Author: Denis Avetisyan
A novel approach combines statistical analysis with agent-based modeling to accurately forecast how large language models will perform on diverse tasks.
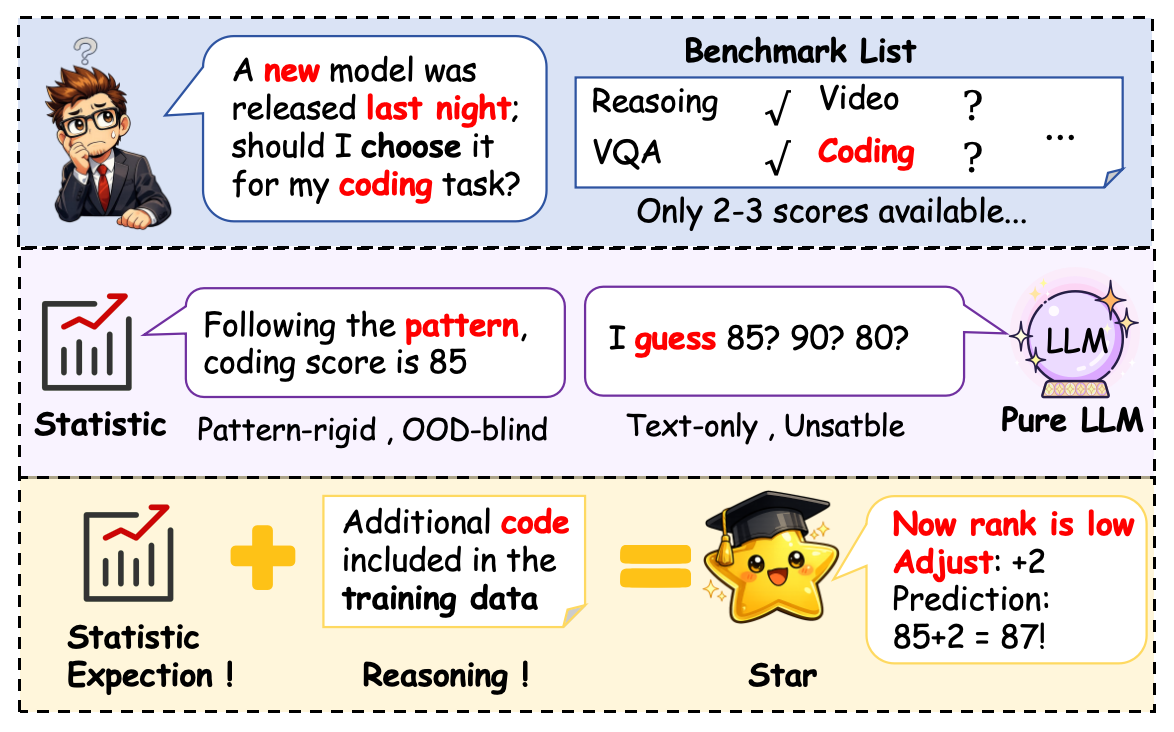
STAR, a framework bridging statistical and agentic reasoning, provides efficient and explainable performance predictions for large language models.
Evaluating the performance of large language models is increasingly challenging due to prohibitive computational costs, yet existing methods struggle with data scarcity and lack interpretability. To address this, we introduce ‘STAR : Bridging Statistical and Agentic Reasoning for Large Model Performance Prediction’, a novel framework that synergistically combines data-driven statistical modeling with knowledge-guided agentic reasoning. STAR leverages external knowledge and uncertainty quantification within a Constrained Probabilistic Matrix Factorization, refining predictions through comparative analysis and credibility assessment to deliver explainable adjustments. Can this hybrid approach unlock more efficient and reliable benchmarks for the rapidly evolving landscape of large language models?
Beyond Superficial Scores: Unveiling True Reasoning in Large Language Models
Contemporary evaluation of large language models (LLMs) is significantly shaped by the observation of scaling laws – the predictable improvement in performance as model size and training data increase. However, this emphasis often overshadows the assessment of nuanced reasoning – the ability to handle ambiguity, apply common sense, and perform complex inference. While larger models demonstrably excel at pattern recognition and memorization, improvements on standard benchmarks don’t necessarily translate to genuine cognitive capabilities. Consequently, LLMs can achieve high scores through superficial correlations rather than deep understanding, creating a performance plateau where further scaling yields diminishing returns in true reasoning ability. This highlights a critical need to move beyond simply measuring what LLMs can do and focus on evaluating how they arrive at their conclusions, necessitating benchmarks designed to probe for genuine understanding rather than statistical proficiency.
The reliance on standardized benchmarks in large language model (LLM) evaluation frequently yields performance metrics that overestimate true capabilities when applied to genuine, multifaceted problems. These benchmarks, often designed for simplicity and scalability, typically distill complex tasks into isolated components, neglecting the crucial interplay of reasoning, contextual understanding, and common sense required in real-world scenarios. Consequently, an LLM might achieve a high score on a benchmark by exploiting statistical correlations within the dataset, rather than demonstrating genuine intelligence or problem-solving ability. This disconnect arises because benchmarks often fail to account for ambiguities, nuanced language, or the need for external knowledge-factors ubiquitous in everyday tasks. The resulting inflated estimates can mislead developers and users, creating a false impression of an LLM’s readiness for deployment in complex, unpredictable environments and hindering progress towards truly intelligent systems.
The current landscape of large language model (LLM) evaluation demands a shift towards methodologies grounded in statistical rigor and robustness. Existing benchmarks, while useful for tracking progress, often fail to adequately capture the subtleties of genuine reasoning and can be susceptible to gaming or superficial pattern matching. A statistically sound approach necessitates larger, more diverse datasets, coupled with evaluation metrics that move beyond simple accuracy scores to assess the confidence, uncertainty, and generalization capabilities of these models. This includes employing techniques like Bayesian statistics to quantify model uncertainty and developing benchmarks specifically designed to test for adversarial vulnerabilities and biases. Ultimately, a more robust evaluation framework is crucial not only for accurately gauging the true capabilities of LLMs, but also for guiding future research and ensuring their responsible deployment in real-world applications.
The advent of sophisticated large language model (LLM) training techniques, such as Mixture-of-Experts (MoE) and Reinforcement Learning from Human Feedback (RLHF), presents significant challenges to standardized evaluation. MoE architectures, while boosting capacity, introduce inherent variability as different ‘expert’ networks handle individual inputs, making performance less predictable and harder to replicate across runs. Similarly, RLHF, reliant on subjective human preferences, injects bias and inconsistency into the training process – a model optimized for one set of human annotators may perform differently with another. This reliance on nuanced, and often opaque, training signals complicates the interpretation of benchmark results, potentially masking genuine improvements in reasoning ability with artifacts of the training methodology itself. Consequently, current evaluation metrics struggle to accurately reflect the underlying capabilities of these complex models, necessitating the development of novel assessment strategies that account for these intricacies.

STAR: A Framework for Statistical and Reasoning-Based Assessment
Constrained Probabilistic Matrix Factorization (CPMF) serves as the foundational statistical method within the STAR framework for representing Large Language Model (LLM) capabilities in a reduced dimensional space. CPMF decomposes a matrix representing LLM performance across a range of tasks into lower-rank matrices, effectively capturing the latent factors that contribute to these capabilities. This dimensionality reduction facilitates efficient computation and analysis, while the probabilistic nature of the factorization allows for uncertainty quantification. The “constrained” aspect of CPMF incorporates prior knowledge and dependencies, improving the stability and interpretability of the resulting low-dimensional representation. [latex]X \approx UV^T[/latex], where X is the original LLM capability matrix, and U and V are the lower-rank factor matrices.
Constrained Probabilistic Matrix Factorization (CPMF) builds upon established dimensionality reduction and collaborative filtering techniques to facilitate robust capability extraction. Specifically, CPMF integrates aspects of Principal Component Analysis (PCA) for initial feature reduction and variance maximization, Probabilistic Matrix Factorization (PMF) to model underlying latent factors in LLM capabilities, and Neural Collaborative Filtering (NCF) to capture non-linear relationships between capabilities and observed performance. By combining these methods, CPMF addresses limitations inherent in individual techniques, providing a more comprehensive and stable representation of LLM functionality while accounting for data sparsity and potential noise.
Expectation Violation Theory (EVT) is integrated into the STAR framework to dynamically adjust statistical expectations based on the assessed credibility of incoming evidence. EVT operates by quantifying the discrepancy between predicted outcomes – derived from the CPMF-based capability representation – and observed evidence. Evidence deemed highly credible, as determined by the agentic reasoning module, results in a greater refinement of the initial statistical expectations. Conversely, low-credibility evidence leads to minimal adjustment, preventing unreliable data from unduly influencing the framework’s understanding of LLM capabilities. This process enables STAR to adapt to nuanced performance variations and mitigate the impact of potentially misleading or erroneous information, thereby enhancing the accuracy of capability assessment.
Agentic reasoning within the STAR framework utilizes the GPT-5.1 Large Language Model in conjunction with semantic feature extraction performed by the BGE-M3 embedding model to evaluate the credibility of evidence retrieved through Retrieval Augmentation. This process involves GPT-5.1 analyzing the semantic features of each retrieved document, as quantified by BGE-M3, to determine its relevance and trustworthiness in relation to the query and existing knowledge. The LLM assesses factors such as source reliability, internal consistency, and factual support to assign a credibility score to the evidence, which is then used to weight the evidence’s contribution to the overall reasoning process. This evaluation is performed autonomously by the agent, allowing STAR to dynamically adjust its reliance on different sources of information based on their assessed credibility.
![STAR demonstrates prediction failures on complex benchmarks like CCBench and MMBench, exhibiting errors of [latex]15.58[/latex] and [latex]9.87[/latex] respectively, despite correctly identifying relevant factors but miscalculating their quantitative impact.](https://arxiv.org/html/2602.12143v1/bad_case.png)
Validating Statistical Foundations and Reasoning Integration in STAR
The STAR framework’s Core Parameter Modeling Function (CPMF) employs Markov Chain Monte Carlo (MCMC) sampling, specifically utilizing the No-U-Turn Sampler (NUTS) algorithm, to achieve robust and accurate parameter estimation. NUTS, an adaptive MCMC method, dynamically adjusts step sizes and target parameters during the sampling process, mitigating issues commonly found in traditional MCMC methods, such as slow mixing and suboptimal acceptance rates. This adaptive approach enables CPMF to efficiently explore the parameter space and converge on statistically sound estimates, even with complex model structures and limited data. The implementation of NUTS within CPMF is critical for quantifying uncertainty and ensuring the reliability of LLM capability predictions.
Retrieval Augmentation within STAR leverages external knowledge sources, specifically HuggingFace and arXiv, to expand the context available during Large Language Model (LLM) assessment. This process involves querying these repositories for relevant data pertaining to the task or question being evaluated. The retrieved information is then incorporated into the LLM’s input, providing it with a more comprehensive evidence base beyond its pre-training data. This expanded context enables STAR to assess LLM performance with greater accuracy and robustness, particularly when evaluating capabilities related to specialized or rapidly evolving topics covered in these external knowledge sources.
LLM Reasoning within the STAR framework incorporates a process for assessing the quality of information retrieved during Retrieval Augmentation. This evaluation focuses on determining the relevance of retrieved documents to the original query and, critically, assessing the trustworthiness of the source material. This mechanism is designed to mitigate potential biases present in the external knowledge sources-HuggingFace and arXiv-by identifying and down-weighting information that is unsupported, contradictory, or originates from unreliable sources. The system analyzes the retrieved content to determine if it logically supports the assessment being made, effectively filtering out irrelevant or misleading information that could skew the evaluation of LLM capabilities.
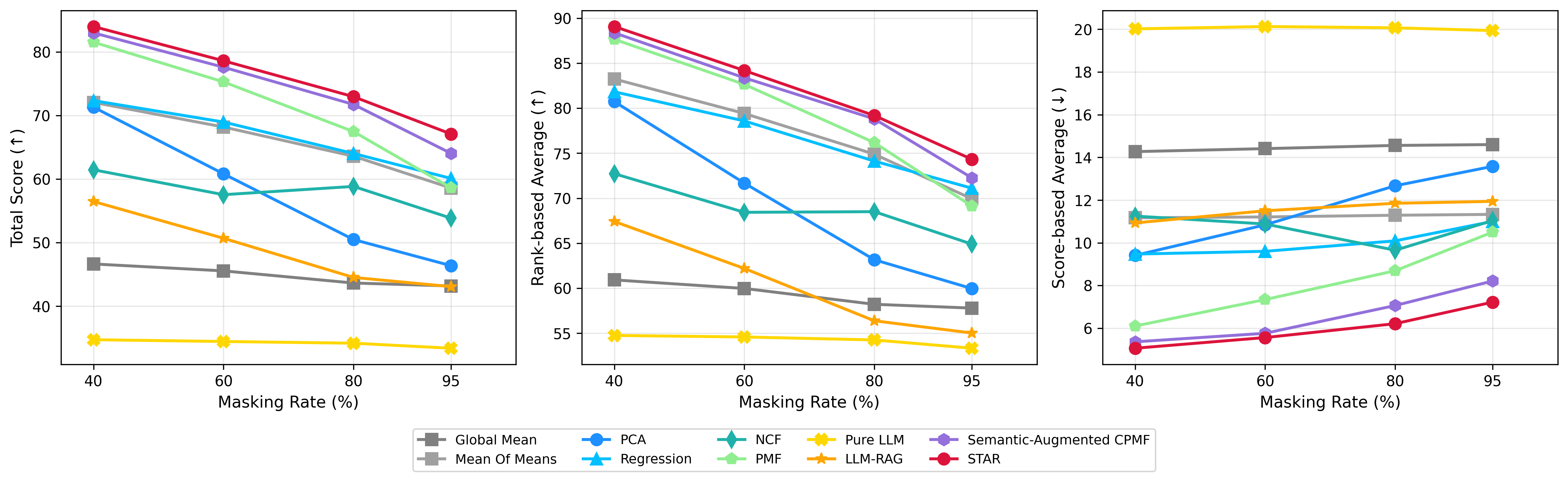
STAR demonstrates significant performance gains in LLM capability prediction, achieving a 14.46% total score improvement when evaluated with 95% of the input data masked. Furthermore, STAR exhibits a 43.66% total improvement in predicting LLM performance under benchmark-side shifts – conditions where the evaluation benchmarks differ from those used during training. These results indicate STAR’s robustness and ability to accurately assess LLM capabilities even with substantial data occlusion or distributional changes in the evaluation environment.

Beyond Prediction: Charting a Course for More Intelligent Systems
Current large language model (LLM) evaluation often hinges on benchmark scores, which can be susceptible to gaming and fail to capture true capabilities. The STAR framework offers a statistically rigorous alternative, moving beyond simple performance metrics to assess LLMs through the lens of evidence retrieval. By pinpointing why a model succeeds or fails on a given task – identifying the specific supporting facts it utilizes – STAR provides a more trustworthy and nuanced evaluation. This approach doesn’t merely rank models; it diagnoses their strengths and weaknesses, offering a robust defense against misleading results and paving the way for more reliable comparisons across different architectures and training paradigms.
The Statistical Test for Reasoning (STAR) framework doesn’t simply assess if a large language model (LLM) succeeds or fails, but elucidates why. By dissecting the reasoning processes behind each answer, STAR pinpoints specific cognitive bottlenecks and areas where an LLM struggles – be it with logical deduction, common sense reasoning, or factual recall. This granular diagnostic capability provides developers with actionable insights, moving beyond broad performance metrics to targeted model refinement. Understanding these underlying weaknesses allows for focused training strategies, potentially improving performance on specific reasoning tasks without requiring extensive and costly retraining of the entire model. Consequently, STAR facilitates a more efficient and informed approach to LLM development, fostering innovation and ultimately leading to more robust and reliable artificial intelligence systems.
The STAR framework moves beyond simply assessing what large language models (LLMs) can achieve, instead focusing on how they arrive at those results, thereby separating inherent capability from the influence of model size. This decoupling is crucial because increased scale doesn’t automatically equate to improved reasoning or problem-solving; a larger model may excel due to memorization rather than genuine understanding. By pinpointing the specific reasoning steps LLMs utilize-or fail to utilize-STAR reveals whether a model’s performance stems from robust cognitive abilities or superficial patterns. Consequently, researchers gain a more granular view of an LLM’s strengths and weaknesses, enabling targeted improvements and the development of models that are not just bigger, but demonstrably better at reasoning and generalization.
The STAR framework distinguishes itself through a compelling balance of accuracy and efficiency in large language model evaluation. Achieving a Top-10 Recall of 0.82 signifies that, when identifying the ten best-performing models from a larger pool, STAR successfully retrieves eight out of ten correct choices. Critically, this high level of performance is attained with a remarkably low evaluation cost of only 3.5%, meaning that only a small fraction of the full dataset needs to be processed to achieve reliable results. This efficiency represents a substantial advantage over traditional, more computationally expensive methods, allowing for quicker and more practical assessments of LLM capabilities and facilitating the identification of truly high-performing models without prohibitive resource demands.
The pursuit of predictable large language model performance, as detailed in this work with STAR, echoes a fundamental principle of elegant engineering. The framework’s combination of statistical rigor and agent-based simulation isn’t merely about achieving accuracy; it’s about distilling complexity into understandable components. This resonates with Linus Torvalds’ assertion that, “Most good programmers do programming as a hobby, and many of those will eventually find that they have a knack for it.” STAR, by attempting to model and explain LLM behavior, isn’t just building a predictor-it’s enabling a deeper, more intuitive understanding of these powerful, yet often opaque, systems. The goal isn’t simply to know that a model will perform well, but why, mirroring the pursuit of self-evident code.
Where Do We Go From Here?
The ambition to predict the performance of large language models-a pursuit bordering on divination-has inevitably led to frameworks of increasing intricacy. STAR, by attempting to synthesize statistical rigor with the illusion of agency, at least acknowledges the fundamental difficulty. The field often seems to mistake correlation for comprehension; a model predicting another model is, after all, simply a more elaborate echo. The true test lies not in how accurately one predicts, but in what such prediction ultimately reveals.
Current evaluations, even with systems like STAR, remain largely benchmark-centric. Performance on contrived tasks, however cleverly designed, offers limited insight into genuine linguistic competence. A future direction demands metrics that probe for robustness, adaptability, and-perhaps most importantly-the absence of brittle specialization. The pursuit of “general” intelligence should not be measured by success on a leaderboard, but by failure in unexpected contexts.
One suspects the proliferation of predictive frameworks is, in part, a response to a deeper anxiety: that these models are, fundamentally, black boxes. Explainability, therefore, becomes less about understanding how a model arrives at an answer, and more about constructing a narrative that justifies the result. A simpler metric-the cost of being surprised-might prove more illuminating than any framework, no matter how elegantly constructed.
Original article: https://arxiv.org/pdf/2602.12143.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
2026-02-14 04:50