Author: Denis Avetisyan
Researchers have developed a new framework enabling a single AI agent to control diverse humanoid robots, significantly simplifying the challenge of robotic locomotion.
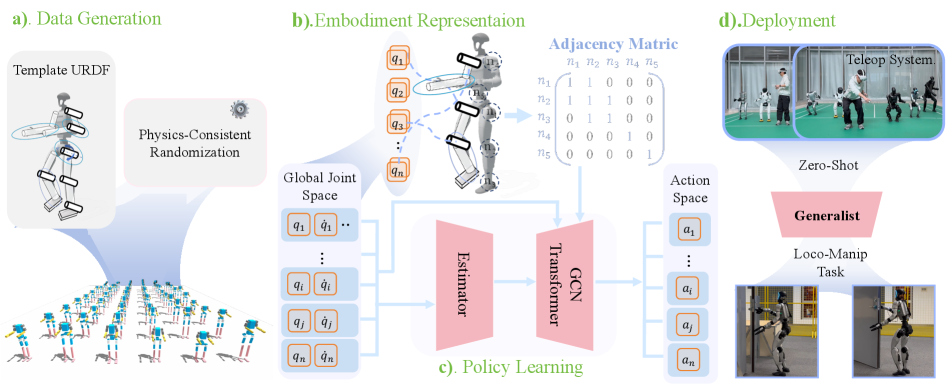
A physics-consistent approach leveraging morphological randomization and graph neural networks achieves zero-shot whole-body control across varied humanoid platforms.
Achieving robust and adaptable whole-body control remains a significant challenge for humanoid robots, often requiring extensive robot-specific training. This limitation is addressed in ‘Scalable and General Whole-Body Control for Cross-Humanoid Locomotion’, which introduces XHugWBC, a novel framework demonstrating that a single reinforcement learning policy can generalize across a wide range of humanoid designs. By leveraging physics-consistent morphological randomization and a semantically aligned state representation, XHugWBC enables zero-shot transfer to previously unseen robots, effectively internalizing a broad distribution of morphological and dynamical characteristics. Could this approach pave the way for truly versatile humanoid robots capable of operating effectively in diverse and unpredictable environments?
The Inevitable Drift: Confronting Morphological Diversity
Conventional control strategies often falter when applied across the spectrum of humanoid robot designs. Each new morphology – variations in limb length, body mass distribution, or joint configurations – necessitates a substantial and time-consuming re-tuning process. This reliance on manual adjustment stems from the fact that these methods typically rely on precisely modeled dynamics, which quickly become inaccurate with even minor changes to the robot’s physical structure. The laborious process of recalibrating controllers for each unique robot significantly hinders the scalability of humanoid robotics, creating a bottleneck in both research and deployment. Consequently, a pressing need exists for control approaches that can gracefully accommodate morphological diversity, offering a path toward more adaptable and broadly applicable humanoid systems.
The pursuit of truly versatile humanoid robots hinges on mastering whole-body control – the ability to coordinate movements of all joints to accomplish complex tasks. However, current methodologies often falter when transferred to robots with even slight variations in design, such as differences in limb length or joint placement. This lack of adaptability represents a significant bottleneck in robotics research, as it necessitates extensive and time-consuming re-tuning for each new robot morphology. The challenge isn’t simply about achieving stable locomotion or manipulation on one robot, but about creating control systems that can generalize across a diverse population of humanoids, paving the way for robots that can operate effectively in unpredictable, real-world environments. Consequently, a substantial effort is focused on developing control architectures that are inherently robust to morphological differences, leveraging techniques like machine learning and model predictive control to overcome this fundamental obstacle.
Humanoid robots present a unique control challenge due to the intricate interplay of forces and motions inherent in their design. Unlike simpler robotic systems, the high degree of freedom and complex, non-linear dynamics of bipedal locomotion and manipulation necessitate control strategies that move beyond pre-programmed sequences. Traditional control methods, reliant on precise modeling, falter when confronted with even slight variations in robot morphology or environmental conditions. Consequently, researchers are increasingly focused on learning paradigms – such as reinforcement learning and imitation learning – that enable robots to acquire control policies through experience and adapt to unforeseen circumstances. These approaches aim to build controllers that generalize, meaning they can effectively operate across diverse robot bodies and dynamic scenarios, ultimately unlocking the potential for truly versatile and robust humanoid robots.

XHugWBC: A Framework for Embracing Change
XHugWBC addresses the challenge of deploying robotic control policies to novel humanoid robots by eliminating the need for per-robot fine-tuning. Traditional methods require retraining or adaptation when transferring a controller to a robot with different physical characteristics. This framework instead learns a single control policy capable of generalizing across a wide range of morphologies without further training on the target robot. This is achieved through a combination of simulated morphological variation during training and a unified representation of robot states, allowing the policy to adapt to new robot bodies at test time without gradient updates or additional learning phases. The result is a significant reduction in the time and resources required to deploy robotic skills to previously unseen hardware.
Physics-Consistent Morphological Randomization within XHugWBC involves systematically varying physical parameters of simulated robots during training. These parameters include link lengths, joint friction, center of mass position, and actuator properties. Crucially, randomization is not applied arbitrarily; instead, it’s constrained to maintain physically plausible robot configurations, ensuring the simulated morphologies remain stable and capable of locomotion. This process generates a diverse training distribution that exposes the learning algorithm to a wide range of robot shapes and dynamics, improving the controller’s generalization capability to unseen robots without requiring retraining on each new morphology. The randomization range for each parameter is determined based on physically realistic limits to prevent simulations from diverging or becoming unrealizable.
The Universal Embodiment Representation within XHugWBC is a learned mapping that transforms robot-specific state information – encompassing joint angles, velocities, and sensor readings – into a fixed-dimensional vector space. This representation is designed to be invariant to morphological differences between robots; meaning robots with varying link lengths, masses, or actuator configurations will produce similar vectors when performing the same action. The use of a shared, unified space allows a controller trained on one robot morphology to directly interpret and act upon the state representation of a novel, unseen robot, facilitating zero-shot skill transfer without requiring retraining or adaptation on the new platform. This is achieved through a neural network architecture trained to reconstruct robot-specific parameters from the unified representation, ensuring information preservation during the mapping process.
XHugWBC employs Reinforcement Learning (RL) to train a control policy capable of generalizing across a range of simulated robot morphologies. The RL agent receives feedback in the form of rewards based on task completion and utilizes this signal to iteratively refine the controller’s parameters. Training is performed on the distribution of randomized robots generated through Physics-Consistent Morphological Randomization, effectively exposing the agent to a diverse set of dynamics and physical characteristics. This process optimizes the controller to be robust to variations in body shape, size, and actuator properties, enabling zero-shot transfer to unseen robots without requiring further training or adaptation on the target hardware. The learned policy thus represents a generalized solution applicable to the entire randomized population and, crucially, extends to novel morphologies within that distribution.
Encoding the Form: Graph Networks and the Transformer’s Gaze
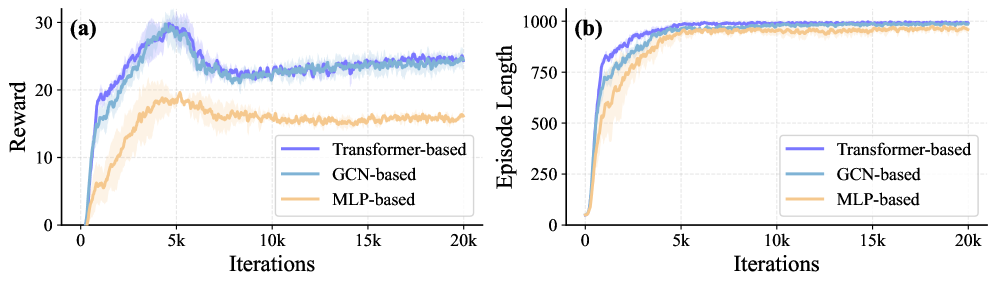
XHugWBC utilizes either Graph Convolutional Networks (GCNs) or Transformer architectures to represent the robot’s kinematic chain as a structured input for downstream tasks. GCNs operate directly on graph-structured data, applying convolutional filters to node features while considering the graph’s connectivity. Conversely, the Transformer architecture, originally developed for natural language processing, processes the kinematic chain through self-attention mechanisms, allowing it to weigh the importance of different joints and links. Both approaches transform the robot’s physical structure into a format suitable for neural network processing, enabling the system to learn and reason about the robot’s embodiment. The selection of either GCN or Transformer is a design choice impacting computational cost and representational capacity.
The adjacency matrix serves as a foundational element in representing a robot’s kinematic structure within both the Graph Convolutional Network (GCN) and Transformer architectures. This matrix, a [latex]|V| \times |V|[/latex] array where [latex]|V|[/latex] denotes the number of joints or links in the robot, defines the connections between these components. A non-zero entry at position [latex](i, j)[/latex] indicates a direct physical connection between joint/link i and joint/link j, while a zero indicates no direct connection. This representation allows the architectures to understand the robot’s topology, enabling them to process information based on the physical relationships between its parts and ultimately contributing to the construction of the Universal Embodiment Representation.
The selection of either Graph Convolutional Networks (GCNs) or Transformer architectures for encoding robot kinematics directly influences the resulting Universal Embodiment Representation’s performance characteristics. GCNs typically offer computational efficiency due to their localized receptive fields, processing information based on immediate neighbors defined by the adjacency matrix. Conversely, Transformers, while more computationally intensive, can capture long-range dependencies within the kinematic chain, potentially leading to a more comprehensive representation. This trade-off manifests in differing requirements for training data and computational resources; GCNs may converge faster with limited data, whereas Transformers benefit from larger datasets to fully realize their representational capacity. The optimal choice is therefore dependent on the specific robotic system and the available computational budget.
State estimation is incorporated into the reinforcement learning (RL) pipeline to enhance control performance by reconstructing privileged state information not directly observable through standard sensory inputs. This process involves training the agent to predict internal states – such as joint angles, velocities, or forces – that are known during training but unavailable during deployment. By explicitly modeling and reconstructing these hidden states, the agent gains a more complete understanding of the system’s dynamics, leading to improved policy learning and robustness. The reconstructed state information is then used as an augmented observation, effectively providing the agent with access to information that would otherwise be inaccessible, and enabling more accurate and efficient control strategies.
A Resilience Forged in Adaptation: Zero-Shot Performance Realized
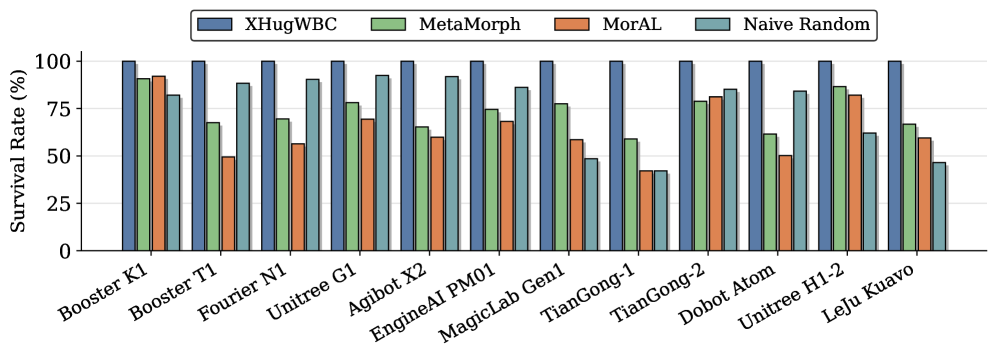
Recent experiments reveal that XHugWBC exhibits remarkable adaptability, successfully controlling a diverse array of humanoid robots without any task-specific training for each new platform – a capability known as zero-shot generalization. This controller doesn’t require pre-existing knowledge of a robot’s unique physical properties or dynamics; instead, it leverages a learned control policy that transfers effectively to previously unseen robotic systems. This represents a significant advancement, as traditional control methods often demand extensive re-tuning and robot-specific parameter adjustments. The demonstrated proficiency across seven real-world robots highlights the potential for a universal control framework, reducing the development time and resources needed to deploy complex humanoid robots in various environments and applications.
The newly developed controller demonstrates a remarkable ability to maintain stability even in difficult situations, a quality quantified through a metric called ‘Survival Rate’. This rate assesses the controller’s capacity to prevent the robot from falling during operation, and experimental results reveal consistently high performance across a variety of challenging scenarios. Unlike controllers that might falter when faced with unexpected disturbances or uneven terrain, this system effectively adapts and compensates, ensuring continued operation and preventing potentially damaging falls. The high Survival Rate suggests a robust design capable of handling the inherent unpredictability of real-world robotic applications, paving the way for more reliable and adaptable humanoid robots.
A key strength of the developed controller lies in its precision of movement, as evidenced by minimized command tracking error. This metric quantifies the difference between the robot’s intended actions – the commands it receives – and its actual performance, revealing how faithfully the controller translates instructions into physical behavior. Low command tracking error indicates the robot consistently and accurately executes desired movements, crucial for complex tasks demanding fine motor control and reliable operation. This ability isn’t merely about achieving the goal of a task, but executing it as intended, paving the way for predictable and safe interactions with dynamic environments and potentially enabling the robot to learn and adapt more effectively from its experiences.
The XHugWBC controller exhibits a remarkable capacity for adaptation and control, achieving a 100% survival rate across seven distinct real-world humanoid robots without any task-specific training – a feat demonstrating potent zero-shot generalization. Initial performance in simulation closely rivals that of specialized controllers, reaching approximately 85% of their efficacy. Notably, the system doesn’t simply match expert performance with fine-tuning; it surpasses it, achieving a 10% improvement after adaptation – suggesting that XHugWBC can not only rapidly deploy to new robots but also refine its abilities to exceed the capabilities of controllers designed specifically for a single platform. This indicates a significant step toward broadly applicable, robust robot control systems.
“`html
The pursuit of adaptable systems, as demonstrated by XHugWBC, echoes a fundamental tenet of resilient engineering. This framework’s capacity to transfer a single policy across varied humanoid morphologies isn’t merely about achieving zero-shot control; it’s about anticipating the inevitable decay of specific implementations. As Grace Hopper famously stated, “It’s easier to ask forgiveness than it is to get permission.” This sentiment translates directly to the robotic realm; rigid adherence to a single design limits adaptability. XHugWBC, through physics-consistent randomization, embodies a proactive approach, effectively ‘asking forgiveness’ for morphological variations by building a system capable of graceful degradation and continued function despite change. This prioritizes robustness over brittle perfection, acknowledging that the true measure of a system isn’t its initial state, but its capacity to endure.
What’s Ahead?
The presented framework, while demonstrating a capacity for morphological adaptation, merely postpones the inevitable decay inherent in any control system. Uptime, even across randomized embodiments, is a temporary reprieve. The success of cross-embodiment learning hinges on a unified state representation, but the very act of representation introduces abstraction-a simplification of the unfolding reality. Latency, the tax every request must pay, will always accrue as complexity increases, and the question shifts from ‘can it control?’ to ‘at what cost, and for how long?’.
Future iterations will likely grapple with the limitations of physics-consistent randomization. While valuable, this approach remains within the bounds of pre-defined parameters. True generalization demands a system capable of extrapolating beyond its training distribution-a capacity for novelty that current reinforcement learning paradigms struggle to achieve. The illusion of stability is cached by time; the challenge lies in extending that cache indefinitely.
Ultimately, the pursuit of a universally adaptable controller is a Sisyphean task. The body, any body, is a transient configuration of matter, subject to entropy. The focus, therefore, should not be on eliminating change, but on embracing it-on designing systems that degrade gracefully, and learn from their own inevitable failures.
Original article: https://arxiv.org/pdf/2602.05791.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- GearPaw Defenders redeem codes and how to use them (April 2026)
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- All Mobile Games (Android and iOS) releasing in April 2026
- eFootball 2026 “Countdown to 1 Billion Downloads” Campaign arrives with new Epics and player packs
- Limbus Company 2026 Roadmap Revealed
2026-02-07 06:49