Author: Denis Avetisyan
A new approach eliminates the need for complex, multi-step processes in automatically creating introductions for scientific papers.
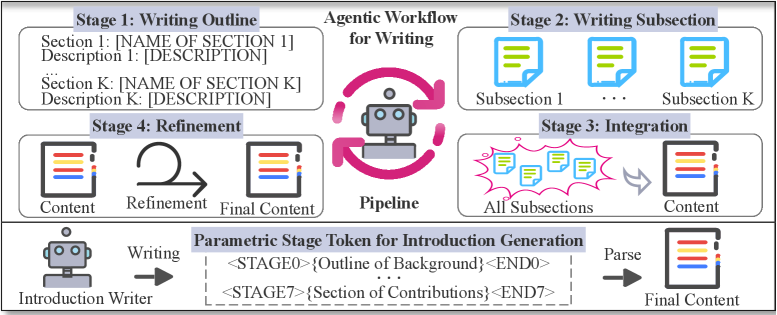
This work introduces STIG, a method using parametric stage tokens to integrate workflow stages directly into a single language model for improved efficiency and quality in scientific writing.
While large language models show promise in automating scientific writing tasks, current approaches often rely on complex, multi-step agentic workflows prone to errors and incoherence. This paper, ‘Eliminating Agentic Workflow for Introduction Generation with Parametric Stage Tokens’, introduces a novel method, Stage Tokens for Introduction Generation (STIG), that streamlines the process by directly embedding logical structure into a single LLM. By parameterizing workflow stages as explicit tokens, STIG enables the generation of complete, coherent introductions in a single inference, outperforming traditional agentic systems on both semantic similarity and structural rationality. Could this parametric approach unlock more efficient and effective automation of complex scientific writing beyond introductions?
The Inevitable Challenge of Coherent Composition
Despite remarkable progress in large language models, the generation of truly coherent, multi-stage documents presents a significant hurdle. While these models excel at producing locally consistent text, maintaining a unified and logical flow across extended compositions proves challenging. The difficulty isn’t simply one of length; it’s about preserving the initial intent and overarching structure as the document evolves through numerous interconnected sections. Current models often struggle with long-range dependencies, leading to thematic drift, repetitive arguments, or abrupt transitions that disrupt the reader’s experience. Effectively constructing a cohesive narrative that spans multiple stages requires more than just predicting the next word; it demands a robust understanding of the document’s global architecture and the ability to consistently reinforce its core message throughout.
Conventional methods for generating lengthy texts often falter when attempting to sustain a consistent and logical progression of ideas. These approaches frequently treat each sentence or paragraph as an isolated unit, rather than an integral component of a larger, cohesive argument. Consequently, extended documents may exhibit disjointed reasoning, abrupt topic shifts, or repetitive phrasing, undermining the overall structural integrity. The challenge lies in the difficulty of encoding and maintaining long-range dependencies – the subtle connections between distant parts of the text that are crucial for establishing a clear and compelling narrative. This limitation is particularly pronounced when dealing with complex topics requiring nuanced explanations and careful sequencing of information, ultimately hindering the effective communication of sophisticated ideas.
The challenge in generating lengthy, cohesive writing doesn’t simply reside in vocabulary or grammar, but in the fundamental difficulty of modeling sequential thought. Current language models often excel at predicting the next word, but struggle to maintain a consistent, high-level plan across many steps. Effectively, crafting a complex document requires not just linguistic ability, but the capacity to decompose a large task into a series of logically connected sub-tasks, track dependencies between them, and ensure each stage builds coherently upon the last. This necessitates a form of ‘planning’ or ‘reasoning’ that goes beyond simple pattern recognition, demanding the system understand why certain information should be presented at a particular point to achieve an overall communicative goal – a task proving remarkably difficult to replicate computationally.

A Singular Pass Towards Structured Generation
The Stage Token for Introduction Generation (STIG) model utilizes parametric stage tokens as a mechanism for representing the discrete phases inherent in a writing process. These tokens are not simply textual prompts, but rather, adjustable parameters that guide the Large Language Model (LLM) through a predefined sequence of writing stages – such as outlining, drafting, and revising. Each stage token encapsulates specific instructions and constraints relevant to its designated phase, effectively encoding multi-stage writing logic into a singular, continuous inference process. This parametric approach allows for fine-grained control over the LLM’s behavior at each stage, enabling the model to dynamically adjust its output based on the current phase represented by the active stage token.
The STIG model compresses multi-stage writing logic into a single inference pass by representing each phase of document creation with a parametric stage token. Traditional agentic workflows require sequential calls to a language model for each stage – outlining, drafting, revising – resulting in multiple inference passes. STIG, however, encodes the instructions for these sequential stages within the initial input using stage tokens, allowing the language model to generate the entire document in a single forward pass. This consolidation eliminates the overhead associated with repeated model calls and data transfer, significantly streamlining the generation process and reducing computational demands.
The STIG model facilitates the single-pass creation of comprehensive documents by orchestrating Large Language Model (LLM) Agents using parametric stage tokens. This approach contrasts with standard agentic workflows, which typically require multiple sequential inferences to complete a document. Empirical results demonstrate that STIG achieves a 3.3x improvement in computational efficiency compared to these traditional multi-step processes. This efficiency gain is attributed to the consolidation of multi-stage writing logic into a single inference pass, reducing the overhead associated with iterative prompting and data transfer between agents.
Empirical Validation of Coherence and Structure
Experiments were conducted to assess STIG’s introductory paragraph generation capabilities using two large language models as backbones: Llama3 and Qwen2.5. Results indicate that STIG successfully generates text exhibiting both coherence and structural soundness when integrated with either model. This demonstrates STIG’s adaptability and its potential as a broadly applicable method for automating the creation of introductory sections in scholarly documents, irrespective of the underlying language model employed for text generation.
Quantitative analysis demonstrates that STIG outperforms the AutoSurvey baseline model in both semantic similarity and structural rationality. Specifically, when evaluated on the Qwen2.5-7B-Instruct model, STIG achieves a Structural Rationality (SR) score of 0.832, a notable improvement over AutoSurvey’s score of 0.658. This metric assesses the logical coherence and organizational soundness of generated text, indicating that STIG produces introductions with a significantly more rational and well-defined structure compared to the baseline.
The training and evaluation of the model utilized a dataset specifically curated from the Association for Computational Linguistics (ACL) Anthology. This anthology, a comprehensive archive of research papers in computational linguistics and natural language processing, ensures the model is exposed to and assessed on text representative of scholarly writing conventions. The use of this dataset prioritizes the model’s ability to generate text appropriate for academic contexts, focusing on characteristics such as formal tone, technical vocabulary, and adherence to established research communication standards. This targeted approach to data selection directly supports the model’s performance in generating coherent and structurally sound introductions for scholarly articles.

Towards Adaptive Systems and Efficient Communication
The Structured Introduction Generation (STIG) model, initially designed to craft compelling introductory paragraphs, possesses a flexible architecture that extends its utility far beyond this single application. Its modular design, emphasizing stage-wise token control and iterative refinement, lends itself readily to tackling more complex writing tasks, such as the automated generation of comprehensive reports and extended long-form content. Researchers envision adapting the core principles of STIG – breaking down writing into manageable stages, strategically allocating tokens, and prioritizing key information – to orchestrate the creation of detailed analyses, technical documentation, and even creative writing pieces. This adaptability suggests a broader potential for STIG as a foundational component in various natural language generation pipelines, moving beyond simple introductions to facilitate comprehensive content creation across diverse domains.
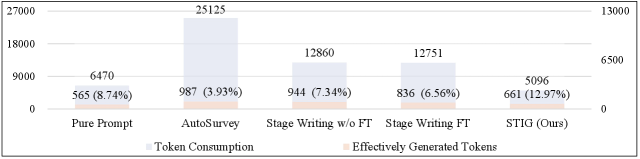
The STIG model offers a pathway to substantial reductions in token consumption during text generation, directly impacting both financial costs and operational efficiency. By strategically optimizing the generative process – focusing on pertinent information and minimizing redundancy – the model requires fewer tokens to produce comparable or even superior content. This optimization isn’t merely about reducing expenses; it also allows for the handling of larger, more complex writing tasks within the constraints of available computational resources. Consequently, organizations leveraging this approach can unlock greater productivity, scale content creation efforts, and democratize access to advanced language models without incurring prohibitive costs associated with extensive token usage.
Investigations are now centering on refinements to the STIG model’s stage token designs, aiming to unlock even more nuanced control over the generative process. This includes experimenting with novel token architectures capable of representing complex instructions and stylistic preferences with greater fidelity. Simultaneously, efforts are underway to seamlessly integrate STIG with agentic workflows – systems where autonomous agents can utilize the model to independently plan, execute, and revise content creation tasks. This convergence of advanced token engineering and agentic control promises to move beyond simple text generation, enabling the creation of highly tailored, long-form content with minimal human intervention and maximized efficiency, ultimately offering a pathway to truly automated content creation pipelines.
The pursuit of streamlined scientific writing, as demonstrated by STIG, echoes a fundamental principle of system design: elegant solutions often lie in internal complexity rather than external orchestration. This research elegantly consolidates the agentic workflow-typically a series of calls and dependencies-into a single, parametrically controlled LLM. Robert Tarjan observed, “Complexity is not a bug, it’s a feature.” Indeed, STIG doesn’t eliminate complexity; it internalizes it, embedding the logic of stage tokens directly within the model. This approach acknowledges that any simplification-removing external agents-carries a future cost: a more intricate internal structure. However, this internalized complexity, as the paper demonstrates, yields significant gains in efficiency and quality, suggesting a system designed to age gracefully, even under the pressures of evolving scientific discourse.
What Remains to Be Seen
The pursuit of streamlined introduction generation, as exemplified by this work, reveals a recurring tension. Each abstraction-here, the parametric stage token-inherently carries the weight of past solutions. While STIG effectively internalizes what was previously externalized as agentic workflow, it does not erase the fundamental challenge of representing scientific reasoning within a finite model. Future iterations will inevitably confront the limitations of embedding complex epistemic structures into static parameters. The question is not whether these embeddings will degrade, but how gracefully.
A critical path forward lies in acknowledging that ‘efficiency’ is a transient metric. Reducing computational cost today may simply accelerate the need for more substantial architectural overhauls tomorrow. The true measure of progress will be found in systems that prioritize resilience-those capable of adapting to evolving knowledge without catastrophic failure. This demands a move beyond optimizing for specific evaluation metrics, and toward a deeper understanding of how scientific concepts are truly represented, and revised, over time.
Ultimately, the field will be defined not by the elimination of workflows, but by the acceptance that all systems decay. The longevity of any given approach-whether reliant on stage tokens or some future innovation-will depend not on its initial elegance, but on its capacity for slow, incremental change.
Original article: https://arxiv.org/pdf/2601.09728.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- How to find the Roaming Oak Tree in Heartopia
- M7 Pass Event Guide: All you need to know
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
2026-01-18 13:15