Author: Denis Avetisyan
New research demonstrates that artificial intelligence can accurately anticipate human actions and their timing with remarkably little training data.
This study evaluates the few-shot temporal reasoning capabilities of large language models for human activity prediction within smart environments, outperforming traditional statistical approaches.
Predicting human behavior in dynamic environments remains challenging due to the scarcity of labeled data and the complexity of daily routines. This limitation motivates the work ‘Evaluating Few-Shot Temporal Reasoning of LLMs for Human Activity Prediction in Smart Environments’, which investigates the capacity of large language models to forecast human activities and their durations using minimal task-specific examples. Results demonstrate that these pre-trained models exhibit strong inherent temporal reasoning, achieving accurate predictions even with zero or few-shot prompting, and effectively capturing both habitual patterns and contextual variations. Could this approach unlock more robust and adaptable agent-based systems for increasingly complex cyber-physical environments?
The Inevitable Uncertainty of Action
The ability to anticipate human actions holds significant promise for the development of truly intelligent systems, ranging from personalized healthcare and preventative safety measures to responsive smart homes and efficient urban planning. However, predicting what a person will do next is an extraordinarily difficult undertaking; human behavior is rarely linear, influenced by a vast network of internal motivations, external stimuli, and unpredictable circumstances. Unlike predictable physical systems, individual actions are shaped by complex cognitive processes and are susceptible to sudden changes in intent, making reliable forecasting a persistent challenge. While advancements in machine learning offer potential solutions, effectively modeling this inherent complexity-and doing so with the necessary speed and accuracy for real-world applications-remains a key hurdle in the pursuit of proactive, assistive technologies.
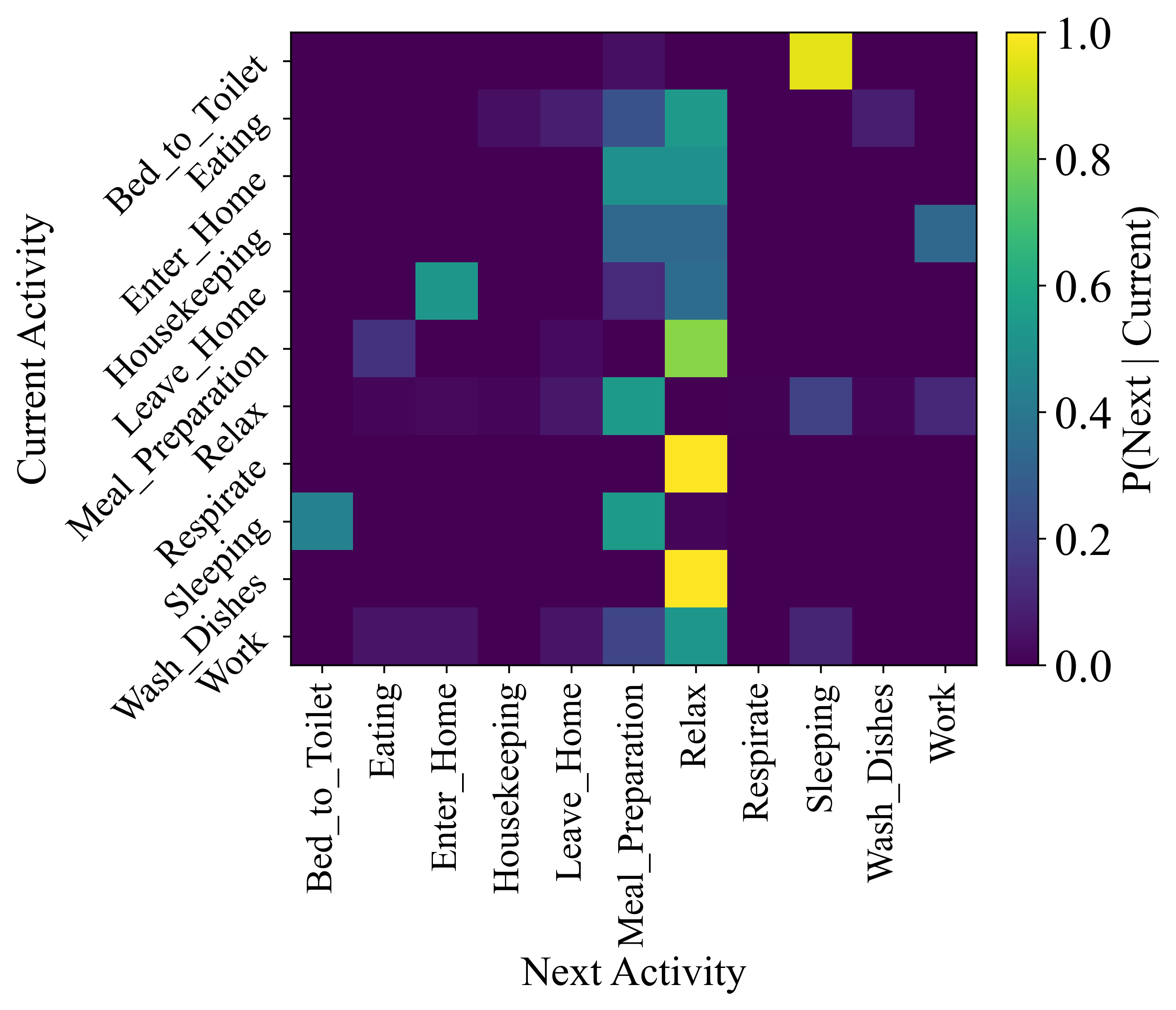
While established statistical techniques offer a degree of transparency in modeling human behavior, their limitations become apparent when attempting to predict the intricate sequences that define daily life. These methods often treat events as independent, failing to fully account for the subtle, yet crucial, temporal dependencies – the way one action reliably precedes another, or how the time of day influences choices. For instance, a simple model might predict coffee consumption based solely on individual preference, overlooking the strong correlation with morning routines or the influence of work schedules. This inability to capture these nuanced temporal patterns hinders accurate forecasting, particularly when dealing with the complex and often unpredictable nature of human activity, demanding more sophisticated approaches capable of discerning and leveraging these hidden relationships.
The proliferation of smart devices and ubiquitous sensing technologies generates a continuous stream of data detailing human activities, but effectively leveraging this information requires more than just increased computational power. Traditional methods struggle with the sheer scale and complexity of these datasets, necessitating intelligent algorithms capable of discerning patterns and predicting future behaviors. Machine learning techniques, particularly those focused on sequential data like recurrent neural networks and transformer models, offer a promising path forward. These approaches can efficiently model the temporal dependencies within daily routines, allowing systems to anticipate needs, optimize resource allocation, and provide proactive assistance – ultimately transforming raw data into actionable insights about human behavior.
Contextualizing the Present for Anticipated Futures
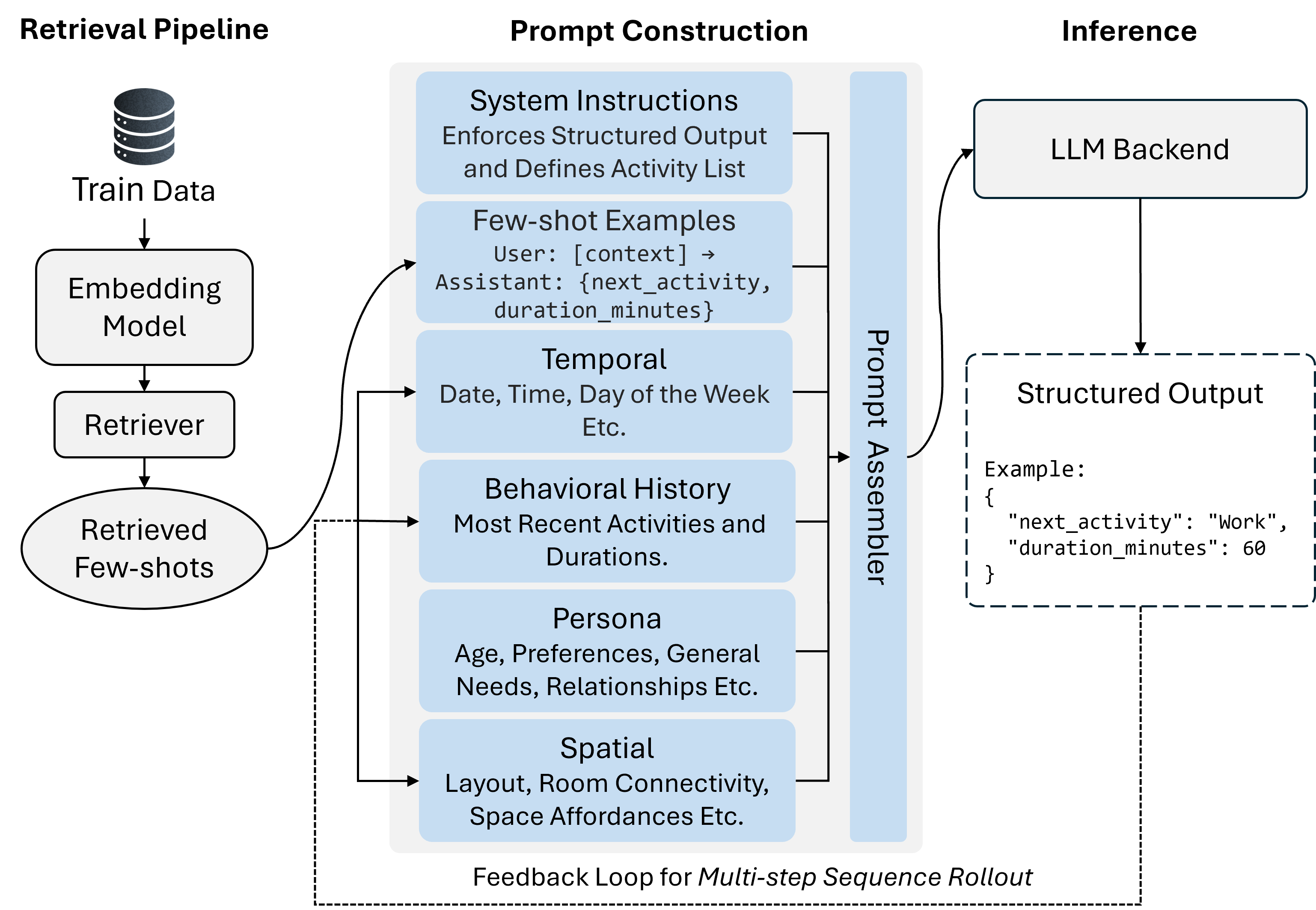
Accurate activity prediction using Large Language Models (LLMs) is fundamentally dependent on the quality of the input prompt, specifically its ability to represent the present state and relevant historical data – a process termed ‘Contextual Representation’. This involves encoding not just the immediate circumstances, but also a sufficient record of prior events to allow the LLM to infer likely future actions. Insufficient or inaccurate contextual information limits the LLM’s ability to move beyond simple extrapolation and perform meaningful prediction; conversely, a well-constructed prompt provides the necessary foundation for complex reasoning about sequential activities and potential outcomes. The effectiveness of Contextual Representation directly impacts the LLM’s ability to generalize from learned patterns and apply them to novel situations.
Prompt construction for LLM-based activity prediction relies on retrieving and incorporating examples of previously observed activities into the prompt itself. This moves beyond basic pattern recognition by providing the LLM with concrete instances to inform its predictions; instead of simply identifying frequently occurring sequences, the LLM can leverage the details of similar past events to assess the current situation. Retrieved examples function as demonstrations, illustrating the nuances of activity execution and enabling the LLM to generalize from specific instances rather than relying solely on statistical correlations within the training data. The selection of relevant examples is crucial, as the quality and representativeness of these demonstrations directly impact the accuracy and reliability of the LLM’s predictions.
Few-shot prompting initializes Large Language Model (LLM) activity prediction by providing a limited number of example activity sequences; however, performance improvements plateau rapidly, with optimal results typically achieved using only one or two demonstrations. Retrieval-augmented prompting builds upon this foundation by dynamically supplementing the initial examples with relevant historical data retrieved from a knowledge base. This process identifies past events similar to the current context and incorporates them into the prompt, effectively increasing the LLM’s contextual understanding without requiring extensive manual example creation. The combination allows the LLM to extrapolate from both generalized patterns and specific, dynamically retrieved instances, resulting in more accurate predictions than either technique alone.
Validating Predictive Accuracy Through Empirical Observation
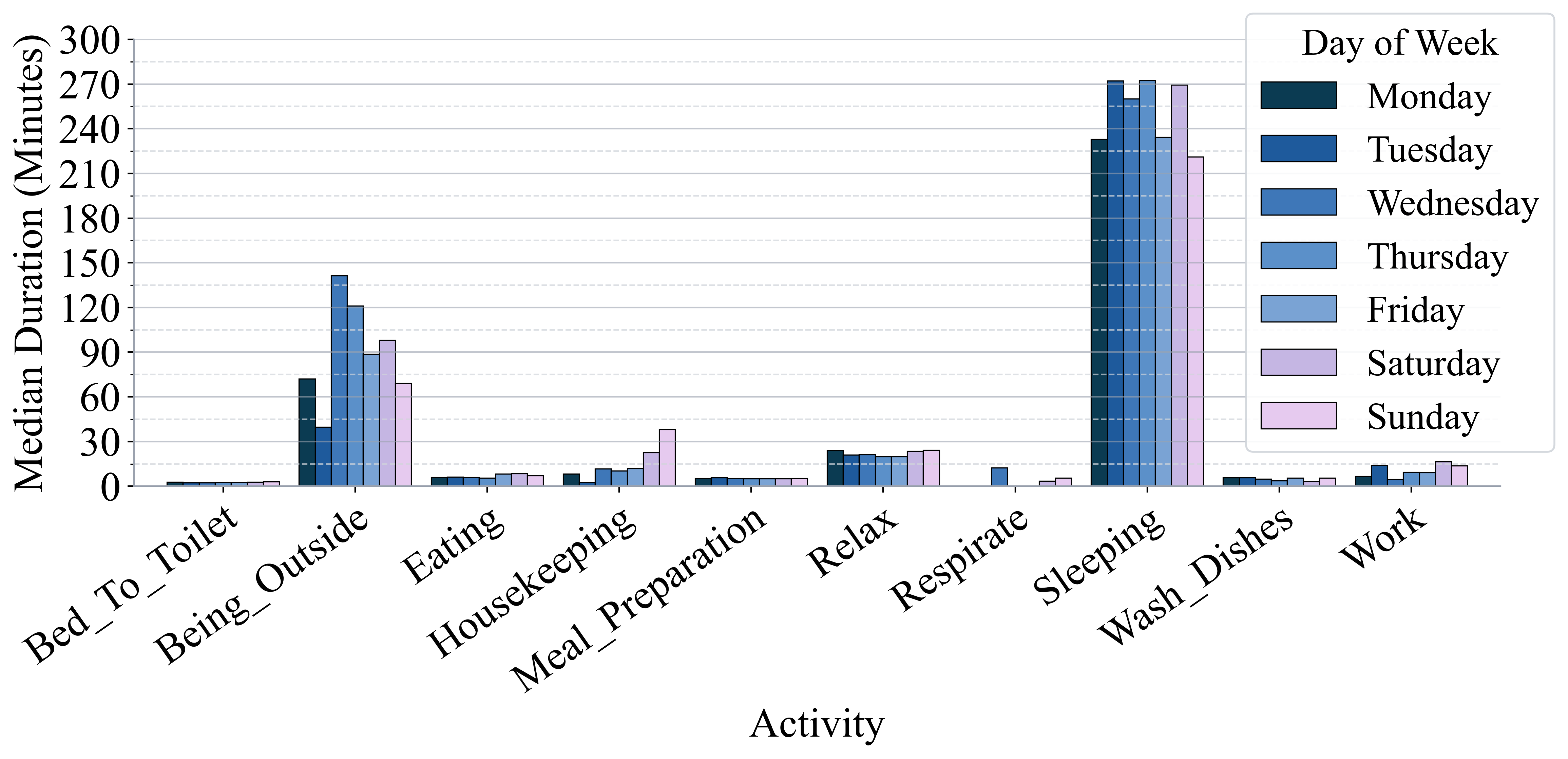
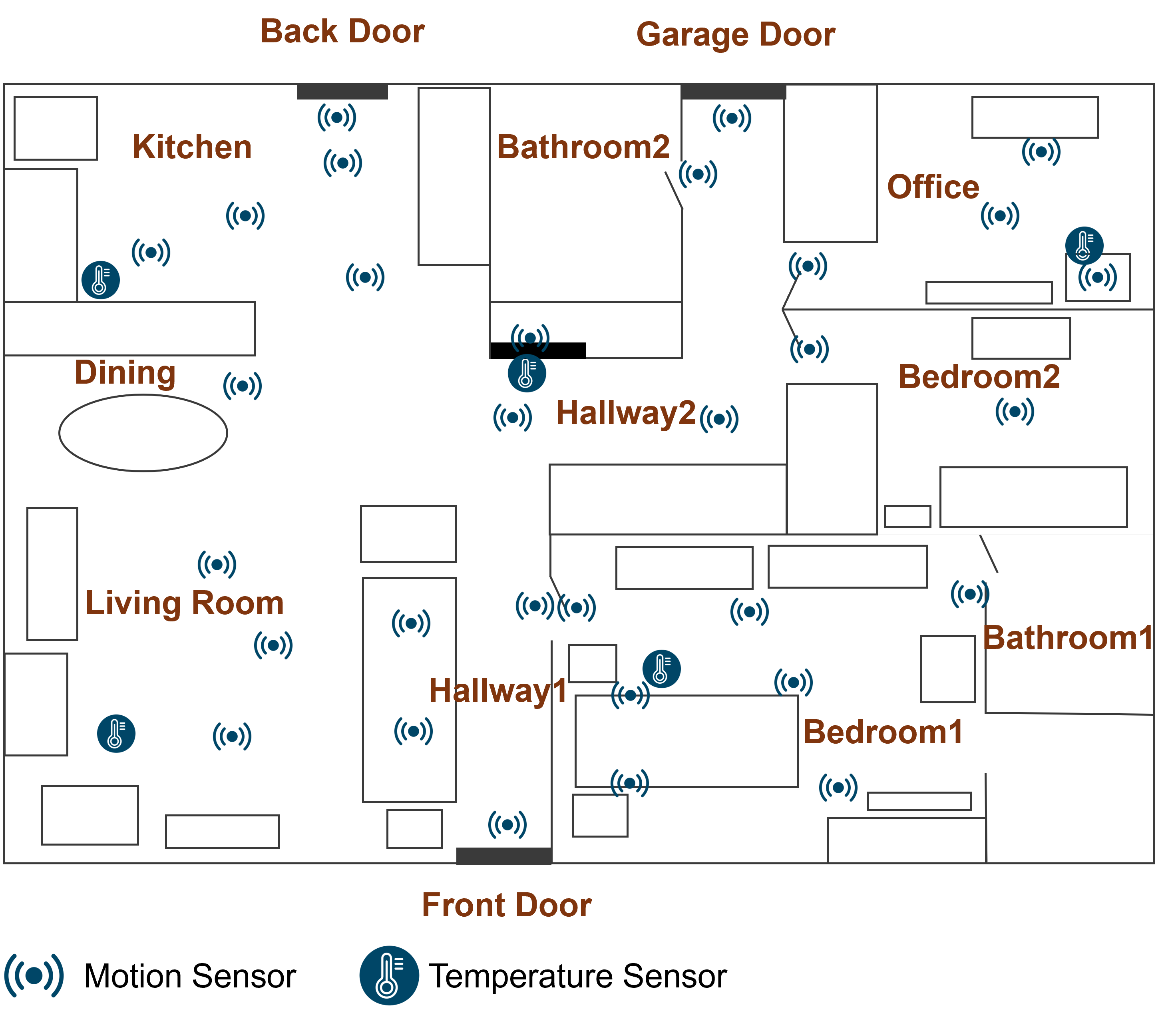
The CASAS Aruba Dataset served as the primary evaluation resource for the proposed activity recognition and prediction framework. This dataset is a widely adopted benchmark within the research community, providing a standardized collection of sensor data captured from a smart home environment over an extended period. The dataset includes detailed logs of occupant activities, environmental conditions, and sensor readings, facilitating robust performance comparisons against existing methods. Utilizing this established dataset ensured the results are reproducible and directly comparable to published results employing the same evaluation criteria and data partitioning schemes.
Evaluation of the proposed activity prediction framework utilized the CASAS Aruba Dataset and incorporated a comparison against a Markov Model, a commonly used statistical baseline. Results demonstrated a significant improvement in prediction accuracy, specifically exceeding 50% in temporal alignment when contrasted with the baseline model. This improvement is quantified by a reduction in the Dynamic Time Warping (DTW) – Normalized score from 0.27 (Markov Model) to a range of 0.12-0.15 achieved by the proposed framework. This data indicates a substantial advancement in the precision of predicted activity timings compared to the traditional statistical approach.
Evaluation using the CASAS Aruba Dataset demonstrated a significant reduction in the Dynamic Time Warping (DTW) – Normalized score, a metric quantifying the dissimilarity between predicted and actual activity sequences. The baseline Markov Model achieved a DTW – Normalized score of 0.27. Implementation of the proposed framework resulted in a reduction of this score to a range of 0.12 to 0.15, indicating improved temporal alignment between predicted and observed activities. This improvement signifies a more accurate representation of activity timing and duration as determined by the DTW metric.
The framework’s predictive capability extends beyond single next-activity prediction to encompass multi-step activity rollout, enabling the forecasting of entire action sequences and their corresponding durations. Evaluation using the CASAS Aruba Dataset demonstrated a significant reduction in cumulative Dynamic Time Warping (DTW) distance; the baseline measurement of 309 minutes was reduced to a range of 142-170 minutes, indicating improved accuracy in forecasting extended activity patterns and their temporal characteristics.
Agent-Based Modeling (ABM) was implemented to simulate and validate predicted activity sequences, serving as a complementary analytical method. Performance metrics demonstrated an accuracy of 0.528 when the model was provided with two few-shot demonstrations. Additionally, the framework achieved a Macro-F1 Score of 0.476 using only one few-shot demonstration, indicating a capacity for effective prediction even with limited example data.
Beyond Prediction: Projecting Plausible Situational Evolutions
Traditional activity prediction often focuses on identifying what will happen next, but this framework proposes a shift towards ‘Situation Projection’-a more holistic approach that infers entire future states based on a comprehensive understanding of the present context and patterns gleaned from historical data. This isn’t simply about forecasting a single action; it’s about constructing a plausible projection of the evolving situation, considering not just likely events, but also the interconnectedness of elements within that environment. By leveraging current conditions and learned experiences, the system builds a dynamic model of potential futures, allowing for a more nuanced and adaptable response to unfolding circumstances. This move from predicting isolated actions to projecting comprehensive situations represents a fundamental change in how intelligent systems can anticipate and proactively engage with the world.
Traditional predictive models often struggle when faced with the inherent unpredictability of real-world scenarios, frequently generating rigid forecasts that fail to account for evolving conditions. A shift towards nuanced prediction acknowledges that future states aren’t predetermined but rather exist as a range of possibilities influenced by context. This approach allows systems to move beyond simply forecasting what will happen, and instead assess how likely different outcomes are, given current information and historical trends. By explicitly incorporating uncertainty, these models become more adaptive, capable of adjusting predictions as new data emerges and mitigating the impact of unforeseen circumstances. This capability is crucial for creating intelligent systems that can reliably operate in dynamic environments and provide robust, context-aware assistance.
The convergence of large language models (LLMs), contextual reasoning, and predictive modeling is establishing a foundation for intelligent environments capable of anticipating human needs. These systems move beyond simply reacting to requests; they leverage LLMs to interpret complex situations, integrating historical data and real-time context to project likely future states. This proactive capability allows for the pre-emptive adjustment of settings, the offering of timely information, and the automation of tasks before a user even initiates them. Imagine a home that adjusts temperature and lighting based on predicted occupancy, or a vehicle that anticipates route changes due to traffic patterns – these are not futuristic fantasies, but increasingly viable possibilities enabled by this integrated approach to intelligence, promising a future where technology seamlessly enhances daily life.
![Performance benefits from prioritizing parameter tuning ([PT]) when data is limited, while data augmentation ([D]) becomes more impactful as data volume increases.](https://arxiv.org/html/2602.11176v1/figures/tradeoff_plot.png)
The study meticulously details a system designed to forecast human activities, acknowledging the inherent impermanence of any predictive model. Like all constructions, this activity forecast is subject to decay, its accuracy diminishing as the environment shifts and behaviors evolve. Brian Kernighan observes, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This sentiment resonates with the challenge of maintaining temporal reasoning in LLMs; initial ingenuity in prompting and retrieval augmentation must be continually refined as the ‘code’ – the model’s understanding of temporal relationships – inevitably requires debugging through ongoing evaluation and adaptation. The paper’s emphasis on few-shot learning acknowledges that stability is, indeed, an illusion cached by time, requiring constant recalibration to remain effective.
What Lies Ahead?
This work establishes that large language models can, with minimal instruction, extrapolate plausible activity durations within a smart environment – a seemingly simple feat, yet one historically demanding of meticulously curated statistical models. However, logging is the system’s chronicle, not its future. The model’s performance, while promising, remains tethered to the quality and breadth of its pre-training. The inevitable drift in real-world data distributions presents a continuing challenge; the model’s knowledge, however vast, is a snapshot in time, and its predictive power will gradually degrade as environments evolve.
Future research must address the question of graceful decay. Simply increasing model scale will not suffice. The focus should shift towards mechanisms for continuous learning and adaptation – not merely refining predictions, but actively identifying and incorporating shifts in behavioral patterns. Furthermore, understanding the limits of extrapolation is critical. The model excels at predicting common activities, but how does it handle novel or anomalous events? Deployment is a moment on the timeline, not a guarantee of perpetual accuracy.
Ultimately, the true measure of success will not be predictive accuracy alone, but the system’s ability to anticipate its own limitations. A truly intelligent system acknowledges the entropy inherent in complex environments and proactively seeks to mitigate the effects of time. The challenge, then, is not to build a perfect predictor, but to create a system that ages gracefully, learning and adapting as the world inevitably changes.
Original article: https://arxiv.org/pdf/2602.11176.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Gold Rate Forecast
2026-02-14 04:48