Author: Denis Avetisyan
Researchers have successfully trained reinforcement learning agents to manipulate and unfold cloth in real-time, bridging the gap between simulation and real-world robotics.

Leveraging surface normals and modified replay buffers, this work enables robust sim-to-real transfer for complex deformable object manipulation tasks.
Deformable object manipulation remains a significant challenge for robotics, requiring strategies capable of navigating complex physics and high-dimensional state spaces. This is addressed in ‘Learning to unfold cloth: Scaling up world models to deformable object manipulation’, which introduces a reinforcement learning approach leveraging a modified DreamerV2 architecture for in-air cloth unfolding. By incorporating surface normals as input and refining the replay buffer, the authors demonstrate improved world model accuracy and generalization performance. Could this architecture unlock more robust and adaptable robotic systems capable of mastering a wider range of complex manipulation tasks?
The Illusion of Control: Cloth and the Limits of Prediction
The seemingly simple act of manipulating cloth presents a formidable challenge to robotic systems due to the fundamental properties of deformable objects. Unlike rigid bodies with predictable movements, cloth exhibits infinite degrees of freedom, meaning it can bend, stretch, and fold in countless ways. This inherent flexibility introduces high dimensionality into the problem, requiring robots to account for an enormous number of possible configurations. Furthermore, external forces – even slight breezes – and the material’s own internal dynamics create significant uncertainty, making it difficult to predict how the cloth will respond to any given action. Successfully grasping and manipulating cloth, therefore, demands advanced algorithms and sensor systems capable of perceiving and adapting to these complex, ever-changing conditions – a task that continues to push the boundaries of robotic control.
Conventional robotic systems, designed for rigid objects, encounter substantial difficulties when interacting with cloth due to its inherent deformability. Unlike the predictable movements of solid items, cloth presents a nearly infinite number of possible configurations – a high-dimensional state space – making precise control exceptionally challenging. Furthermore, even minor disturbances, such as air currents or slight variations in the cloth’s weave, introduce significant uncertainty into its dynamic behavior. This unpredictability complicates the planning of effective manipulation strategies, as even seemingly simple actions can lead to unintended consequences or failures in grasping and folding. Consequently, adapting established robotic techniques to reliably handle cloth requires innovative approaches that account for both the complexity and uncertainty of its dynamics.
The ability for robots to reliably manipulate cloth holds transformative potential across diverse fields. In assistive care, automated folding and organization of laundry could greatly enhance the independence of individuals with limited mobility. Manufacturing processes stand to benefit from robotic systems capable of handling textiles with precision, streamlining tasks like garment assembly and quality control. Beyond these core areas, advancements in cloth manipulation could also impact fields such as surgery – enabling robots to deftly handle drapes and sterile coverings – and even space exploration, where automated systems could deploy and maintain flexible structures. Ultimately, mastering this complex skill promises to unlock a new generation of robotic applications focused on enhancing quality of life and increasing efficiency in various sectors.

Learning Through Iteration: The Promise of Reinforcement
Reinforcement Learning (RL) enables robotic systems to acquire skills through iterative interaction with an environment, receiving rewards or penalties for actions taken. This paradigm differs from traditional programmed control by eliminating the need for explicitly defined behaviors; instead, the robot learns an optimal policy – a mapping from states to actions – through repeated trial and error. The agent explores the state space, attempting different actions and observing the resulting consequences, thereby refining its policy to maximize cumulative reward. This approach is particularly beneficial for tasks where defining precise control rules is difficult or impossible due to environmental complexity, high dimensionality, or imprecise models. The learning process typically involves estimating a value function, which predicts the expected cumulative reward from a given state, and/or a policy function that directly maps states to actions.
Effective reinforcement learning in complex environments is significantly challenged by the need for both robust exploration strategies and efficient learning algorithms. Traditional RL methods often struggle in continuous state and action spaces due to the difficulty of exploring the vast solution landscape and the computational cost of learning a value function or policy. Robust exploration is crucial to avoid getting stuck in local optima, requiring techniques that balance exploiting known rewards with investigating novel states and actions. Efficient learning algorithms, such as those utilizing model-based RL or prioritized experience replay, are necessary to accelerate learning and reduce the sample complexity required to achieve satisfactory performance. The dimensionality of continuous spaces necessitates function approximation techniques, which introduce further challenges in terms of generalization and stability.
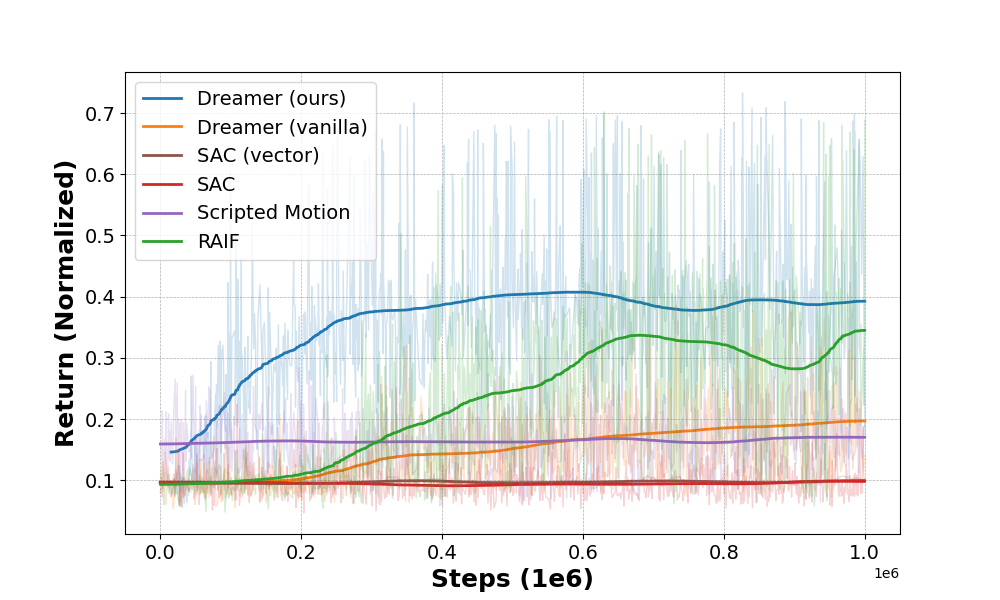
This research utilized DreamerV2, a model-based reinforcement learning algorithm, to address the challenge of in-air cloth unfolding. DreamerV2 learns a world model to predict future states and rewards, enabling efficient policy optimization through imagined rollouts. In real-world experiments, a policy trained with DreamerV2 achieved a 74% success rate in unfolding cloth, as measured by a defined completion criterion. This performance demonstrates the model’s capability to learn complex manipulation skills directly from high-dimensional sensory input and execute them reliably in a physical environment, surpassing prior approaches to this task.
The Ghost in the Machine: Constructing a Predictive World
DreamerV2 employs a World Model to facilitate planning and decision-making by learning a compressed representation of the environment’s dynamics. This model is trained to predict future states – specifically, the resulting observations after an action is taken – based on the agent’s current state and the chosen action. The learned representation enables the agent to simulate potential outcomes without interacting directly with the environment, effectively planning a sequence of actions to achieve a desired goal. This predictive capability is achieved through a recurrent state-space model, allowing the agent to maintain an internal belief state and forecast future observations based on its actions and the learned dynamics of the environment.
The World Model receives training data consisting of RGB images and corresponding surface normal vectors. RGB input provides the agent with visual information regarding the cloth’s appearance and texture, while surface normals define the orientation of each point on the cloth’s surface. This geometric data is crucial for accurately predicting how the cloth will deform in response to actions, as it allows the agent to infer shape, pose, and local surface details. Combining visual and geometric information enables the model to learn a more robust and physically plausible representation of the cloth dynamics, improving prediction accuracy beyond what could be achieved with either data source alone.
The simulation environment is built using the Unity Game Engine coupled with the ObiCloth plugin, a real-time cloth simulation engine. This pairing allows for the generation of physically plausible cloth behavior, crucial for training the predictive model. ObiCloth handles the complex calculations of cloth deformation, collisions, and self-interactions, providing a dynamic and visually realistic training ground. The Unity environment facilitates data collection, enabling the rendering of RGB images and the calculation of surface normals necessary for the World Model’s input. This combination offers a scalable and controllable platform for generating the large datasets required for training a robust cloth dynamics predictor.
![Our learning architecture, highlighted in yellow, utilizes [latex]I, S, A, R[/latex] trajectories derived from depth images converted to surface normals and augmented batches to train a world model initialized with demonstration episodes loaded into a replay buffer.](https://arxiv.org/html/2602.16675v1/media/system_diagram2.png)
The Illusion of Robustness: Augmenting Reality
The learned policy’s ability to perform reliably across varied conditions benefits significantly from data augmentation techniques integrated directly into the Replay Buffer. This process artificially expands the training dataset by creating modified versions of existing experiences, such as subtly altered images or variations in object positions. By exposing the reinforcement learning algorithm to these diverse, yet realistic, scenarios, the policy becomes more robust to unforeseen circumstances and generalizes more effectively to new environments. This approach mitigates the risk of overfitting to the specific conditions encountered during initial training, leading to a more adaptable and dependable robotic system capable of consistently achieving its objectives even with slight deviations in real-world execution.
To bolster the learning process, the system incorporates both image augmentation and expert demonstrations as methods of data enrichment. Leveraging techniques within the DRQv2 architecture, the training data is artificially expanded through variations in visual input – such as altered lighting, rotations, and added noise – which enhances the agent’s ability to generalize to unseen scenarios. Simultaneously, incorporating demonstrations from an expert provides a strong starting point and guides the learning process, offering examples of successful task completion. This dual approach effectively expands the dataset’s diversity and quality, ultimately leading to a more robust and adaptable learning agent capable of navigating a wider range of conditions and improving overall performance.
Recent advancements in robotic manipulation demonstrate a significant performance boost when combining simulated training environments, robust reinforcement learning algorithms, and data augmentation techniques. This synergistic approach yields measurable improvements in real-world task completion; specifically, the system achieves a 15% increase in successful pick-and-place operations compared to traditional algorithms. Critically, the integration of these methods also dramatically reduces failure rates, showing a 35% decrease in instances where the robotic system is unable to complete the desired manipulation. These results highlight the potential of this combined methodology to create more reliable and efficient robotic systems capable of consistently performing complex tasks.
Beyond the Fold: Projections and Limitations
Investigations are poised to extend beyond single-arm manipulation, with future efforts centering on the implementation of dual-arm robotic systems capable of tackling increasingly intricate cloth handling challenges. This progression anticipates the automation of tasks currently demanding significant human dexterity, such as precise cloth folding and aesthetically-pleasing draping. Utilizing two arms allows for coordinated grasping and manipulation, enabling the robot to manage the complex deformations inherent in cloth materials with greater efficiency and control. This expanded capability promises not only to increase the speed and reliability of these processes, but also to unlock applications in areas like automated laundry systems, textile manufacturing, and even personalized clothing design.
Advancing robotic cloth manipulation relies heavily on a robot’s ability to accurately perceive the state of deformable materials. Integrating 3D reconstruction techniques, powered by depth sensors, offers a significant leap in this area by moving beyond limited 2D visual data. This allows the robotic agent to build a comprehensive understanding of the cloth’s complex 3D shape – including wrinkles, folds, and draping – in real-time. Consequently, the robot can plan and execute more precise manipulation strategies, avoiding failed grasps or unintended deformations. By accurately modeling the cloth’s geometry, the system can better anticipate the effects of its actions, enabling more robust and adaptive behavior when handling these notoriously challenging materials.
The successful application of reinforcement learning to robotic cloth manipulation signifies a crucial step toward more versatile and autonomous robotic systems. Traditional robotic manipulation often relies on pre-programmed instructions and precise environmental models, limiting adaptability in dynamic, real-world scenarios. This research showcases how an agent can learn to manipulate deformable objects – a notoriously difficult task – through trial and error, without explicit programming. The resulting policies aren’t simply executing pre-defined motions; instead, they represent an acquired understanding of the physical interactions between the robot and the cloth, enabling robust performance even with variations in cloth properties or initial configurations. This learned adaptability extends beyond cloth, suggesting a broader applicability of reinforcement learning to other complex manipulation tasks and opening possibilities for robots that can intelligently respond to unforeseen challenges and operate effectively in unstructured environments.
The pursuit of robust robotic manipulation, as evidenced by this work on cloth unfolding, isn’t about imposing order, but about anticipating the inevitable drift towards entropy. The researchers didn’t build a solution so much as cultivate an environment where a learning agent could adapt to the inherent unpredictability of deformable materials. This approach echoes a fundamental truth: systems evolve, they don’t remain static. As Tim Berners-Lee observed, “The Web is more a social creation than a technical one.” Similarly, this system’s success isn’t solely attributable to the algorithm or the incorporation of surface normals – it’s a product of the interplay between agent, environment, and the inherent physics of cloth, a delicate ecosystem prone to unfolding in ways unforeseen by any initial design.
What Lies Unfurled?
The successful manipulation of cloth, as demonstrated, is not a triumph over complexity, but an acknowledgement of its inherent nature. This work does not solve the problem of deformable object control; it merely shifts the boundary of ignorance. Each successful unfolding is, implicitly, a prophecy of future entanglement. The agent learns to predict, to coax, but the cloth retains its capacity for unforeseen configurations, for subtle resistance. The surface normal, as a chosen representation, is itself a simplification, a curated lie that allows control – and thus, simultaneously, defines the limits of that control.
The true challenge lies not in scaling up world models, but in accepting their fundamental incompleteness. Sim-to-real transfer, however effective, remains a precarious bridge built upon statistical resemblance. The gap will not be closed with increasingly sophisticated algorithms, but with a deeper understanding of the inherent untidiness of reality – the unmodeled drafts, the microscopic imperfections in weave, the ever-present influence of entropy.
Future work will inevitably focus on more complex fabrics, more intricate tasks. But perhaps the most fruitful avenue lies in abandoning the notion of control altogether. To design systems that don’t seek to impose order, but to harmonize with chaos. To build agents that don’t unfold cloth, but dance with it.
Original article: https://arxiv.org/pdf/2602.16675.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
2026-02-19 21:06