Author: Denis Avetisyan
Researchers have developed a new framework allowing mobile robots to create detailed 3D representations of environments, focusing on how objects move and connect.
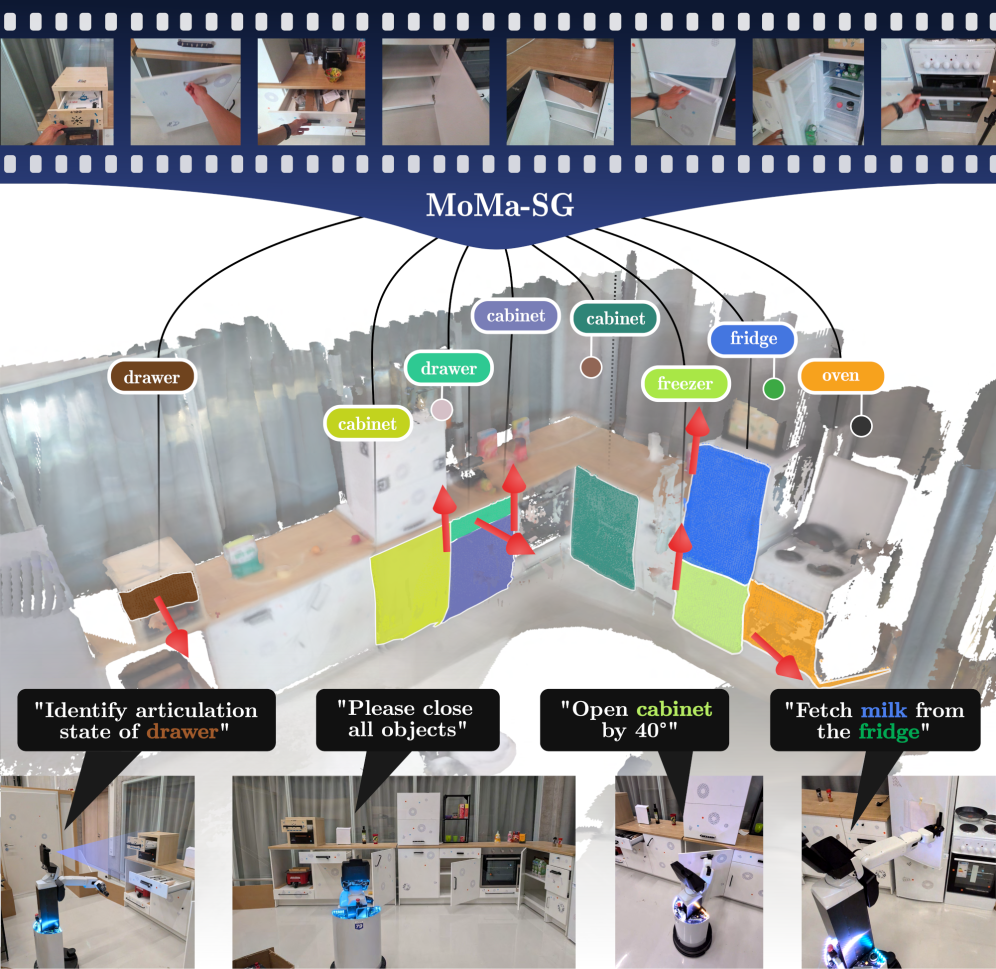
This work introduces MoMa-SG, a system for constructing articulated 3D scene graphs that enable robots to understand and manipulate objects like drawers and cabinets in real-world settings.
While robots excel at recognizing objects, anticipating their movement within dynamic scenes remains a critical challenge for long-horizon manipulation. This limitation motivates the work presented in ‘Articulated 3D Scene Graphs for Open-World Mobile Manipulation’, which introduces a novel framework, MoMa-SG, for building semantic-kinematic 3D scene graphs of articulated environments. By temporally segmenting interactions and estimating object articulation models, MoMa-SG enables robots to reason about the state and potential motion of objects like drawers and cabinets. Could this approach unlock more robust and intuitive manipulation capabilities for robots operating in complex, real-world homes?
The Challenge of Articulated Systems: A Foundation of Robotic Perception
Effective robotic manipulation hinges on a system’s ability to perceive articulated objects – those comprised of multiple connected parts, like a hand, a chain, or a folding garment – as they change shape and configuration. Unlike rigid bodies with predictable movements, these objects undergo complex, non-rigid transformations, presenting a significant challenge to traditional 3D perception methods. A robotic gripper must not only identify what an object is, but also how it is posed, and crucially, anticipate how its configuration will change under interaction. Successfully grasping or manipulating such objects requires perceiving the relationships between each part, tracking their movements relative to one another, and understanding how these changes affect the object’s overall behavior – a level of perceptual sophistication that remains a key hurdle in advancing robotic dexterity.
Conventional three-dimensional perception techniques, while effective for static scenes, often falter when confronted with articulated objects-those comprised of multiple moving parts like robotic arms, deformable tools, or even living organisms. These methods typically assume rigid bodies, struggling to accurately model the non-rigid transformations and complex inter-part relationships inherent in articulated systems. Consequently, robotic grasp planning becomes unreliable, as the perceived object geometry diverges from its actual configuration during interaction. This perceptual uncertainty introduces significant challenges for manipulation tasks, frequently resulting in failed grasps, collisions, or inefficient movements, highlighting the need for perception systems specifically designed to address the complexities of articulated object understanding.
Successful robotic manipulation hinges on a comprehensive understanding of how an object’s parts relate-both to each other and to the surrounding environment. This isn’t simply about identifying individual components, but grasping the constraints governing their movement and interaction; a robotic hand, for instance, needs to predict how a drawer’s handle will move relative to the drawer itself, and how both will interact with the supporting furniture. Without accurately modeling these relationships-including joint limits, contact surfaces, and potential collisions-a robot risks failing a task, damaging the object, or even causing harm. Researchers are therefore focusing on developing perception systems that can infer not just the 3D pose of each part, but also the underlying kinematic and physical connections that define the articulated object as a functional whole, enabling robust and adaptable robotic behaviors.
![MoMa-SG constructs accurate 3D scene graphs of articulated scenes for long-horizon mobile manipulation by discovering interaction segments, estimating object articulations [latex]\mathcal{A}[/latex] from point trajectories, and matching mapped objects [latex]\mathcal{O}[/latex] to their articulated parents.](https://arxiv.org/html/2602.16356v1/x2.png)
MoMa-SG: Modeling Articulated Scenes with Kinematic Rigor
MoMa-SG constructs articulated 3D scene graphs by learning from interaction demonstrations, specifically recordings of human-robot or human-environment interactions. This process involves identifying objects within a scene and defining their relationships, not just spatially, but also in terms of kinematic constraints – how the objects move relative to each other. The resulting scene graph represents the scene as a collection of linked objects, each with associated semantic labels and kinematic properties. This structured representation allows for a more comprehensive understanding of the scene than traditional 3D models, enabling reasoning about object manipulation, pose estimation, and potential interactions between objects during task planning and execution.
MoMa-SG facilitates robotic reasoning regarding scene elements by combining semantic understanding with kinematic data. Specifically, the framework models object relationships not just as semantic categories (e.g., “mug”, “table”), but also by defining the kinematic chains and joints that connect them, allowing the robot to infer object pose and potential configurations. This integration extends to understanding containment-whether an object is inside another-and predicting interactions, such as a robot grasping an object or manipulating a drawer, based on the established kinematic and semantic relationships within the scene graph. This allows for more robust and informed planning compared to systems relying solely on semantic or geometric data.
MoMa-SG’s performance is benchmarked and refined using the Arti4D-Semantic Dataset, a resource specifically designed for evaluating articulated scene graph construction. This dataset provides paired demonstrations of human interaction with objects and corresponding 3D scene graphs, enabling quantitative assessment of the framework’s ability to accurately represent object pose, relationships, and kinematic structure. Evaluations on this dataset demonstrate that MoMa-SG achieves competitive performance compared to existing methods in tasks requiring understanding of articulated scenes and object manipulation, as measured by metrics assessing graph similarity and prediction accuracy.

Estimating Articulated Pose and Motion: A Two-Stage Approach
Within the MoMa-SG framework, articulated object pose and motion estimation is achieved through a two-stage process of Point Tracking and Twist Estimation. Point Tracking identifies and associates corresponding points across consecutive frames, establishing kinematic constraints. Subsequently, Twist Estimation leverages these tracked points to compute the rigid body transformation – specifically, the translational and rotational components represented as a “twist” – that best describes the object’s 6DoF pose. This method allows for the reconstruction of articulated pose over time, providing data regarding both the object’s position and orientation in 3D space as it moves through a sequence of images.
Twist estimation, a core component of articulated pose determination, is enhanced through the application of a Geometric Prior. This prior leverages known geometric constraints – such as joint limits and bone lengths – to regularize the estimated twist parameters. Specifically, the prior functions as a penalty term within the optimization process, discouraging solutions that violate these geometric boundaries. This regularization improves the stability of pose estimates, particularly in scenarios with noisy data or partial observations, and ensures that the resulting poses represent physically plausible configurations of the articulated object. The implementation of this prior directly addresses potential drift and instability inherent in purely data-driven twist estimation methods.
Evaluation on the Arti4D-Semantic dataset demonstrates the framework’s strong performance in articulated object segmentation. Specifically, the system achieves competitive Intersection over Union (IoU) scores when assessing segmentation accuracy across multiple viewpoints. These IoU scores provide a quantitative measure of overlap between predicted and ground truth segmentations, indicating the system’s ability to accurately delineate articulated objects in varying orientations and under different observation angles. The achieved scores are comparable to those of other state-of-the-art methods on the same benchmark, validating the effectiveness of the proposed approach.

Enabling Intelligent Robotic Interaction: A Synergistic Approach
MoMa-SG functions not as a standalone system, but as a cohesive integration layer for established robotic functionalities, dramatically improving manipulation robustness. By directly interfacing with core capabilities – including precise Robot Localization for positional awareness, Simultaneous Localization and Mapping (SLAM) for environmental understanding, and sophisticated Grasp Planning algorithms – the framework enables robots to move beyond pre-programmed sequences. This synergistic approach allows for dynamic adaptation to changing environments and unexpected obstacles, resulting in more reliable and versatile robotic performance. Instead of reinventing fundamental robotic processes, MoMa-SG enhances them, creating a more intelligent and responsive system capable of tackling complex manipulation tasks with greater consistency and efficiency.
Accurate scene understanding is central to intelligent robotic interaction, and this framework achieves it through the combined power of depth sensing and semantic segmentation. By processing visual information to discern both the spatial layout and the objects within it, the system builds a detailed representation of its surroundings. Evaluations demonstrate a strong capacity for semantic categorization, evidenced by a Top-1 CLIP Feature Accuracy of 28.7% – meaning the correct object label appears as the top prediction nearly 29% of the time – and an even more impressive Top-5 CLIP Feature Accuracy of 63.3%, indicating the correct label appears within the top five predictions over 63% of the time. This robust performance in identifying and classifying objects allows the robot to interact with its environment in a more meaningful and context-aware manner.
MoMa-SG extends robotic functionality through the integration of Natural Language Processing, allowing robots to respond to and execute human instructions with greater flexibility. This capability moves beyond pre-programmed routines, enabling robots to understand nuanced commands expressed in everyday language. The system processes these instructions to determine the appropriate sequence of actions, bridging the gap between human intention and robotic execution. By interpreting linguistic input, MoMa-SG facilitates more intuitive and collaborative human-robot interaction, opening possibilities for applications in diverse fields like assistive robotics, manufacturing, and domestic service, where adaptability and responsiveness are paramount.

The pursuit of robust mobile manipulation, as detailed in this work concerning MoMa-SG and articulated 3D scene graphs, demands a commitment to foundational principles. The system’s emphasis on semantic understanding and kinematic modeling mirrors a dedication to provable correctness, rather than mere empirical success. As Brian Kernighan aptly stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This sentiment resonates deeply with the need for clarity and mathematical rigor in robotic perception; a cleanly modeled articulated object, grounded in demonstrable principles, is far more valuable than a complex, fragile approximation that ‘works’ only in limited scenarios. The elegance of a solution, within the context of interactive environments, lies in its inherent logical structure and verifiability.
What’s Next?
The construction of MoMa-SG, while a demonstrable step toward semantic understanding in robotic manipulation, merely formalizes the initial stage of a far more complex problem. The current reliance on perception to generate kinematic models, while functional, introduces a critical fragility. A truly robust system demands a shift from observing articulation to inferring it – a move toward predictive modeling grounded in physical principles. The asymptotic complexity of maintaining and updating such graphs as environmental interaction increases remains a significant, and largely unaddressed, challenge.
Future work must prioritize the development of invariant properties within these scene graphs. Currently, the system appears susceptible to perturbations – minor perceptual errors propagating into substantial manipulation failures. A mathematically rigorous framework, perhaps leveraging differential geometry or topological data analysis, could provide the necessary resilience. The naive assumption of complete observability, inherent in current approaches, is demonstrably false; therefore, probabilistic inference and active perception strategies must be integrated to gracefully handle uncertainty.
Ultimately, the true measure of success will not be the ability to represent articulated objects, but the capacity to reason about them. The current framework is, at best, a descriptive tool. The next generation of robotic systems will require a declarative approach – scene graphs that encode not just what is, but how it behaves, and why. Only then will manipulation transcend mere imitation and approach genuine intelligence.
Original article: https://arxiv.org/pdf/2602.16356.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
2026-02-19 22:51