Author: Denis Avetisyan
A new approach, ToolOrchestra, efficiently coordinates diverse AI models and tools to achieve peak performance with reduced costs and improved alignment with user needs.

This paper presents ToolOrchestra, a method for training small language models to effectively orchestrate tools and specialized models, achieving state-of-the-art results in cost efficiency, preference alignment, and data synthesis.
Despite the impressive general capabilities of large language models, solving complex, real-world problems remains computationally expensive and often lacks efficient resource allocation. This work introduces ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration, a novel method for training small orchestrator models to coordinate diverse tools and specialized agents. We demonstrate that this approach achieves state-of-the-art performance on challenging benchmarks, surpassing even larger models like GPT-5 with significantly improved cost efficiency and user preference alignment. Could lightweight orchestration unlock a new era of practical, scalable, and truly intelligent agentic systems?
Beyond Simple Prediction: Orchestrating Intelligence
Despite the remarkable abilities of large language models in areas like text generation and translation, truly complex problem-solving frequently demands more than simple pattern recognition. These models often falter when a task requires integrating information from disparate sources – a database search, a specialized API, or even a simple calculation – and coordinating multiple tools to achieve a unified goal. While proficient at individual steps, they lack the inherent capacity to orchestrate these steps into a coherent workflow. This limitation isn’t a matter of scale, but of architecture; current models excel at predicting the next token, not at strategic planning and resource allocation. Consequently, a significant gap remains between performing isolated tasks and achieving holistic solutions, highlighting the need for systems that can intelligently combine the strengths of various tools and knowledge bases.
Existing methods for utilizing multiple AI tools in sequence often falter due to inefficiencies in how computational resources are assigned and managed. These systems frequently treat each tool as an isolated component, leading to redundant processing and a lack of contextual understanding as information passes between them. Consequently, maintaining task coherence – ensuring each step logically follows from the last and contributes to the overall goal – proves exceedingly difficult. The result is a brittle workflow prone to errors and unable to adapt to unexpected data or changing requirements, hindering performance on genuinely complex problems that demand seamless integration and intelligent prioritization of diverse capabilities.
The limitations of large language models in tackling genuinely complex challenges necessitate a shift towards intelligent orchestration. Rather than simply scaling model size, future systems require an agentic framework capable of dynamically selecting, coordinating, and integrating diverse tools and knowledge sources. This agent doesn’t merely generate responses; it actively plans and executes a sequence of actions – leveraging search engines, specialized APIs, or even other AI models – to achieve a defined objective. Such an approach moves beyond pattern recognition to enable true problem-solving, where the agent intelligently manages resources, maintains task coherence, and adapts its strategy based on the results of each step, ultimately unlocking capabilities far exceeding those of standalone language models.

Deconstructing Complexity: Introducing ToolOrchestra
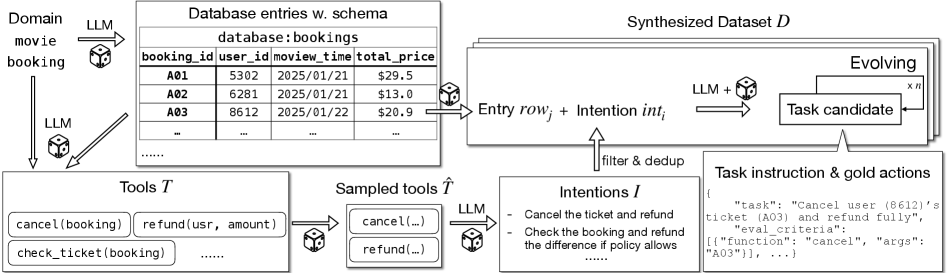
ToolOrchestra introduces a methodology for training a dedicated language model, termed the Orchestrator, to manage the execution of multiple tools and models in a coordinated manner. This approach addresses complex tasks by decomposing them into sub-problems solvable by specialized tools, with the Orchestrator responsible for selecting and sequencing these tools. The Orchestrator is not designed to perform the tasks directly, but rather to act as a central controller, directing the flow of information and computation between available resources. This division of labor allows for the integration of diverse functionalities, ranging from external APIs and specialized models to internal logic, all under the guidance of a single, trainable language model.
The Orchestrator employs reinforcement learning (RL) to determine the most effective sequence of tool and model utilizations for a given task. This is achieved through a reward signal that quantifies the success of each action taken by the Orchestrator. Specifically, the agent learns a policy mapping states – representing the task’s current condition – to actions, which involve selecting a specific tool or model and providing it with appropriate inputs. The RL process iteratively refines this policy by maximizing cumulative rewards, enabling the Orchestrator to discover strategies that optimize task completion. The state space incorporates information about the task, previous actions, and the outputs of utilized tools, while the action space comprises the available tools and their configurable parameters.
ToolOrchestra demonstrates a substantial reduction in computational expense by achieving state-of-the-art performance utilizing an 8 billion parameter language model. Comparative evaluations indicate that this approach surpasses the performance of larger models, specifically those with significantly higher parameter counts, while maintaining comparable or improved task completion rates. This efficiency is a direct result of the Orchestrator’s ability to strategically select and coordinate specialized tools, minimizing the need for a single, monolithic model to possess all necessary capabilities. The method achieves this performance gain without requiring increases in training data volume, focusing instead on optimizing the interaction between a smaller model and external resources.

Sculpting Behavior: Optimizing Orchestration with Targeted Rewards
The training process for the Orchestrator utilizes a multi-component reward system designed to optimize performance across several key metrics. The Outcome Reward incentivizes correct task completion, providing positive reinforcement when the Orchestrator successfully achieves the desired result. Simultaneously, the Efficiency Reward encourages minimization of resource utilization – specifically, computational cost and execution time – promoting solutions that are not only accurate but also economically viable. Finally, the Preference Reward component aligns the Orchestrator’s behavior with anticipated user expectations, guiding it to select tools and approaches that prioritize user-defined criteria and enhance overall usability.
The Orchestrator’s behavioral patterns are directly influenced by the combined effect of its reward system. Outcome Rewards incentivize accurate task completion, while Efficiency Rewards promote resource optimization during execution. Critically, the Preference Reward component steers the Orchestrator toward solutions aligned with anticipated user needs, effectively guiding tool selection and usage. This interplay ensures the Orchestrator doesn’t simply complete tasks, but does so in a manner that is both performant and user-centric, leading to improved overall system behavior as demonstrated by benchmark scores of 37.1 on HLE and 76.3 on FRAMES.
Evaluations demonstrate the Orchestrator’s performance surpasses existing baseline models on established benchmarks. Specifically, the Orchestrator achieved a score of 37.1 on the Human-Level Learning Environment (HLE) benchmark, exceeding the performance of all comparison models. Furthermore, on the FRAMES benchmark, the Orchestrator attained a score of 76.3, also outperforming all baselines used for evaluation. These results indicate the efficacy of the orchestration approach in achieving high performance on complex tasks.

Fueling the Agent: Scaling Orchestration with ToolScale
ToolScale is a dataset created to specifically support the development and training of agents capable of utilizing tools, such as the Orchestrator. It functions as a dedicated resource for improving the performance of these agents in tool-use tasks. The dataset is designed to provide a substantial volume of training examples relevant to interacting with and controlling external tools, allowing agents to learn effective strategies for leveraging these tools to achieve specific goals. This targeted approach differentiates ToolScale from general-purpose datasets and optimizes it for training tool-use capabilities.
ToolScale is constructed via a data synthesis process that expands upon existing datasets to improve the breadth and variability of training examples. This technique involves programmatically generating new data points based on established patterns and constraints, effectively increasing the dataset’s size without relying solely on manual annotation. Specifically, data synthesis in ToolScale focuses on creating diverse scenarios and edge cases for tool usage, addressing limitations in naturally occurring datasets which may lack comprehensive coverage of all possible tool interactions and environmental conditions. This augmentation is crucial for training robust and generalizable tool-use agents, enabling them to perform reliably across a wider range of tasks and situations.
The Orchestrator, a tool-use agent utilizing the Qwen3-8B language model, demonstrates improved performance when trained with the ToolScale dataset. Specifically, evaluation on the τ2-Bench benchmark indicates a 2.5% increase in performance attributable to the scale and diversity of ToolScale. This improvement suggests that a larger, more comprehensive training dataset positively impacts the agent’s ability to effectively utilize tools and achieve higher scores on standardized benchmarks designed to assess tool-use capabilities.
Beyond Benchmarks: Validating Orchestration and Charting Future Potential
Rigorous testing of the Orchestrator across demanding benchmarks – including the multifaceted Humanity’s Last Exam, the visual reasoning challenge of FRAMES, and the complex problem-solving scenarios within Tau2Bench – reveals a robust capacity for tackling intricate tasks. These evaluations weren’t simply about achieving correct answers; they probed the system’s ability to synthesize information, apply logic, and demonstrate genuine reasoning skills. Performance on these benchmarks highlights the Orchestrator’s potential to move beyond pattern recognition and engage in more sophisticated cognitive processes, offering a promising step towards artificial general intelligence and reliable automation of complex decision-making.
The Orchestrator’s architecture is designed for modular improvement, and integration with more advanced language models like GPT-5 represents a significant step toward achieving state-of-the-art performance. This synergistic approach allows the system to capitalize on the enhanced reasoning and knowledge capabilities of GPT-5, effectively augmenting its own problem-solving skills. Preliminary evaluations indicate that leveraging such tools not only boosts accuracy across complex benchmarks, but also unlocks the potential to tackle previously intractable challenges in areas like logical inference and creative text generation. The adaptability of the Orchestrator suggests a pathway toward continuously improved performance as even more powerful language models become available, solidifying its position as a flexible and high-performing AI system.
The Orchestrator’s design philosophy prioritizes not simply achieving high accuracy, but doing so with remarkable efficiency and in alignment with user needs. Evaluations reveal that this approach yields substantial cost savings compared to deploying significantly larger, monolithic models; the Orchestrator intelligently delegates tasks, minimizing overall computational demands without sacrificing performance. This efficiency is coupled with a focus on user preference, as the system’s modularity allows for tailoring responses and prioritizing outputs based on individual user feedback and requirements. The result is a system that delivers both powerful problem-solving capabilities and a demonstrably more sustainable and user-centric approach to artificial intelligence.

The pursuit of efficient orchestration, as demonstrated by ToolOrchestra, mirrors a fundamental principle of systems understanding: probing boundaries to reveal underlying structure. One considers the intentionality behind constraints, and how exceeding them unveils novel capabilities. Tim Berners-Lee aptly stated, “The Web is more a social creation than a technical one.” This resonates with ToolOrchestra’s core idea of aligning large language models not just with task completion, but with user preference – a distinctly social consideration. The system doesn’t simply optimize for performance; it learns to navigate a landscape of human values, effectively reverse-engineering the expectations embedded within interaction. This approach moves beyond mere automation toward a more nuanced form of intelligence.
Beyond the Symphony
ToolOrchestra demonstrates a capacity for coordinated intelligence, yet every exploit starts with a question, not with intent. The current framework, while efficient in leveraging existing tools, fundamentally relies on their pre-defined functionality. The true limitation isn’t the orchestration itself, but the rigidity of the instruments. Future work must address the capacity for dynamic tool creation – for the agent to not merely wield hammers, but to design and forge new ones mid-task. This shifts the problem from coordination to genuine innovation.
Preference alignment, too, reveals a subtle challenge. Current methods assess alignment against explicitly stated desires. However, human intention is rarely so clear. The agent excels at fulfilling requests, but struggles with understanding the unarticulated needs driving them. This suggests a need to move beyond reward functions and towards models of human cognitive biases, even irrationality – to predict what a user will want, not just what they say they do.
Ultimately, ToolOrchestra isn’t about building a better assistant; it’s about reverse-engineering the principles of intelligence itself. The cost efficiency gains are merely a symptom. The real metric of success won’t be performance on benchmarks, but the ability to predictably – and safely – introduce novelty into complex systems. The system’s potential lies not in what it can do, but in what it can discover.
Original article: https://arxiv.org/pdf/2511.21689.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- World Eternal Online promo codes and how to use them (September 2025)
- Clash Royale Season 79 “Fire and Ice” January 2026 Update and Balance Changes
- How to find the Roaming Oak Tree in Heartopia
- Clash Royale Furnace Evolution best decks guide
- Best Arena 9 Decks in Clast Royale
- FC Mobile 26: EA opens voting for its official Team of the Year (TOTY)
- Best Hero Card Decks in Clash Royale
2025-11-30 10:43