Author: Denis Avetisyan
A new hardware-software approach leverages resistive memory to drastically improve the efficiency of machine unlearning and continual learning, paving the way for more adaptable AI systems.
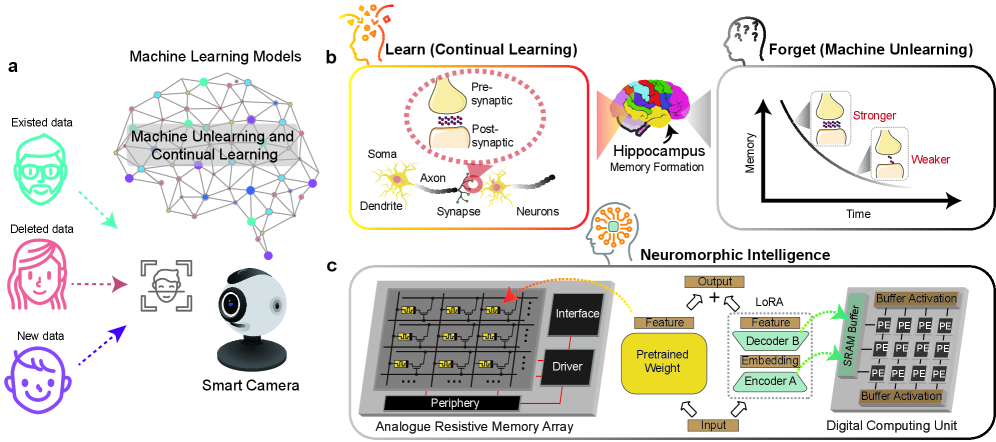
This review details a co-designed system using resistive memory and low-rank adaptation for energy-efficient machine unlearning and continual learning on neuromorphic computing platforms.
Modern machine learning demands both continual adaptation and the ability to selectively ‘forget’ data, yet achieving this efficiently on emerging neuromorphic hardware remains a significant challenge. This work, ‘Resistive Memory based Efficient Machine Unlearning and Continual Learning’, introduces a hardware-software co-design leveraging resistive memory and low-rank adaptation to address these limitations. By confining updates to compact parameter branches and employing a hybrid analogue-digital compute-in-memory system, the prototype achieves substantial reductions in training cost, deployment overhead, and inference energy across privacy-sensitive tasks. Could this approach pave the way for truly secure and energy-efficient neuromorphic intelligence at the edge, enabling practical data privacy in rapidly evolving AI systems?
The Paradox of Data and Privacy in Modern AI
The proliferation of modern artificial intelligence, particularly in applications like facial and voice recognition, is fundamentally reliant on expansive datasets-collections of personal information that frequently raise substantial privacy concerns. These systems aren’t built on abstract algorithms alone; they learn by identifying patterns within massive quantities of data, often encompassing biometric details, behavioral traits, and personally identifiable information. Consequently, the pursuit of increasingly accurate AI models inevitably clashes with the imperative to safeguard individual privacy, creating a complex ethical and practical dilemma for developers and policymakers. The very power of these technologies to accurately identify and categorize individuals stems from the scale of data used in their training, demanding careful consideration of data collection, storage, and usage practices to mitigate potential risks.
Conventional machine learning models exhibit a fundamental limitation: an inability to truly ‘forget’ training data. Unlike humans, who can selectively suppress memories, these models retain traces of every data point used in their construction. This poses a significant challenge for responsible AI deployment, particularly when dealing with sensitive information. If a user requests the removal of their data – a right increasingly enshrined in privacy regulations – simply deleting the data from the dataset isn’t sufficient. The model’s parameters still encode information derived from that data, potentially allowing for its reconstruction or indirect inference. This ‘memorization’ effect not only violates privacy principles but also creates legal and ethical concerns, demanding innovative approaches to model training and data management that prioritize the ability to selectively unlearn without catastrophic performance degradation.
The demand for techniques enabling selective data removal from AI models stems from a fundamental tension between data utility and privacy preservation. Current machine learning paradigms often ‘memorize’ training data, creating vulnerabilities to data breaches and hindering compliance with evolving data protection regulations. Researchers are actively exploring methods – including techniques like differential privacy, federated learning, and ‘unlearning’ algorithms – designed to surgically remove the influence of specific data points without catastrophic performance degradation. These approaches aim to strike a balance, allowing models to retain generalizable knowledge while respecting individual privacy rights and enabling responsible AI deployment in sensitive domains such as healthcare and finance. The development of robust and efficient unlearning techniques represents a crucial step towards building trustworthy and ethically aligned artificial intelligence systems.
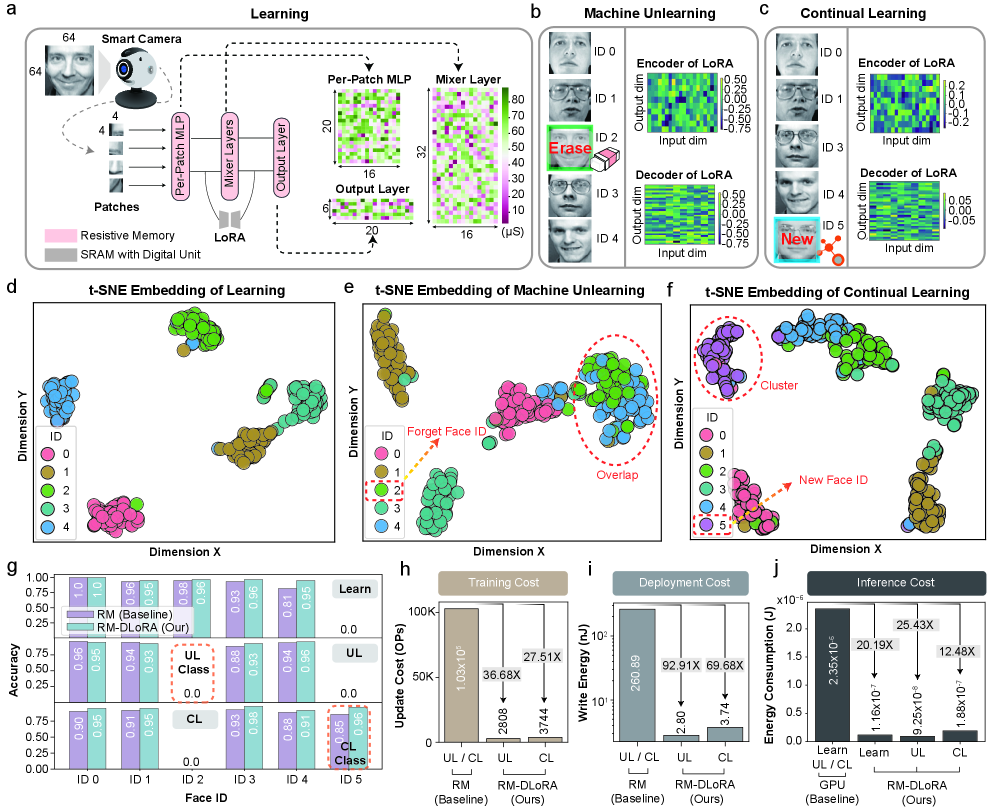
Data Control Through Machine Unlearning
Machine unlearning addresses growing privacy and safety concerns by enabling the selective removal of data influence from trained machine learning models. Traditional model retraining to comply with data deletion requests is computationally expensive and time-consuming. Unlearning techniques, conversely, aim to modify model parameters directly to diminish the impact of specific data points without a full retraining cycle. This is achieved by identifying and neutralizing the contributions of the target data to the model’s learned weights, effectively ‘forgetting’ the information without disrupting the model’s performance on other data. Consequently, machine unlearning offers a more efficient and scalable solution for adhering to data privacy regulations, such as GDPR and CCPA, and for mitigating risks associated with potentially harmful or sensitive data embedded within a model.
Several machine unlearning techniques circumvent the need for complete model retraining by directly manipulating model parameters. Gradient ascent, for example, adjusts weights in the direction opposite the gradient calculated from the data to be removed, effectively diminishing its influence on the model’s output. Label obfuscation methods operate by altering or removing the labels associated with specific data points within the training set, thereby reducing the model’s reliance on those particular instances. These approaches offer computational advantages over full retraining, particularly for large datasets and complex models, as they target only the parameters most affected by the data slated for removal. The efficiency of these techniques depends on factors such as the data’s saliency and the model’s architecture, but they represent a significant advancement in data control within machine learning systems.
Machine unlearning facilitates model adaptation to evolving data regulations, such as those outlined in GDPR and CCPA, by enabling the selective removal of data impact without complete model retraining. This is critical as legal frameworks surrounding data privacy are subject to change and differing regional requirements. Furthermore, unlearning supports responsiveness to individual user preferences regarding their data; users can request the removal of their contributions from a model, and the system can comply by reducing the model’s reliance on that specific data point. This dynamic adaptability minimizes the need for costly and time-consuming full model rebuilds each time regulations shift or user requests are received, offering a scalable solution for maintaining compliance and respecting user control.
![A recurrent spiking neural network (RSNN) employing LoRA-based digital updates ([RM-DLoRA]) demonstrates effective learning, unlearning, and continual learning for speaker authentication on the Spiking Speech Commands dataset, achieving significant reductions in training cost (approximately 25.16×), write energy (approximately 63.74×), and inference energy (up to 12.03× compared to a GPU and conventional reprogramming methods) while mitigating accuracy degradation from noise and conductance drift.](https://arxiv.org/html/2601.10037v1/x4.png)
Hybrid Analogue-Digital CIM: The Hardware Foundation
Hybrid analogue-digital Compute-In-Memory (CIM) systems address the growing need for efficient machine unlearning by performing computations directly within the memory array. Traditional machine unlearning requires revisiting and updating model weights stored separately from processing units, resulting in significant data movement and energy expenditure. CIM architectures, conversely, leverage the physical properties of memory elements to perform computations – including those required for unlearning – in situ. This minimizes data transfer between memory and processor, thereby reducing both latency and energy consumption. The ability to directly manipulate synaptic weights within the memory array facilitates the selective removal of learned information, crucial for applications demanding data privacy and model adaptation.
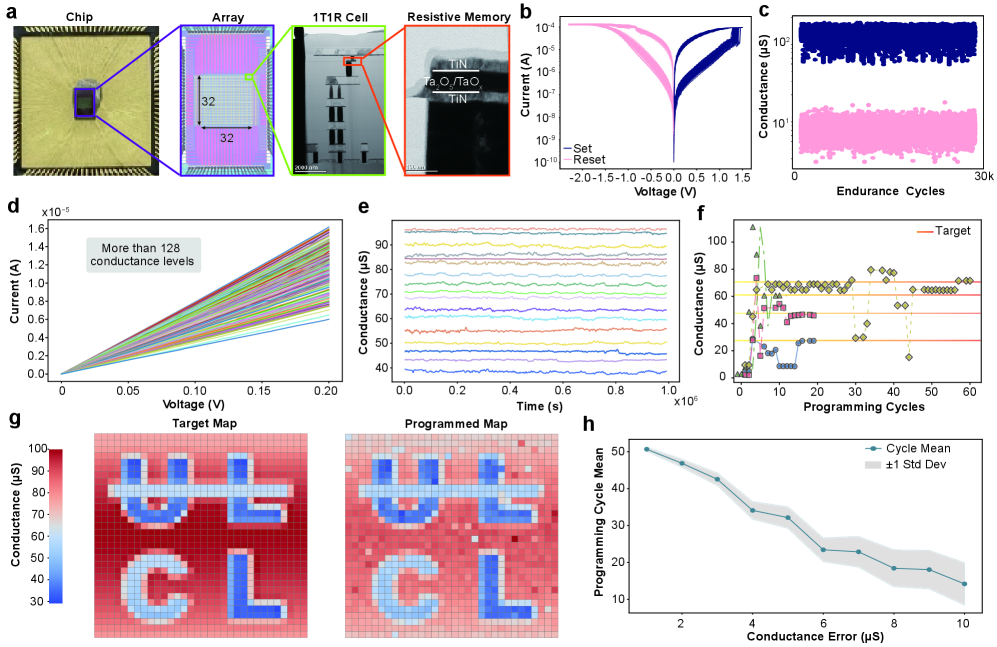
The foundational element of this hybrid analogue-digital Compute-In-Memory (CIM) system is the 1T1R (one transistor, one resistor) cell, leveraging resistive switching behavior within a specifically engineered material stack. This stack consists of Titanium Nitride (TiN) functioning as the electrodes, with a switching layer composed of Tantalum Pentoxide (Ta2O5) and Tantalum Oxide (TaOx) positioned between them. The resistance of the Ta2O5/TaOx layer is modulated by applied voltages, allowing for multiple resistance states to be programmed and read. This capability enables analogue weight storage directly within the memory array, facilitating efficient in-memory computation and bypassing the data movement bottlenecks associated with conventional digital systems.
Compute-In-Memory (CIM) architectures, utilizing resistive random-access memory (RRAM) based on materials like TiN/Ta2O5/TaOx/TiN, enable in-memory updates by performing computations directly within the memory array. This contrasts with the von Neumann architecture, which necessitates data transfer between separate processing and memory units. Eliminating this data movement substantially reduces energy consumption, as data transfer is a significant energy bottleneck in conventional systems. Furthermore, performing computations in-memory minimizes latency, as the time required for data retrieval and return is avoided, resulting in faster overall processing speeds and improved system efficiency.
Hybrid analogue-digital Compute-In-Memory (CIM) systems demonstrate significant performance gains when applied to generative models like Latent Diffusion Models for stylized image generation. Benchmarking has shown a reduction in training cost of up to 147.76x across a range of image processing tasks when utilizing this hardware architecture. This improvement stems from the CIM system’s ability to perform in-memory computations, bypassing the data transfer bottlenecks inherent in traditional von Neumann architectures and thereby reducing both energy consumption and latency during the training process.
Continual Learning: Towards Adaptive Intelligence
Artificial intelligence is rapidly transitioning from systems trained on fixed datasets to those capable of continuous evolution, a feat achieved through continual learning. This approach, bolstered by a hybrid Compute-In-Memory (CIM) architecture, allows AI models to assimilate new information without entirely overwriting previously acquired knowledge. Unlike traditional models requiring complete retraining with each update, continual learning facilitates incremental adaptation, mirroring the human capacity to build upon past experiences. The CIM architecture proves instrumental by accelerating the learning process and reducing energy consumption, effectively enabling the AI to refine its understanding and performance over time, much like a developing expertise. This dynamic capability positions continual learning as a cornerstone for building truly intelligent systems that can respond and improve in ever-changing real-world scenarios.
A significant hurdle in artificial intelligence development, known as catastrophic forgetting, occurs when a model, after learning new information, abruptly loses previously acquired knowledge. To combat this, researchers are increasingly implementing replay buffers – essentially, a ‘memory’ where the system stores a small selection of past experiences. This allows the model to intermittently revisit and reinforce earlier learning while assimilating new data, preventing the wholesale erasure of prior knowledge. By strategically replaying these stored experiences alongside new inputs, the model effectively consolidates information, fostering a more stable and cumulative learning process. This technique is crucial for building AI systems capable of continuous adaptation and improvement in dynamic, real-world scenarios, rather than requiring complete retraining with each new task.
The evolution of artificial intelligence is increasingly focused on systems that transcend the limitations of static models. Traditional AI often requires complete retraining for each new task, a process that is computationally expensive and impractical for dynamic environments. This new paradigm prioritizes continual learning, enabling AI to accumulate knowledge incrementally, much like human learning. Consequently, these dynamic, adaptive systems can address real-world challenges – from navigating unpredictable terrains to responding to evolving cybersecurity threats – with greater efficiency and resilience. The ability to learn and adapt without catastrophic forgetting represents a significant leap towards more robust and versatile AI, paving the way for applications that can operate effectively in constantly changing conditions and ultimately deliver more intelligent and responsive solutions.
The practical implications of this continual learning framework are particularly striking when applied to privacy-sensitive applications like facial and voice recognition. Deploying such systems traditionally demands immense computational resources; however, this approach demonstrably minimizes those demands, achieving a remarkable 25.16x to 387.95x reduction in training costs. Beyond streamlined development, the framework also significantly lessens the energy consumption during actual use, with inference energy decreasing by a factor of 6.13x to 48.44x. These substantial gains not only pave the way for more accessible and sustainable AI solutions, but also highlight a path toward responsible deployment, where powerful capabilities are no longer limited by prohibitive resource requirements and environmental impact.
The pursuit of efficient machine learning, as detailed in this work concerning resistive memory and continual learning, echoes a fundamental principle of system design: structure dictates behavior. This research demonstrates how a carefully considered hardware-software co-design, leveraging the unique properties of resistive memory, can drastically alter the energy consumption and training costs associated with adapting models. As Ken Thompson aptly stated, “The best programs are small and simple.” The elegance of this approach lies in its ability to achieve significant gains not through complexity, but through a disciplined focus on the essential-efficiently updating models without catastrophic forgetting, mirroring a system where each component contributes to the overall, streamlined function.
Future Directions
The presented work, while demonstrating a compelling convergence of device physics and algorithmic efficiency, merely scratches the surface of what is possible with resistive memory-based continual learning. The current emphasis on low-rank adaptation addresses the symptom – catastrophic forgetting – but not the underlying pathology. A truly robust system will require a deeper understanding of how synaptic plasticity, at the device level, can intrinsically support knowledge consolidation and transfer, not simply approximate it.
Documentation captures structure, but behavior emerges through interaction. The demonstrated energy savings are encouraging, but they remain tethered to benchmark datasets and relatively static tasks. The real challenge lies in building systems that can learn and unlearn in genuinely unstructured, real-world environments. This necessitates exploration beyond supervised learning paradigms, and a willingness to embrace the inherent stochasticity of resistive memory devices-to view noise not as an impediment, but as a potential source of exploration and generalization.
Further research should investigate the limits of scaling this hybrid analogue-digital approach. Can the benefits of resistive memory be maintained as network complexity increases? And crucially, how can we move beyond incremental learning to enable genuinely compositional knowledge acquisition-the ability to combine existing skills in novel ways? The path forward isn’t simply about making existing algorithms faster; it’s about reimagining what learning itself means in the context of physically constrained computation.
Original article: https://arxiv.org/pdf/2601.10037.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- How to find the Roaming Oak Tree in Heartopia
- M7 Pass Event Guide: All you need to know
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
2026-01-18 18:16