Author: Denis Avetisyan
Researchers have developed a new framework that imbues robots with improved geometric understanding by distilling knowledge from powerful diffusion models.
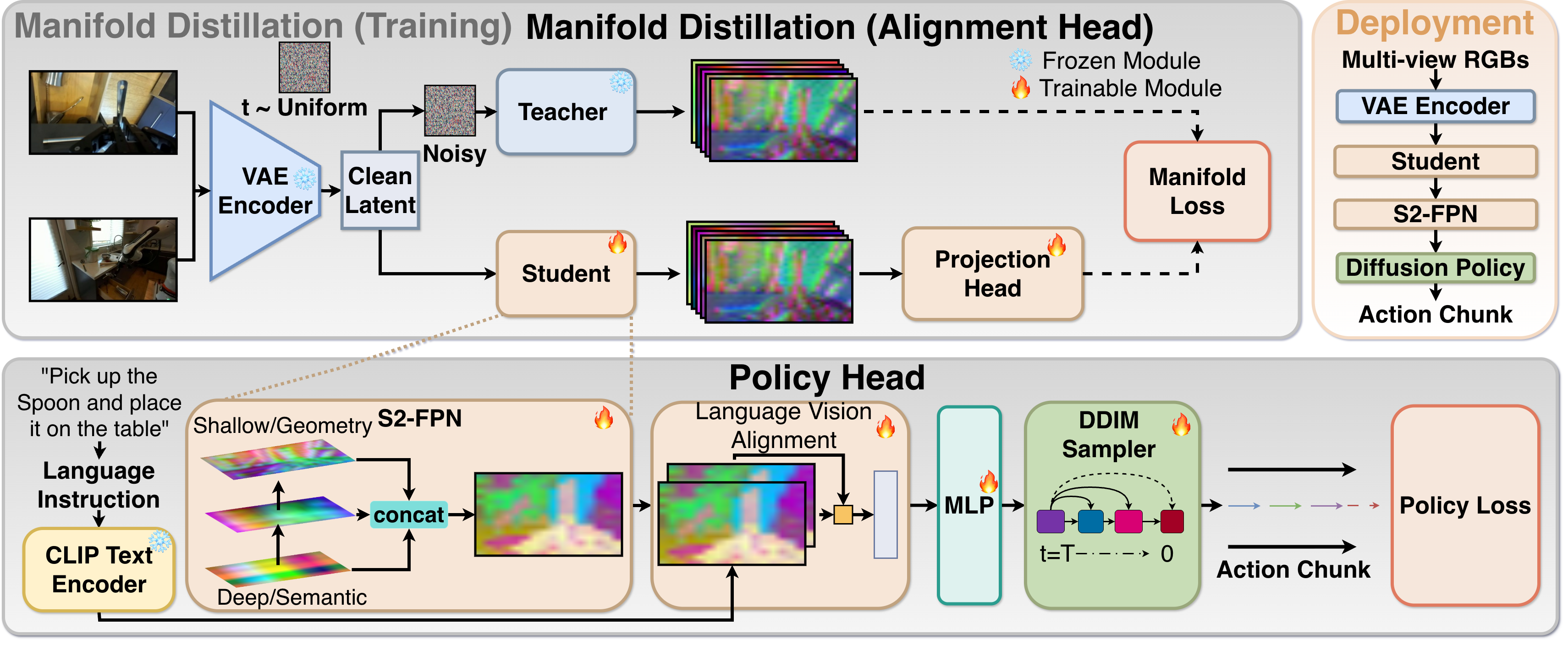
Robot-DIFT leverages manifold distillation and a spatial-semantic feature pyramid network to enhance visuomotor control in contact-rich manipulation tasks.
Despite advances in robot learning, a fundamental mismatch persists between vision systems optimized for semantic understanding and the geometric sensitivity required for precise manipulation. This work introduces Robot-DIFT: Distilling Diffusion Features for Geometrically Consistent Visuomotor Control, a framework that bridges this gap by transferring the rich geometric priors of diffusion models into a deterministic neural network. By employing Manifold Distillation to create a Spatial-Semantic Feature Pyramid Network, Robot-DIFT achieves superior geometric consistency and control performance on contact-rich tasks compared to discriminative approaches. Could this decoupling of geometric awareness from inference represent a key step towards more robust and adaptable robot manipulation systems?
The Illusion of Robotic Flexibility
Conventional robotic control systems are often built upon the premise of meticulously defined features within a known environment. This reliance on pre-programmed specifics, while enabling reliable performance in structured settings, creates a significant bottleneck when confronted with novelty. Because these systems are engineered to respond to specific inputs, even slight variations – a change in lighting, an object presented at a new angle, or a previously unseen obstacle – can disrupt operation. This inherent inflexibility stems from the difficulty in translating the continuous complexity of the real world into discrete, manageable parameters, effectively limiting a robot’s ability to adapt and generalize its skillset to new tasks or unpredictable surroundings. Consequently, robots designed with this approach often require substantial re-engineering or re-programming to function effectively outside of their initially defined operational parameters.
Robotic systems, when relying on meticulously crafted perceptual inputs, often falter when confronted with the unpredictable nature of real-world environments. The ambiguity inherent in sensory data – a consequence of imperfect lighting, partial occlusions, or simply the vast diversity of object appearances – introduces noise that quickly overwhelms precisely tuned control algorithms. This leads to what is known as ‘brittle performance’, where even minor deviations from expected conditions result in failure. Consequently, these robots exhibit a distinct lack of robust generalization; a system trained to grasp a specific object under ideal circumstances will struggle, or even fail completely, when presented with a slightly different version of that object, or when operating in a novel environment. This limitation underscores the critical need for robotic systems capable of interpreting ambiguous sensory information and adapting their actions accordingly, rather than rigidly adhering to pre-programmed responses.
Robotics frequently encounters a significant hurdle in translating what a camera ‘sees’ into the precise movements needed for manipulation. While advanced vision systems can identify objects and their approximate locations, converting this visual data into the geometric parameters-angles, distances, and orientations-required for accurate grasping and assembly remains a complex challenge. This discrepancy arises because visual perception provides a 2D representation of a 3D world, demanding sophisticated algorithms to infer depth and spatial relationships. Furthermore, real-world objects are rarely perfectly shaped or positioned as expected, necessitating robust systems that can cope with noisy or incomplete visual information and adapt to unforeseen variations during execution. Bridging this ‘perception-action gap’ is therefore crucial for developing robots capable of reliably performing tasks in unstructured and dynamic environments.

Distilling Intelligence: A Temporary Fix
Robot-DIFT is a framework designed to transfer learned geometric reasoning from large diffusion models to a compact, deterministic policy for robotic control. This is accomplished by leveraging the expansive knowledge base encoded within the diffusion model – which is typically computationally expensive – and condensing it into a more efficient policy network. The resulting framework allows for real-time robotic decision-making while retaining the geometric understanding previously exclusive to the larger, slower diffusion model. The distilled policy operates deterministically, providing predictable and repeatable actions based on input observations, unlike the stochastic nature of the originating diffusion model.
Manifold Distillation is employed to transfer knowledge from a pretrained diffusion model to a smaller, more efficient student network. This process involves training the student network to match the manifold – the lower-dimensional subspace – learned by the diffusion model. Specifically, the student network is trained on data generated by the diffusion model and optimized to replicate its output distribution, effectively distilling the geometric understanding embedded within the larger model into a compact representation. This allows the student network to inherit the diffusion model’s capabilities without requiring the same computational resources.
The Frozen Teacher Constraint enforces consistency between the student network and the pretrained diffusion model during the distillation process. This is accomplished by freezing the parameters of the diffusion model – designated as the “teacher” – and using its outputs as targets for the student network’s training. Specifically, the student is penalized for deviating from the teacher’s predicted trajectories or geometric configurations, thereby ensuring the student learns to approximate the geometric priors already embedded within the larger, pretrained diffusion model without directly modifying its weights. This approach stabilizes training and facilitates the transfer of knowledge from the diffusion model to the more compact student policy.
Geometric Sensitivity: A Fleeting Advantage
Robot-DIFT enhances Geometric Sensitivity by enabling robust adaptation to minor variations in object pose during manipulation tasks. This capability is critical for real-world robotic applications where precise alignment is frequently disrupted by environmental factors or imperfect perception. Experimental validation on the LIBERO-10 benchmark demonstrates a 0.49 overall success rate, indicating a substantial improvement over baseline models DINOv2 (0.39) and SigLIP (0.24). The framework’s superior performance is particularly evident in challenging tasks like ‘Insert Pin’, where Robot-DIFT achieves a 0.35 success rate compared to DINOv2’s 0.05.
Evaluation on the LIBERO-10 benchmark demonstrates Robot-DIFT achieves an overall task success rate of 0.49. This performance represents a statistically significant improvement over competing methodologies; DINOv2 achieved a success rate of 0.39, while SigLIP attained a rate of 0.24 on the same benchmark. The LIBERO-10 dataset consists of ten common household manipulation tasks designed to assess robotic dexterity and generalization capabilities, providing a standardized metric for performance comparison.
Evaluation of Robot-DIFT on the ‘Insert Pin’ task within the LIBERO-10 benchmark demonstrates a success rate of 0.35. This performance represents a substantial improvement over the 0.05 success rate achieved by the DINOv2 model on the same task. The ‘Insert Pin’ task is particularly challenging due to the required precision and sensitivity to minor pose variations, highlighting the enhanced geometric sensitivity provided by the Robot-DIFT framework.
Evaluation within the RoboCasa large-scale simulation environment yielded a 0.49 success rate for the Robot-DIFT framework. This performance represents a significant improvement over comparative models, exceeding the success rate of DINOv2 by 0.10 and SigLIP by 0.25 in the same environment. RoboCasa provides a complex and varied set of simulated robotic manipulation tasks, making it a robust platform for assessing generalization capabilities and overall system reliability.
Robot-DIFT leverages Diffusion Models as its core performance driver, utilizing these generative models to enhance robustness and adaptability in robotic manipulation tasks. Integral to this framework is the implementation of Variational Autoencoders (VAEs), which provide an efficient method for representing high-dimensional sensory data in a lower-dimensional latent space. This compressed representation allows for faster processing and reduces the computational burden associated with complex robotic control algorithms, while maintaining critical information for accurate task execution. The combination of Diffusion Models and VAEs enables Robot-DIFT to effectively generalize to variations in object pose and environmental conditions.
Beyond Mimicry: A Temporary Reprieve
Traditional robotic control methods, such as Diffusion Policy, OpenVLA, and UniPi, often function by meticulously replicating demonstrated actions – a process inherently bounded by the quality and scope of the training data. Robot-DIFT diverges from this paradigm, embracing a generative approach that allows the system to transcend the constraints of imitation learning. By harnessing the power of diffusion models, the framework doesn’t simply reproduce observed behaviors; instead, it proactively learns the underlying principles of manipulation, enabling it to tackle novel challenges and generalize to scenarios not explicitly covered in the training dataset. This capability represents a significant step towards more adaptable and intelligent robotic systems, moving beyond rote memorization towards true problem-solving in complex environments.
The advent of Robot-DIFT signals a departure from conventional robotic control reliant on imitation learning. Rather than simply replicating demonstrated actions, this framework harnesses the generative capabilities of diffusion models to proactively address manipulation challenges. This approach allows the robot to synthesize solutions, effectively imagining and executing plans beyond the scope of its training data. By learning the underlying structure of successful manipulation, the system doesn’t just memorize – it understands and creatively applies that understanding to novel scenarios, offering a pathway towards truly adaptable and intelligent robotic agents capable of independent problem-solving.
Recent evaluations demonstrate that Robot-DIFT attains a 0.55 success rate when tasked with opening lids – a notable advancement in robotic manipulation. This performance surpasses that of established vision-language models, DINOv2, which achieves a 0.60 success rate, and SigLIP. This improvement highlights Robot-DIFT’s capacity to effectively translate visual input into precise motor actions, even when faced with the subtle challenges inherent in lid-opening scenarios. The results suggest a significant step toward more robust and adaptable robotic systems capable of performing complex manipulation tasks with greater reliability than previous imitation-based approaches.
Robot-DIFT’s capacity for broad generalization stems from its training on the extensive DROID dataset, a collection designed to encompass the sheer variety found in real-world robotic scenarios. This large-scale exposure allows the framework to move beyond memorizing specific demonstrations and instead learn robust, underlying principles of object manipulation. Consequently, the system demonstrates competency across diverse objects – differing in shape, size, and material – and within previously unseen environments. This ability to adapt and perform reliably in novel situations represents a significant advancement, moving robotic control systems closer to true autonomy and practical application in unstructured settings.
The pursuit of geometrically consistent visuomotor control, as demonstrated by Robot-DIFT, feels predictably ambitious. This distillation of diffusion features into a deterministic framework attempts to impose order on the inherent chaos of real-world interaction. It’s a valiant effort, naturally. One recalls John von Neumann stating, “The best way to predict the future is to invent it.” While ‘invention’ often sounds grand, the reality is usually a series of pragmatic compromises. The framework’s Spatial-Semantic Feature Pyramid Network is elegant on paper, but production environments invariably reveal edge cases and unforeseen interactions. It’s not a failure of the concept, merely an acknowledgement that even the most robust systems eventually succumb to the relentless pressure of practical application. If all tests pass, it’s because they test nothing.
What’s Next?
The distillation of geometric priors, as demonstrated by Robot-DIFT, feels less like a solution and more like a carefully managed deferral. Every elegantly constrained backbone will eventually encounter an edge case – a novel articulation, an unexpected texture – that exposes the limitations of its pre-baked assumptions. The current focus on diffusion models as sources of these priors is, predictably, optimizing for today’s datasets. Everything optimized will one day be optimized back, and a new modality – perhaps tactile feedback directly informing the diffusion process – will inevitably demand a revised distillation strategy.
The persistent challenge remains the translation of purely visual reasoning into robust, contact-rich manipulation. Spatial-semantic feature pyramids offer a structured vocabulary, but vocabulary doesn’t guarantee fluency. The framework doesn’t solve geometric sensitivity; it mitigates it with learned priors. The next iteration won’t be about achieving perfect geometric fidelity, but about graceful degradation – a system that acknowledges uncertainty and adapts its grasp accordingly.
Architecture isn’t a diagram, it’s a compromise that survived deployment. The field will likely shift toward continual learning paradigms, where the robot incrementally refines its internal representation of geometry through interaction. The goal isn’t to build a perfect model of the world, but to build a system that can reliably recover from its inevitable misapprehensions. It’s not about refactoring code; it’s about resuscitating hope, one slightly adjusted grasp at a time.
Original article: https://arxiv.org/pdf/2602.11934.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
2026-02-14 14:53