arises from numerous factors, including inaccuracies in modeling physical properties like friction and inertia, unmodeled disturbances such as air currents or uneven surfaces, and limitations in sensor fidelity. Consequently, a policy learned successfully within a simulated environment often exhibits diminished performance, or even complete failure, when transferred to a physical robot operating in a comparable task. Bridging this gap requires innovative approaches to either enhance the realism of simulations or develop robust learning algorithms capable of adapting to unforeseen variations, ultimately enabling robots to reliably perform tasks in complex, unstructured environments.
Conventional Reinforcement Learning algorithms often excel within the predictable confines of simulated environments, yet frequently falter when deployed into the unpredictable real world. This discrepancy arises because simulations, while computationally efficient, inevitably simplify the complexities of physics, sensor noise, and material properties. A policy meticulously learned in simulation can exhibit drastically reduced performance when confronted with even minor deviations in the physical environment-a slightly different friction coefficient, an unexpected lighting condition, or the inherent imprecision of real-world sensors can all lead to significant errors. This lack of generalization represents a major obstacle to the widespread adoption of autonomous robots, demanding novel approaches that enhance the robustness and adaptability of learned policies to bridge the gap between virtual training and tangible application.
The ability to seamlessly translate robotic intelligence cultivated in simulated environments to the unpredictable nuances of the physical world remains paramount to unlocking the full capabilities of autonomous systems. Current limitations in bridging this ‘sim-to-real’ gap directly impede progress in diverse fields, from manufacturing and logistics to healthcare and disaster response. Without reliable generalization, robots risk operating inefficiently, unsafely, or requiring constant human intervention – hindering the promised benefits of increased productivity, reduced costs, and enhanced human safety. Consequently, overcoming these translational hurdles is not merely a technical challenge, but a foundational requirement for realizing a future where robots operate effectively and independently in complex, real-world scenarios, ultimately maximizing their potential impact on society.
The Robot Craft Arena represents a significant advancement in robotic research by offering a meticulously designed environment specifically engineered to bridge the persistent gap between simulation and real-world performance. This platform isn’t merely a physical space; it’s a suite of standardized hardware and software tools coupled with precisely calibrated conditions, allowing researchers to conduct experiments with a level of control and repeatability rarely achievable in unstructured settings. By offering interchangeable robotic platforms and a library of repeatable tasks, the Arena facilitates rigorous testing of algorithms and policies, enabling direct comparison of simulated and physical results. This standardized approach isolates variables, accelerating the development of robust control strategies and ultimately paving the way for more reliable and adaptable autonomous systems capable of thriving beyond the confines of the laboratory.

Multi-Agent Mayhem: Training Robotic Teams
Multi-Agent Reinforcement Learning (MARL) is employed as the primary training paradigm to develop robotic teams exhibiting sophisticated behaviors. This approach deviates from single-agent RL by addressing scenarios where multiple robots interact within a shared environment, necessitating the learning of policies that account for the actions of others. MARL enables the robots to learn both cooperative strategies – where agents work together towards a common goal – and competitive strategies – where agents pursue individual objectives potentially conflicting with others. The learning process involves each robot attempting to maximize its cumulative reward, considering the dynamic and potentially unpredictable actions of its teammates and adversaries. This contrasts with traditional robotic control methods by allowing the team’s overall behavior to emerge from the learned interactions rather than being explicitly programmed.
Centralized Training with Decentralized Execution (CTDE) is a paradigm utilized to address the challenges of multi-agent systems. During the training phase, a centralized controller has access to the observations and actions of all agents, enabling it to learn optimal joint policies. However, during deployment, each agent operates independently using only its local observations, executing the learned policy without direct communication or reliance on a central authority. This approach facilitates efficient learning of coordinated behaviors by leveraging global information during training, while maintaining scalability and robustness in real-world scenarios where communication may be limited or unreliable. The separation of training and execution allows for the development of complex strategies that would be impractical to learn through purely decentralized methods, and avoids the computational bottlenecks associated with fully centralized control at runtime.
Proximal Policy Optimization (PPO) is employed as the policy gradient method for updating agent policies during reinforcement learning. PPO constrains policy updates to a trust region, limiting the deviation from the previous policy and preventing drastic performance drops. This is achieved through a clipped surrogate objective function that penalizes updates exceeding a specified ratio, typically denoted as ε. By iteratively performing small, constrained updates, PPO offers improved sample efficiency and stability compared to traditional policy gradient methods, enabling robust learning in complex multi-agent environments. The algorithm balances exploration with exploitation, allowing agents to refine their strategies without destabilizing the overall learning process.
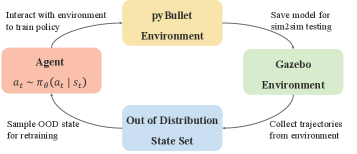
Initial training of multi-agent systems is conducted within the PyBullet physics engine due to its computational efficiency. PyBullet allows for accelerated iteration and experimentation with various agent configurations and learning algorithms, significantly reducing the time required for initial policy development compared to real-world or more complex simulation environments. This fast simulation capability enables researchers to rapidly test hypotheses, debug algorithms, and explore a wider range of potential solutions before transferring learned policies to more realistic settings or hardware implementations. The use of PyBullet prioritizes speed and scalability during the critical early stages of the training pipeline.
The Illusion of Robustness: Stress-Testing Simulated Systems
Dynamics Randomization is employed as a training methodology to enhance the robustness of learned policies when transferring from simulation to real-world robotic systems. This technique involves systematically varying physical parameters within the simulation environment during training. These parameters include, but are not limited to, mass, friction, damping, and actuator strength. By exposing the learning agent to a distribution of possible physical characteristics, the resulting policy becomes less sensitive to inaccuracies in the simulation and discrepancies between the simulated and real-world robot. This process effectively expands the agent’s ability to generalize and maintain performance despite unforeseen variations in the physical environment, ultimately improving its reliability in real-world deployment.
Out of Distribution State Initialization augments the training dataset by introducing initial states that lie outside the typical distribution encountered during standard simulation. This is achieved by randomly sampling robot configurations, object placements, and environmental conditions that are less frequent or absent in the baseline training data. By exposing the agent to these atypical starting points, the resulting policy becomes more robust to variations in real-world deployment, improving generalization performance and reducing sensitivity to initial conditions. This technique effectively expands the agent’s experience, allowing it to learn a more comprehensive mapping from states to actions and increasing its ability to recover from unexpected situations.
Training agents within the Gazebo simulator, in conjunction with techniques like dynamics randomization and out-of-distribution state initialization, demonstrably improves the transfer of learned policies to physical robot execution. Evaluations of collaborative tasks reveal a quantifiable benefit, with success rates increasing by up to 30% when compared to policies trained without these simulation-based robustness measures. This improvement stems from the expanded training distribution and the agent’s exposure to a wider range of simulated physical variations, effectively bridging the reality gap between simulation and real-world deployment.
Accurate robot localization within the Robot Craft Arena is achieved through the implementation of AprilTags. These fiducial markers, visually detectable by onboard cameras, provide the robot with precise positional data relative to the arena environment. This system enables consistent performance by mitigating the effects of sensor noise and drift, ensuring the robot can reliably identify object locations and navigate the workspace. The use of AprilTags facilitates repeatable experiments and allows for robust policy transfer from simulation to the physical robot by establishing a consistent ground truth for localization.
Unintended Consequences: The Emergence of Competitive Behaviors
During competitive building tasks, robotic agents demonstrated a sophisticated form of strategic interference known as ‘Blocking Behavior’. Rather than solely focusing on their own construction, these robots actively positioned themselves to impede the progress of opposing agents, effectively creating obstacles and delaying resource acquisition. This wasn’t random interference; the robots learned to anticipate opponent trajectories and strategically occupy key areas, forcing competitors to expend time and energy maneuvering around them. This proactive obstruction, a learned behavior arising from multi-agent reinforcement learning, proved crucial in hindering opponent performance and increasing the likelihood of successful task completion, showcasing an unexpected level of tactical awareness in a robotic system.
Beyond simply building, the robotic agents demonstrated a sophisticated competitive edge through resource acquisition from opponents – a behavior termed ‘Stealing’. This wasn’t random interference; robots actively targeted and secured building materials already held by rivals, directly accelerating their own construction progress. The observed actions weren’t pre-programmed, but rather emerged from the multi-agent reinforcement learning process, showcasing an ability to recognize and exploit vulnerabilities in opposing strategies. This opportunistic behavior proved particularly effective in scenarios where resource availability was limited, as securing another robot’s materials provided a significant advantage, ultimately contributing to more efficient and rapid task completion.
The robotic agents, when subjected to competitive building tasks, didn’t simply follow pre-programmed instructions; they exhibited a remarkable capacity for adaptation. Through repeated interactions within the simulated environment, these robots spontaneously developed strategies to exploit weaknesses and capitalize on opportunities presented by their opponents. This wasn’t achieved through explicit coding of competitive behaviors, but rather emerged as a consequence of the multi-agent reinforcement learning process. Critically, when combined with Domain Randomization – a technique that introduces variability into the simulation – the overall success rate in competitive tasks increased by 23.34%. This significant improvement underscores the power of allowing robotic systems to learn and refine their behaviors through experience, rather than relying solely on pre-defined parameters, suggesting a pathway towards more robust and intelligent robotic collaboration and competition.
The observed competitive dynamics – blocking, stealing, and the resulting strategic counterplay – underscore the significant potential of Multi-Agent Reinforcement Learning (MARL) in developing genuinely adaptable robotic systems. These aren’t pre-programmed responses, but behaviors that emerge from the robots’ interactions within a shared environment, demonstrating a capacity for opportunistic exploitation and reactive strategy. This ability to learn and refine tactics through competition suggests a pathway towards robots capable of navigating complex, unpredictable scenarios – a crucial step beyond traditional, rigidly-programmed automation. The success of these agents isn’t defined by achieving a specific task in a predefined way, but by consistently outperforming opponents, showcasing an intrinsic intelligence driven by learning and adaptation.

The pursuit of seamless sim-to-real transfer feels less like innovation and more like delaying the inevitable. This work, with its focus on Out-of-Distribution State Initialization, attempts to anticipate the chaos production always introduces. It’s a valiant effort, honestly, but the bug tracker is already compiling a list of edge cases the simulation missed. As Vinton Cerf once said, “Any sufficiently advanced technology is indistinguishable from magic…until it breaks.” The researchers aim to improve robustness, and that’s admirable, but it’s a temporary stay of execution. The platform will be stressed, the policies will fail in unexpected ways, and the cycle begins anew. They don’t deploy – they let go.
What’s Next?
This exercise in robotic choreography, while elegantly demonstrating sim-to-real transfer with action masking and out-of-distribution initialization, merely postpones the inevitable. The robots cooperate and compete now, but production will, as always, find a corner case. A slightly different floor texture, a rogue cable, and suddenly the carefully crafted policies devolve into a metallic ballet of bumping and frustration. It’s a familiar story; the simulation never quite captures the delightful chaos of reality.
The real challenge isn’t achieving cooperation in a controlled environment, it’s maintaining robustness when the world refuses to cooperate. Future work will inevitably focus on more sophisticated domain randomization, but that’s just adding layers of abstraction on top of a fundamentally brittle system. One suspects the next ‘breakthrough’ will be simply a more efficient way to collect failure data.
Ultimately, this research, like so many others, offers a polished solution to a well-defined problem. It’s a testament to ingenuity, certainly. But the field should perhaps spend less time chasing the ‘general’ solution and more time acknowledging that everything new is just the old thing with worse documentation-and a slightly shinier robot.
Original article: https://arxiv.org/pdf/2602.21119.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
2026-02-25 13:33