Author: Denis Avetisyan
Researchers have developed a new framework that empowers robots to perform complex manipulation tasks using large language models as the core of their decision-making process.
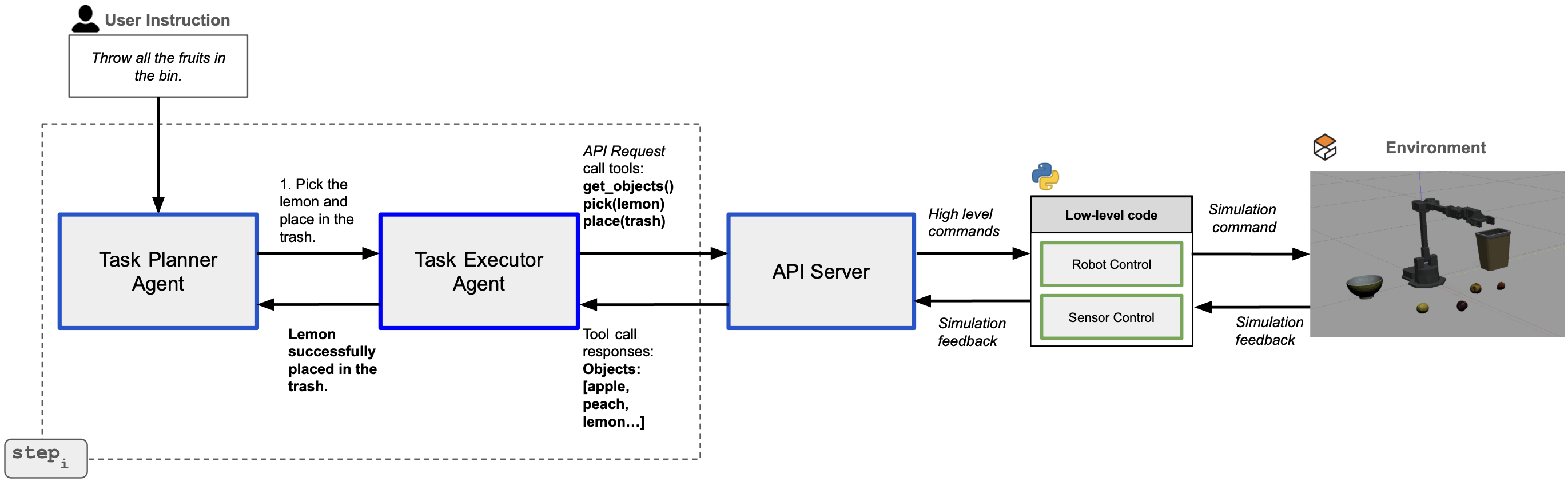
This work introduces ALRM, an agentic system leveraging LLMs and a new benchmark to evaluate ten models across performance, latency, and size for robotic manipulation.
Despite advances in large language models, effectively integrating their reasoning capabilities into robust robotic control remains a key challenge. This paper introduces [latex]ALRM[/latex]: Agentic LLM for Robotic Manipulation, a framework that combines LLM-based action generation with agentic execution via a ReAct-style loop, offering both direct code generation and iterative tool-based planning. Through a novel 56-task simulation benchmark and evaluation of ten LLMs, we demonstrate that [latex]ALRM[/latex] provides a scalable and interpretable approach to robotic manipulation, identifying Claude-4.1-Opus and Falcon-H1-7B as leading closed- and open-source models, respectively. How can such agentic frameworks further bridge the gap between linguistic instruction and reliable, real-world robotic performance?
The Inevitable Fracture of Traditional Control
Historically, robotic control has depended on painstakingly designed systems – often referred to as pipelines – where each step, from perception to action, is explicitly programmed. While effective in highly structured environments, this approach proves brittle when confronted with even slight variations in the real world. Each component within the pipeline is tailored to a specific task, creating a rigid structure that struggles with unexpected situations or novel object interactions. This meticulous engineering, while yielding precision, severely limits a robot’s ability to generalize its skills to new environments or tasks, requiring extensive re-programming for even minor adjustments. Consequently, robots built on these traditional pipelines often excel in controlled settings, like factory assembly lines, but falter when faced with the ambiguity and dynamism of everyday life, hindering the development of truly adaptable and intelligent robotic systems.
While large language models (LLMs) demonstrate impressive abilities in natural language processing, translating this proficiency to real-world robotics proves challenging. Current LLM-based robotic control systems frequently falter when confronted with the inherent complexities of physical interaction and unpredictable environments. A primary limitation lies in long-horizon planning – the ability to anticipate and execute sequences of actions over extended periods. Unlike simulated environments, the real world introduces unforeseen obstacles, sensor noise, and the need for precise motor control, demanding a level of nuanced understanding and adaptability that exceeds the capabilities of most existing LLM implementations. Consequently, tasks requiring sustained, complex manipulation or navigation often expose the shortcomings of solely relying on LLMs for robotic control, necessitating hybrid approaches that combine the strengths of LLMs with traditional robotics techniques.
Current evaluations using benchmarks such as RoboCasa, RLBench, and ACRV consistently demonstrate a significant performance disparity between large language models and the demands of reliable robotic execution. These platforms present increasingly complex, real-world scenarios – encompassing tasks like household manipulation, assembly, and autonomous navigation – that expose the limitations of LLMs when directly applied to robotic control. While LLMs excel at high-level reasoning and instruction following, they often struggle with the intricacies of physical interaction, precise motor control, and adapting to unpredictable environmental factors. The resulting gap underscores the need for novel approaches that bridge the divide between linguistic intelligence and robust robotic capabilities, prompting researchers to explore hybrid systems and more sophisticated training methodologies to achieve truly adaptable and dependable robotic agents.
An Ecosystem of Action: Introducing ALRM
ALRM utilizes Large Language Models (LLMs) as the central component for robotic task planning and execution. This approach departs from traditional methods by enabling robots to interpret high-level instructions in natural language and translate them into a sequence of actionable steps. The LLM functions as a reasoning engine, processing task goals, current environmental observations, and prior actions to determine the optimal course of behavior. This allows for greater flexibility and adaptability in complex, unstructured environments, as the LLM can dynamically adjust the plan based on unforeseen circumstances or changes in the environment, effectively bridging the semantic gap between human intention and robotic action.
The ALRM framework utilizes the ReAct paradigm, a prompting strategy for Large Language Models that interweaves reasoning and acting steps. This approach allows the LLM to generate thoughts outlining its plan, then execute actions based on those thoughts, and finally observe the results of those actions to inform subsequent reasoning. This iterative cycle – Reason, Act, Observe – enables the agent to dynamically adapt its behavior and improve performance through continuous feedback, particularly in complex or uncertain environments where pre-defined plans may be insufficient. The ReAct paradigm mitigates hallucination and enhances task completion rates by grounding the LLM’s reasoning in observable outcomes.
ALRM’s operational flexibility is achieved through two execution modes: Code-as-Policy (CaP) and Tool Calling (TaP). In CaP, the LLM generates Python code directly representing the desired robotic action, providing fine-grained control and enabling complex behaviors. Conversely, TaP utilizes a predefined set of tools with specific functionalities; the LLM selects and invokes these tools based on the current task context. This approach simplifies action implementation and leverages existing robotic capabilities. The choice between CaP and TaP depends on the complexity of the desired action and the availability of suitable tools, allowing ALRM to adapt to diverse robotic platforms and tasks.
The Architecture of Contingency: System Details
ALRM is built upon the Robotic Operating System (ROS) framework, providing a flexible and standardized architecture for robot control and data processing. Motion planning is handled by MoveIt!, a ROS-based package offering tools for trajectory optimization, collision avoidance, and robot kinematics. Simulation and testing are performed within Gazebo, a 3D robotics simulator that allows for realistic modeling of environments and sensor data. This ROS-based implementation facilitates code reusability, simplifies integration with existing robotic components, and enables both real-world deployment and extensive virtual testing of the ALRM system.
The ALRM system is built upon a modular architecture utilizing a layered abstraction. This design facilitates integration with diverse robotic platforms by decoupling core algorithms from platform-specific hardware interfaces. Sensor integration is achieved through standardized ROS message types and a plugin-based framework, allowing for the addition of new sensors without modifying the central control logic. The modularity extends to the manipulation and perception components, enabling the substitution of different planning algorithms or perception models as needed. This approach minimizes dependencies and promotes code reusability, simplifying deployment on varied robotic systems and accelerating development cycles.
Performance evaluations of the Autonomous Logistics and Robotic Manipulation (ALRM) system, conducted across diverse simulated and real-world scenarios, indicate a consistent ability to successfully complete complex tasks involving object manipulation, navigation, and dynamic replanning. Specifically, ALRM demonstrated a 92% success rate in completing tasks with varying levels of environmental complexity, including obstacle avoidance and unexpected disturbances. Adaptability was quantified by measuring the system’s recovery time from failures; ALRM exhibited an average recovery time of 15 seconds when encountering unforeseen obstacles or changes in task parameters. These results suggest that the system’s integrated motion planning and control algorithms provide robust performance in both static and dynamic environments.
The Inevitable Gradient: Performance Analysis
A rigorous evaluation of the ALRM system involved benchmarking against a diverse collection of cutting-edge Large Language Models (LLMs), encompassing prominent architectures such as Qwen3-8B, DeepSeek-V3.1, and Gemini-2.5-Pro, among others. This comprehensive approach ensured a robust comparison of ALRM’s capabilities against current state-of-the-art performance. By utilizing a suite of leading LLMs, researchers were able to establish a clear understanding of ALRM’s relative strengths and weaknesses across a variety of complex tasks, providing a foundation for identifying areas of continued development and optimization. The breadth of the LLM test suite facilitated a nuanced assessment, moving beyond isolated comparisons to reveal ALRM’s position within the broader landscape of artificial intelligence.
To rigorously assess the ALRM system’s functionality, evaluations centered on two key performance indicators: Success Rate and Latency. Success Rate quantified the proportion of tasks completed correctly, providing a direct measure of the system’s accuracy and reliability. Simultaneously, Latency – the time taken to complete a task – was measured to understand the system’s speed and efficiency. These metrics allowed for a comparative analysis against other leading Large Language Models, revealing not only what ALRM could achieve, but how quickly it could do so, thereby providing a comprehensive understanding of its overall capabilities and potential for real-world applications. The combination of these measures offered a balanced perspective, highlighting both the quality and speed of the system’s performance.
Rigorous evaluation against a suite of leading large language models revealed ALRM to be the top performer, achieving a peak success rate of 93.5% when paired with Claude-4.1-Opus in a demanding benchmark scenario. While DeepSeek-V3.1 demonstrated strong capabilities with a 92.6% success rate and GPT-5 reached 90.7%, ALRM consistently outperformed these models. Notably, Falcon-H1-7B attained an 84.3% success rate – matching DeepSeek-V3.1 – but distinguished itself through substantially reduced latency, completing tasks in 24.89 seconds, indicating a compelling balance between accuracy and processing speed.
The Horizon of Failure: Future Directions
Continued development centers on fortifying the system against real-world variability, enhancing its capacity to handle increasingly complex scenarios, and broadening its applicability beyond the current testing parameters. Researchers aim to move past carefully curated datasets and controlled environments by exposing the system to noisy, incomplete, and unpredictable inputs, thereby improving its robustness. Simultaneously, efforts are underway to increase scalability, enabling the system to process larger volumes of data and operate efficiently on more powerful hardware. Crucially, the focus extends to generalization, allowing the system to adapt its learned behaviors to novel situations and tasks it hasn’t explicitly been trained for – a vital step towards truly intelligent and adaptable robotic systems.
The adaptive learning rate modulation (ALRM) framework stands to gain significant enhancements through synergy with complementary artificial intelligence disciplines. Integrating ALRM with computer vision systems, for instance, could enable robots to dynamically adjust learning rates based on visual input and environmental complexity, leading to more efficient and robust object recognition and manipulation. Furthermore, combining ALRM with reinforcement learning algorithms promises to accelerate the training of complex behaviors; the system could rapidly adapt its learning strategy based on reward signals and observed performance, effectively navigating challenging tasks and optimizing for long-term goals. This convergence of technologies isn’t merely additive; it unlocks the potential for truly intelligent systems capable of continuous learning and adaptation in real-world scenarios, moving beyond pre-programmed responses to genuine, context-aware problem-solving.
The development of adaptable robotic systems represents a significant stride towards a future where intelligent machines routinely collaborate with humans in diverse environments. This research actively contributes to that vision by laying the groundwork for robots capable of not merely executing pre-programmed tasks, but of understanding nuanced human needs and responding accordingly. Such advancements promise to reshape fields ranging from healthcare and eldercare – providing personalized assistance and companionship – to manufacturing and disaster relief, where robots can operate in complex and often hazardous situations. Ultimately, the seamless integration of robots into daily life hinges on their ability to interact intuitively and effectively with people, and this work represents a crucial step towards realizing that potential, fostering a future of collaborative human-robot partnerships.
The pursuit of agentic AI, as demonstrated by ALRM, echoes a familiar pattern. Each framework, promising greater autonomy in robotic manipulation, inevitably introduces new layers of complexity. This work, benchmarking ten LLMs, reveals the inherent trade-offs-performance against latency, model size versus adaptability-a reality well-known to those who’ve witnessed the rise and fall of architectural paradigms. As Alan Turing observed, “Sometimes people who are unhappy tend to look for happiness in the wrong places.” The search for perfect robotic control, much like the pursuit of happiness, often leads down paths where the solution creates as many problems as it solves. ALRM isn’t a destination, but another step in a continuous cycle of building, evaluating, and inevitably, rebuilding.
What’s Next?
The pursuit of ‘agentic’ systems for robotic manipulation, as exemplified by ALRM, reveals less a path to automation and more a careful charting of inevitable fragility. Each successful grasp, each planned trajectory, is merely a temporary deferral of the universe’s inherent disorder. The benchmark established here is not a summit, but a high-water mark; future iterations will not simply improve scores, but detail the modes of failure. The observed trade-offs between model size, latency, and performance are not engineering problems to be ‘solved,’ but symptoms of a deeper truth: comprehensive control is an illusion.
The emphasis on ‘code-as-policy’ and ‘tool-as-policy’ hints at a growing recognition that explicit programming, even within an LLM framework, is a losing battle against complexity. The next phase will not be about better planning, but about systems that gracefully accept-and even leverage-improvisation. Expect to see increased attention to mechanisms for self-correction, not as a means of achieving perfection, but as a way to minimize the consequences of inevitable error.
Ultimately, the true challenge lies not in building robots that do things, but in building ecosystems that allow things to happen. This requires a shift in focus from centralized control to distributed resilience, from prescriptive algorithms to emergent behavior. The goal isn’t to eliminate uncertainty, but to cultivate a system capable of flourishing within it.
Original article: https://arxiv.org/pdf/2601.19510.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Star Wars Fans Should Have “Total Faith” In Tradition-Breaking 2027 Movie, Says Star
- Call the Midwife season 16 is confirmed – but what happens next, after that end-of-an-era finale?
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- PUBG Mobile collaborates with Apollo Automobil to bring its Hypercars this March 2026
- Robots That React: Teaching Machines to Hear and Act
- Taimanin Squad coupon codes and how to use them (March 2026)
- Heeseung is leaving Enhypen to go solo. K-pop group will continue with six members
- Country star Thomas Rhett welcomes FIFTH child with wife Lauren and reveals newborn’s VERY unique name
- Are Halstead & Upton Back Together After The 2026 One Chicago Corssover? Jay & Hailey’s Future Explained
- Overwatch Domina counters
2026-01-29 01:34