Author: Denis Avetisyan
A new framework allows robots to refine their skills in a simulated environment, dramatically improving performance on complex physical tasks.
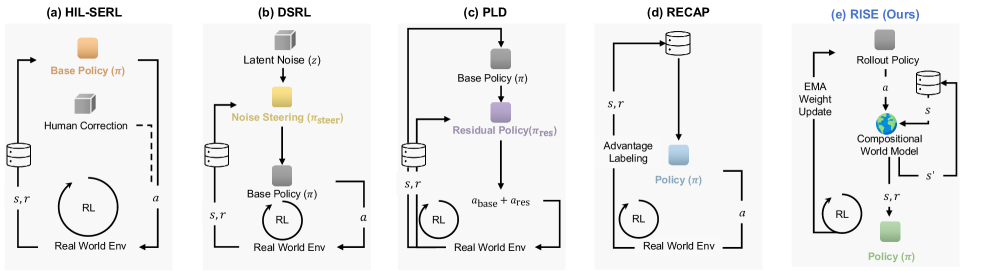
RISE utilizes a compositional world model to shift reinforcement learning from the real world to an imaginative space, enabling scalable and efficient policy improvement.
Despite advances in scaling vision-language-action models, robotic manipulation remains brittle in dynamic, contact-rich environments due to compounding errors during execution. To address this, we present ‘RISE: Self-Improving Robot Policy with Compositional World Model’, a framework that shifts reinforcement learning from costly physical interaction to an imaginative space powered by a learned world model. This approach utilizes a compositional design-predictive dynamics and progress-based value evaluation-to generate informative advantages for policy improvement, yielding substantial gains across complex tasks. Could this paradigm of learning through imagination unlock a new era of robust and adaptable robotic systems capable of tackling real-world challenges?
Beyond Imitation: The Limits of Reactive Robotics
For many years, robot learning has prominently featured imitation learning, a technique where robots acquire skills by observing and replicating the actions of a human expert or a pre-defined optimal policy. This approach bypasses the complexities of reward function design – a significant challenge in reinforcement learning – by directly learning from demonstrations of desired behavior. Essentially, the robot attempts to map observed states to actions, creating a policy that mimics the expert’s control. While effective in constrained environments and for well-defined tasks, this reliance on pre-collected demonstrations forms the cornerstone of much robotic control, enabling robots to perform complex maneuvers and interact with their surroundings by mirroring observed expertise.
Exposure bias fundamentally limits the efficacy of imitation learning in robotics. The core issue arises because a robot trained through demonstration can only reliably execute actions observed within its training dataset; any deviation from these pre-recorded scenarios presents a significant challenge. This isn’t merely a matter of lacking specific instructions, but a systemic inability to generalize beyond the experienced states and actions. Consequently, even slight environmental changes, unexpected object positions, or novel task variations can lead to performance degradation, as the robot attempts to apply learned behaviors to situations for which it has no precedent. The resulting failures aren’t due to a lack of computational power, but rather a deficit in the breadth of experience necessary for robust, real-world adaptation, highlighting the need for learning strategies that transcend the limitations of purely demonstrative guidance.
The reliance on pre-defined demonstrations creates a significant bottleneck when robots encounter situations diverging from their training data; this lack of adaptability stems from the system’s inability to generalize beyond observed examples. Consequently, performance degrades rapidly in novel environments or when faced with unexpected variations, hindering robust real-world application. A robot trained solely on imitation struggles to reason about unseen states, effectively limiting its autonomy and requiring constant human intervention or re-training. This constraint underscores the need for learning paradigms that prioritize generalization and allow robots to proactively address the inherent unpredictability of complex, dynamic environments, rather than simply replicating known behaviors.
![RISE demonstrates superior learning dynamics compared to RECAP[2] and DSRL[80], achieving significantly higher performance even with extended training and increased real-world interaction for the competing methods.](https://arxiv.org/html/2602.11075v1/x8.png)
Reinforcement Learning and World Models: A Path Towards Autonomy
Reinforcement Learning (RL) is a computational approach to learning where an agent interacts with an environment to maximize a cumulative reward signal. The agent learns a policy – a mapping from states to actions – through repeated trial and error. This process involves the agent taking actions in a given state, receiving a reward (or penalty) based on the outcome, and adjusting its policy to favor actions that lead to higher cumulative rewards over time. The objective function in RL is typically defined as [latex] \max_{π} E_{τ \sim π} [ \sum_{t=0}^{T} γ^t r(s_t, a_t) ] [/latex], where π is the policy, τ represents a trajectory, [latex] r [/latex] is the reward function, γ is a discount factor, and [latex] T [/latex] is the time horizon. Algorithms such as Q-learning and policy gradients are employed to iteratively refine the policy and maximize this cumulative reward.
Addressing the sample inefficiency inherent in Reinforcement Learning (RL) is increasingly achieved through the integration of ‘World Models’. These models are predictive systems trained to learn a representation of the environment’s dynamics, enabling them to simulate future states given current actions. This simulation capability allows an RL agent to generate synthetic experience, effectively expanding the dataset available for training without requiring further real-world interaction. By learning to predict the consequences of its actions within the simulated environment, the agent can plan and optimize its behavior more efficiently, reducing the number of real-world trials needed to achieve a desired level of performance. The learned world model is typically parameterized and trained using supervised learning techniques on observed state-action-state transitions.
The integration of world models with reinforcement learning enables robots to predict the consequences of their actions without direct environmental interaction. By learning a model of the environment’s dynamics, the robot can internally simulate future states resulting from various actions, effectively “imagining” potential scenarios. This predictive capability facilitates planning; the robot can evaluate different action sequences within the simulated environment to identify those maximizing expected rewards. Consequently, learning occurs at a significantly faster rate than through solely real-world trial and error, addressing sample inefficiency. Furthermore, this simulated experience enhances robustness by allowing the robot to prepare for, and adapt to, a wider range of unforeseen circumstances than it might encounter during limited physical interactions.
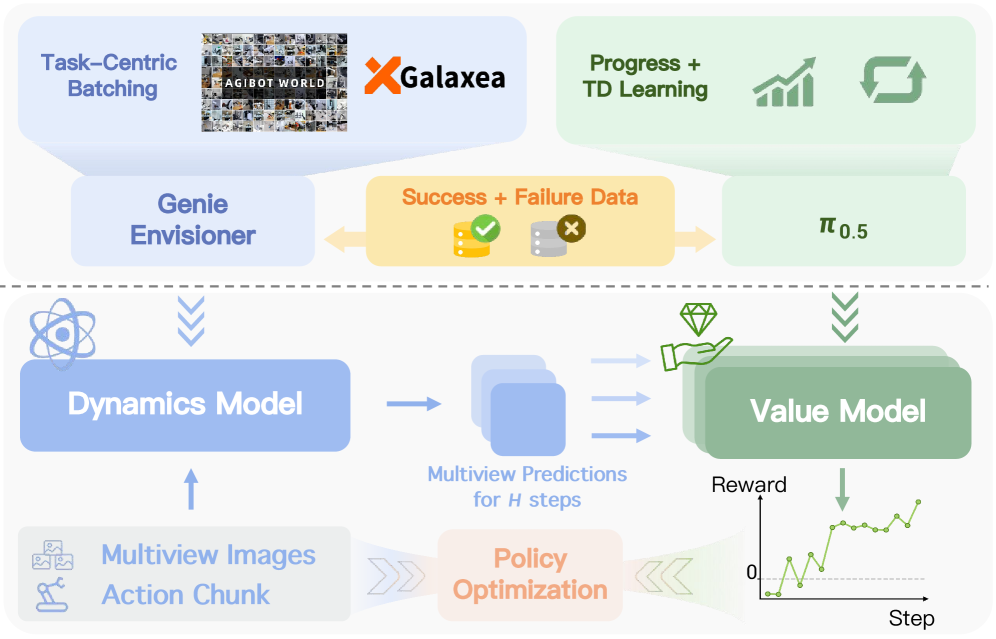
Decomposing Complexity: Dynamics and Value in Compositional World Models
A Compositional World Model addresses the challenge of simulating complex environments by decomposing the process into distinct dynamics prediction and value estimation components. This separation allows the system to first forecast future states based on current observations and actions – the dynamics prediction aspect – and then independently assess the desirability or value of those predicted states. This modularity contrasts with monolithic approaches and enables targeted improvements to either the prediction or evaluation function without requiring retraining of the entire system. The core principle is to represent the world not as a single, intractable simulation, but as a combination of predictable state transitions and a learned understanding of which states are beneficial, facilitating more efficient learning and generalization.
Dynamics prediction within a compositional world model utilizes techniques such as the Video Diffusion Model and Task-Centric Batching to forecast future states of the environment. The Video Diffusion Model, a generative approach, learns to predict subsequent frames in a video sequence, effectively modeling the transition dynamics. Task-Centric Batching improves the efficiency of this prediction by prioritizing data relevant to the agent’s current task, focusing learning on the most pertinent state transitions. This allows the model to accurately estimate the consequences of actions, forming a crucial component in planning and decision-making processes by predicting how the environment will evolve.
Value estimation within the compositional world model operates by assigning a desirability score to predicted future states. This process is initiated with a ‘Progress Estimate’, providing an initial assessment of how favorable a given state is towards achieving a defined goal. Subsequently, ‘Temporal-Difference Learning’ refines this estimate by comparing predicted future rewards with actual observed outcomes, iteratively adjusting the value assigned to each state. This iterative refinement allows the model to learn a nuanced understanding of state desirability, factoring in long-term consequences and enabling effective decision-making in complex environments. The resulting value function serves as a critical component in guiding the agent’s behavior and selecting optimal actions.
A modular world model, separating dynamics prediction and value estimation, facilitates efficient learning and adaptation by enabling targeted updates to individual components. Isolating dynamics allows for focused improvement of state forecasting without retraining the entire system, while independent value estimation permits refinement of reward signals and policy optimization without altering the dynamics model. This decoupling reduces computational cost and sample complexity, particularly in complex environments where interactions are sparse or delayed. Furthermore, the modularity promotes generalization; learned dynamics and value functions can be recombined and applied to novel tasks or scenarios with minimal retraining, accelerating adaptation to changing conditions.
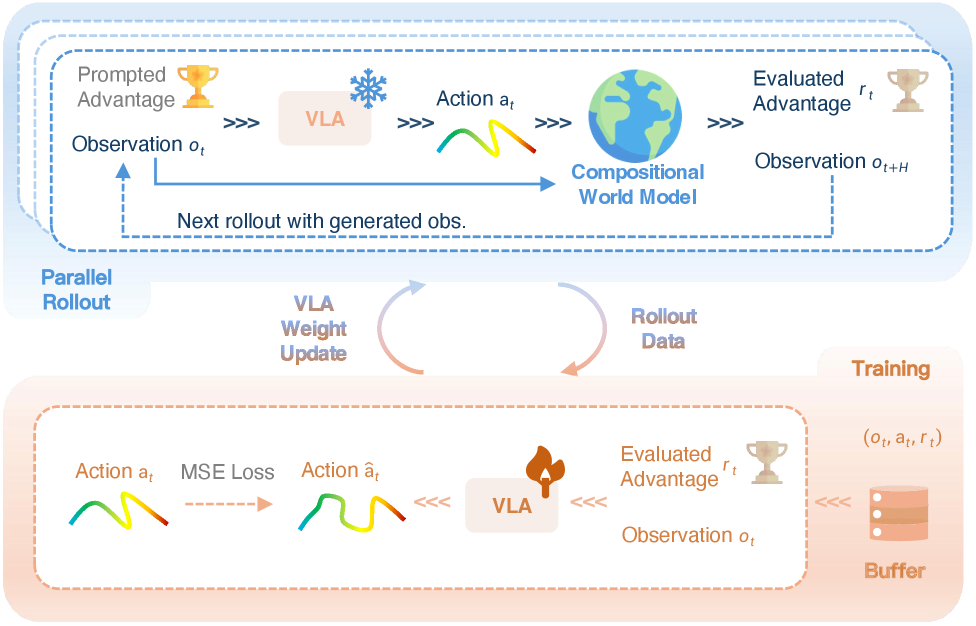
RISE: Reinforcing Imagination for Self-Improving Robotic Systems
RISE introduces a groundbreaking approach to robotic learning, fundamentally shifting the paradigm from reactive control to proactive self-improvement through the power of imagination. This novel framework enables robots to envision potential outcomes of their actions, essentially simulating experience before physically executing them. By internally ‘playing out’ scenarios, the robot can refine its strategies and optimize performance without constant real-world trial and error. This capability is achieved by constructing a dynamics model that predicts the consequences of actions and a value model that assesses the desirability of future states, allowing the robot to learn from imagined experiences as effectively as from actual ones. The result is a system that doesn’t simply respond to its environment, but actively anticipates and shapes it, fostering a cycle of continuous learning and refinement that significantly enhances its capabilities.
The RISE framework efficiently enhances robotic learning through the strategic use of offline data – previously collected experiences that don’t require continuous real-time interaction. This pre-training process effectively initializes the robot’s understanding of its environment and task, while also serving as a powerful regularizer during subsequent learning phases. By grounding its policies in established data, RISE avoids the pitfalls of exploratory learning and dramatically accelerates the acquisition of new skills. This approach not only improves sample efficiency – allowing robots to learn more from less interaction – but also promotes stability and robustness, ensuring consistent performance even in complex and dynamic scenarios.
The RISE framework strategically employs Advantage Conditioning to refine the robot’s decision-making process, effectively steering policy learning towards actions that maximize reward. This technique centers on estimating the ‘advantage’ of each potential action – the extent to which that action is better than the average action in a given state. By explicitly incorporating this advantage signal into the learning process, RISE enables the robot to prioritize and select superior actions with greater precision. Consequently, the robot doesn’t simply learn what to do, but rather how much better a specific action is compared to alternatives, leading to faster adaptation and improved performance in complex tasks. This targeted approach to policy optimization is a key driver of RISE’s success, allowing it to consistently outperform existing robotic learning methods.
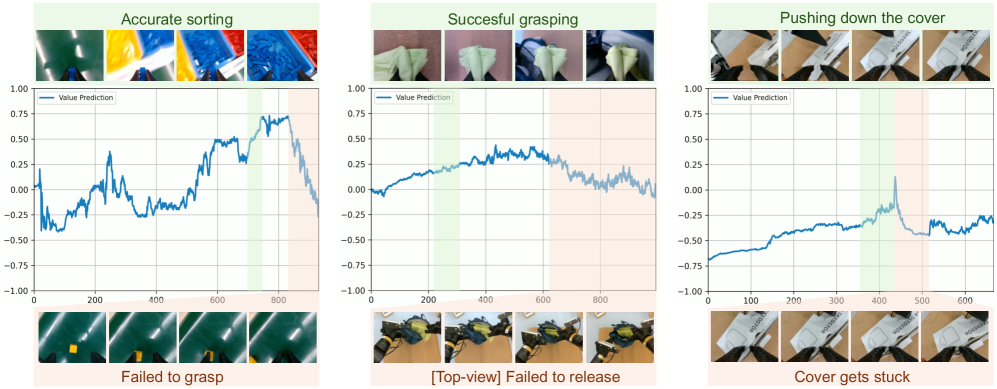
The RISE framework demonstrably elevates robotic performance across a suite of complex manipulation tasks. In dynamic brick sorting scenarios, robots utilizing this approach achieve an impressive 85% success rate, skillfully adapting to shifting environments and imprecise placements. Even greater proficiency is observed in backpack packing, where the success rate climbs to 95%, indicating a robust ability to organize and secure items within constrained spaces. Furthermore, the framework extends this capability to box closing, attaining an 85% success rate and highlighting its versatility in completing practical, real-world actions; these results consistently surpass the performance of existing robotic learning baselines, signifying a substantial advancement in autonomous task completion.
Rigorous testing through ablation studies highlighted the critical role of a value model incorporating Temporal-Difference Learning within the RISE framework. Removing this component resulted in a substantial performance decrease, demonstrating a 35% improvement in task completion rate when it was included. This finding underscores the model’s ability to accurately predict long-term rewards, effectively guiding the robot’s policy towards optimal actions and enhancing its capacity for self-improvement. The substantial gain emphasizes that the value model isn’t merely a refinement, but a fundamental element enabling RISE to surpass baseline performance in complex robotic tasks.
The RISE framework’s dynamics model exhibits a marked improvement in action controllability, as evidenced by substantial reductions in End-Point Error (EPE) when contrasted with leading predictive models like Cosmos and Genie Envisioner. This enhanced precision in predicting the consequences of actions allows the robot to execute tasks with greater accuracy and reliability. Lower EPE translates directly to more consistent performance, minimizing deviations from the intended trajectory and enabling the robot to confidently manipulate objects in its environment. The model’s ability to accurately foresee outcomes is critical for complex tasks, facilitating smoother and more successful completion of intricate manipulations and ultimately driving the observed gains in overall task performance.
The Future of Robotic Learning: Beyond Imitation, Towards Imagination
Robotic learning is undergoing a transformative shift with the incorporation of “imagination,” a capability enabled by sophisticated world models. These models allow robots to predict the outcomes of actions before they are executed, essentially simulating potential futures. This predictive power, when combined with reinforcement learning frameworks like RISE – which efficiently explores and learns from these imagined experiences – drastically accelerates the learning process. Instead of relying solely on trial and error in the real world, robots can now learn through extensive, safe, and cost-effective simulations. This unlocks the potential for robots to master complex tasks with significantly less real-world data and overcome challenges previously deemed insurmountable, heralding a new era of adaptable and intelligent machines.
Ongoing investigation centers on refining the predictive accuracy and computational speed of robotic world models. Current limitations in realistically simulating complex environments and physical interactions necessitate advancements in areas like differentiable rendering and physics engines. Researchers are actively exploring techniques to reduce the dimensionality of these models – enabling them to learn from fewer samples and operate with limited computational resources – while simultaneously increasing their fidelity. This pursuit of both realism and efficiency is crucial for equipping robots with the capacity to plan and execute increasingly intricate tasks, from navigating unstructured environments and manipulating deformable objects to collaborating effectively with humans in dynamic settings. The ultimate goal is to move beyond pre-programmed behaviors and unlock truly autonomous robotic problem-solving.
The development of robotic systems capable of genuine adaptability, resilience, and independent problem-solving represents a significant leap beyond conventional automation. These advanced robots aren’t simply executing pre-programmed instructions; instead, they leverage internal models of the world to anticipate challenges and devise novel solutions. This capacity for improvisation is crucial in dynamic, unpredictable environments where pre-planning is insufficient. Crucially, resilience isn’t merely about recovering from failures, but about learning from them and refining strategies for future encounters. By combining predictive capabilities with robust error handling, these systems promise to operate reliably even when faced with unexpected obstacles or incomplete information, effectively bridging the gap between programmed behavior and true autonomous action.
The convergence of advanced robotic learning promises a future where robots move beyond pre-programmed tasks and become truly integrated companions in daily life. This isn’t simply about automation; it’s about creating systems capable of independent thought and problem-solving within complex, unpredictable environments. Such robots could revolutionize healthcare by providing personalized assistance, address critical challenges in environmental sustainability through efficient resource management, and enhance productivity across diverse industries. The potential extends to disaster relief, where robots could navigate hazardous conditions and provide vital support, and even to expanding human exploration of remote or inaccessible regions. Ultimately, the ability for robots to learn, adapt, and innovate independently suggests a trajectory towards a future where they are not merely tools, but collaborators in building a more sustainable, efficient, and prosperous world.

The RISE framework, by shifting robotic learning into a simulated, imaginative space, echoes a fundamental principle of robust system design. The ability to iteratively refine policy through a learned world model-to essentially practice without physical consequence-highlights the importance of anticipating future states and potential failures. As Blaise Pascal observed, “All of humanity’s problems stem from man’s inability to sit quietly in a room alone.” This resonates with RISE’s approach; by creating a ‘room’ for the robot to explore and learn within the world model, the system minimizes costly real-world interactions. Good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
The Road Ahead
The promise of shifting robotic learning into a simulated imaginative space, as demonstrated by RISE, is compelling, yet the true test lies not in achieving initial success, but in graceful failure. Current world models, for all their sophistication, remain brittle abstractions. They excel at interpolation – recreating scenarios similar to those encountered during training – but extrapolate poorly. A slight perturbation, an unforeseen object, and the entire edifice can crumble. The field must confront this fragility, not by building ever more complex models, but by prioritizing robustness and uncertainty awareness. If a design feels clever, it’s probably fragile.
A critical, often overlooked, element is the nature of ‘improvement’ itself. RISE focuses on policy optimization within the simulated world. However, a locally optimal policy in simulation may be disastrous in reality. The gap between simulated reward and real-world consequences demands careful consideration. A more holistic approach necessitates integrating model-based and model-free techniques, allowing the robot to learn from its mistakes, even those predicted by a fallible world model. Structure dictates behavior, and a robust structure anticipates-and tolerates-error.
Ultimately, the goal is not simply to create robots that can perform complex tasks, but robots that can learn to perform them, and adapt when the inevitable unexpected occurs. The path forward requires a shift in emphasis: from maximizing performance in a controlled environment, to maximizing learning in an uncertain one. Simplicity always wins in the long run, and a simple, adaptable system is far more valuable than a complex, fragile one.
Original article: https://arxiv.org/pdf/2602.11075.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- Gold Rate Forecast
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Magicmon: World redeem codes and how to use them (March 2026)
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Olivia Colman’s highest-rated drama hailed as “exceptional” is a must-see on TV tonight
- Total Football free codes and how to redeem them (March 2026)
- Seeing in the Dark: Event Cameras Guide Robots Through Low-Light Spaces
- DC Retcons Controversial Superman Storyline Thanks to Powerful New Villain
2026-02-12 17:34