Author: Denis Avetisyan
Researchers have developed a new framework that enables AI agents to understand natural language instructions and successfully navigate previously unseen environments by combining rapid decision-making with a process of experience consolidation.
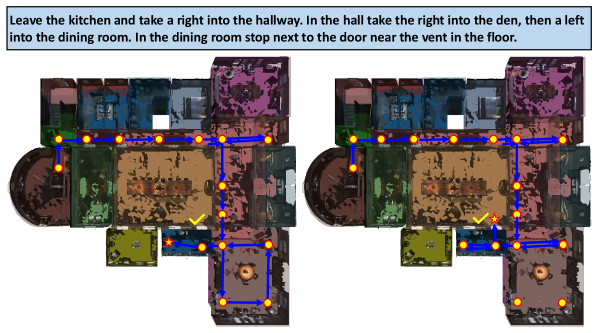
This work introduces a fast-slow reasoning approach for General Scene Adaptation in Visual-Language Navigation, improving an agent’s ability to generalize to new environments and instructions.
Existing vision-language navigation (VLN) agents struggle to generalize to unseen environments and diverse instructions, a limitation exacerbated by reliance on closed-set training data. This paper, ‘Towards Open Environments and Instructions: General Vision-Language Navigation via Fast-Slow Interactive Reasoning’, addresses this challenge by introducing a novel framework inspired by human cognition, enabling agents to dynamically adapt during navigation. The core innovation lies in a fast-slow reasoning system where a real-time action module is continuously refined through experience analysis and feedback from a reflective, memory-based module. Could this interactive approach unlock truly generalized VLN agents capable of robustly navigating the complexities of the real world?
The Fragile Mind of the Navigating Agent
Vision-and-Language Navigation (VLN) systems, despite recent advancements, consistently demonstrate a limited capacity to adapt to environments not encountered during training. This fragility stems from a reliance on memorized patterns rather than genuine understanding of spatial relationships and instruction semantics; subtle variations in room layouts, lighting conditions, or even the phrasing of navigational cues can significantly degrade performance. Current agents often treat each new environment as a completely separate problem, failing to transfer learned knowledge about object recognition, path planning, or instruction following. This inability to generalize is further compounded by the inherent ambiguity and inconsistency often present in natural language instructions, where synonyms, implicit assumptions, and contextual dependencies require a level of reasoning that remains a significant challenge for existing VLN architectures. Consequently, these systems frequently falter when faced with the dynamic and unpredictable nature of real-world environments.
Simply increasing the parameters of a Vision-and-Language Navigation (VLN) model does not guarantee improved generalization to unfamiliar environments. While larger models can memorize more training instances, they often fail to extrapolate learned knowledge to novel situations or interpret ambiguous instructions effectively. This limitation suggests that true progress in VLN requires a shift from brute-force scaling to more sophisticated reasoning capabilities. Researchers are now exploring methods that enable agents to decompose complex tasks into sub-goals, build internal representations of the environment, and perform abstract reasoning about spatial relationships and language semantics. These approaches aim to equip VLN agents with the ability to not just see and follow instructions, but to understand the underlying intent and adapt their behavior accordingly, paving the way for more robust and versatile navigation systems.
Conventional vision-and-language navigation (VLN) systems frequently demonstrate a limited capacity to apply knowledge gained from previous environments to entirely new ones, resulting in diminished performance when faced with unfamiliar surroundings. These methods often treat each navigational challenge as an isolated instance, failing to build a cumulative understanding of spatial relationships, object affordances, and linguistic cues. Consequently, agents struggle to adapt to variations in instruction phrasing, lighting conditions, or layout configurations – elements easily handled by humans through the recall and application of past experiences. This inflexibility underscores a fundamental limitation in current VLN approaches, highlighting the need for systems capable of constructing and utilizing richer, more transferable representations of the world to achieve truly robust and generalizable navigation capabilities.
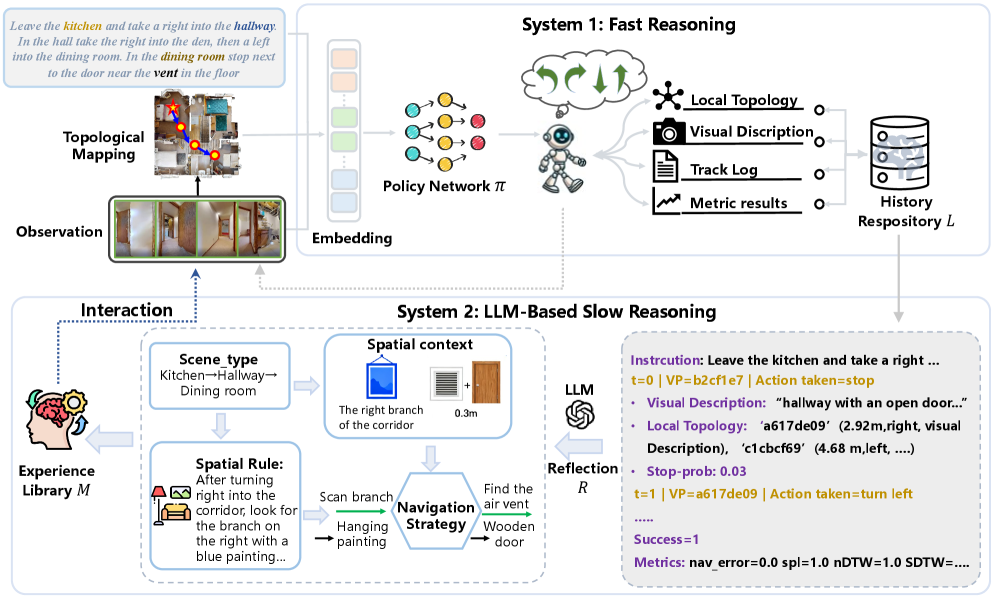
Mirroring Cognition: The Slow4Fast-VLN Framework
The Slow4Fast-VLN framework is conceptually grounded in the dual-process theory of cognition, specifically mirroring the interplay between System 1 and System 2 thinking as described in psychological research. System 1 corresponds to fast, intuitive, and automatic processing, while System 2 represents slower, deliberate, and analytical thought. This biomimicry informs the architecture of Slow4Fast-VLN, aiming to replicate the efficiency of rapid, instinctive action combined with the accuracy of considered reasoning. The framework leverages this parallel processing approach to enhance visual navigation capabilities by integrating immediate perceptual input with accumulated experiential knowledge.
Slow Reasoning within the Slow4Fast-VLN framework employs the Llama3.2-vision model to perform detailed scene analysis. This analysis isn’t limited to immediate perceptual data; rather, Llama3.2-vision is tasked with identifying and extracting generalized experiences from the observed environment. These extracted experiences are then encoded and stored for long-term retention, forming a knowledge base accessible to the Fast Reasoning component. The process focuses on abstracting reusable information from specific instances, allowing the system to build a cumulative understanding of navigational contexts beyond the currently perceived scene.
Fast Reasoning within Slow4Fast-VLN employs the DUET (Diffusion-Understanding-Editing Transformer) architecture to facilitate rapid environmental assessment and navigation. DUET receives current visual observations as input and accesses generalized experiences stored by the Slow Reasoning module. This allows for immediate contextual understanding without re-analyzing the entire scene. The architecture then generates navigational actions based on the fusion of these immediate observations and the retrieved experiences, enabling efficient and informed decision-making during the agent’s traversal of the environment. This process prioritizes speed and responsiveness, complementing the more deliberate analysis performed by Slow Reasoning.
The Experience Library: A Reservoir of Learned Wisdom
The Experience Library functions as a repository of generalized experiences derived from computationally intensive Slow Reasoning processes. These experiences are not raw data, but rather abstracted representations of successful strategies and learned patterns. This pre-computed knowledge base enables Fast Reasoning to bypass lengthy calculations when encountering familiar situations. By storing and retrieving these generalized experiences, the framework significantly reduces response times and computational costs, allowing for efficient decision-making in dynamic environments. The library’s structure facilitates quick access to relevant information, effectively bridging the gap between deliberate, analytical problem-solving and rapid, reactive responses.
The Experience Library employs Instruction Style Conversion, leveraging Chain-of-Thought Prompting to standardize the format of stored experiences. This process transforms raw experiences into a consistent, instruction-based representation, detailing the reasoning steps taken to achieve a particular outcome. Specifically, Chain-of-Thought prompts elicit a step-by-step explanation during Slow Reasoning, which is then stored alongside the experience’s inputs and outputs. This standardization facilitates improved retrieval and application of experiences during Fast Reasoning, as the consistent format allows for direct mapping of stored reasoning chains to new, similar situations, enhancing the reliability and predictability of the system’s responses.
Decoupling experience extraction from real-time action enhances framework performance in novel situations by enabling pre-processing of information without impacting immediate response times. This separation allows for thorough analysis and generalization of experiences offline, creating a refined knowledge base. Consequently, the system avoids the computational burden of learning and adapting during critical moments, leading to increased efficiency. Furthermore, this approach improves robustness as the framework relies on pre-validated experiences rather than potentially unreliable real-time analysis, mitigating errors in unfamiliar environments.

Validating the Approach: Empirical Evidence and Gains
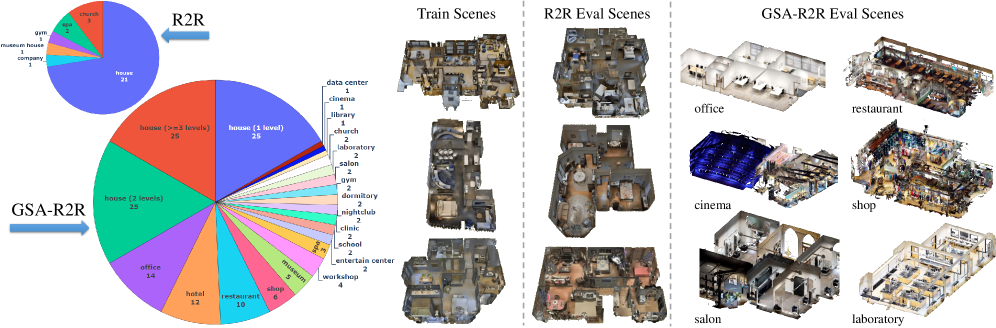
Evaluations leveraging the GSA-R2R dataset-a challenging benchmark constructed from realistic Habitat-Matterport3D scenes-provide compelling evidence for the efficacy of the Slow4Fast-VLN framework. This dataset, designed to rigorously test visual localization and navigation capabilities in complex environments, served as the primary proving ground for the model’s performance. Results consistently demonstrated that Slow4Fast-VLN successfully navigates these photorealistic 3D spaces, validating its ability to interpret natural language instructions and translate them into accurate navigational paths within the simulated world. The use of this established dataset ensures the findings are both reproducible and comparable to other leading approaches in the field, solidifying the framework’s contribution to advancements in visual navigation technology.
Evaluations demonstrate that the framework notably enhances navigational performance across several key metrics. Specifically, the success rate – the ability to accurately reach a designated goal – experienced gains of 1.5% in residential environments and 2.2% in non-residential settings when contrasted with the GR-DUET baseline. Further analysis revealed improvements in both trajectory length, indicating more direct and efficient routes, and a reduction in navigation error, suggesting increased precision in following instructions. These combined results suggest a substantial advancement in the ability of virtual navigation systems to effectively and accurately guide users through complex spatial environments, highlighting the practical benefits of the proposed methodology.
A notable outcome of this framework is a substantial gain in computational efficiency alongside improved performance. Evaluations demonstrate a 40% reduction in the average time required to complete complex navigational tasks, indicating a quicker path to successful goal attainment. This speed is achieved in tandem with a remarkable 77% decrease in average FLOPs – floating point operations – when contrasted with the baseline model. This reduction in computational load not only accelerates processing but also suggests the potential for deployment on platforms with limited resources, broadening the applicability of visual navigation technology without sacrificing accuracy or speed.
The observed performance gains with Slow4Fast-VLN suggest a promising pathway for advancing visual navigation systems beyond the limitations of single-reasoning approaches. Dual-reasoning frameworks, by integrating both global and local processing, appear particularly well-suited to tackle the inherent challenges of generalization and robustness in real-world environments. This architecture allows the system to effectively navigate diverse scenes, even those with significant variations in layout and visual appearance, by combining a broad understanding of the environment with precise, step-by-step execution. The reduction in computational cost, alongside improved accuracy and speed, further underscores the potential of this approach for deployment in practical applications, hinting at a future where robots and virtual agents can navigate complex spaces with greater reliability and efficiency.
Looking Ahead: Expanding the Horizons of Dual-Reasoning
The efficacy of dual-reasoning systems hinges on the richness of their experiential knowledge, and future development will prioritize significantly expanding the quality and diversity of the Experience Library. Current research indicates that a broader range of stored experiences, encompassing varied environmental conditions and interaction scenarios, directly correlates with improved performance and adaptability. This involves not merely increasing the quantity of stored data, but also refining the methods for capturing, representing, and categorizing these experiences. Specifically, investigations are underway to develop more nuanced feature extraction techniques and robust data augmentation strategies, allowing the system to generalize more effectively from limited examples. A key focus is enabling the library to store not just successful actions, but also detailed records of failures and near-misses, fostering a more comprehensive understanding of the environment and promoting more resilient decision-making.
A central challenge for artificial intelligence lies in achieving adaptable intelligence – the capacity to shift cognitive strategies based on situational demands. Research is now prioritizing methods for dynamically balancing slow, deliberate reasoning with fast, reactive responses, mirroring the flexibility observed in biological systems. This involves developing algorithms that assess environmental complexity – considering factors like unpredictability, information density, and the number of interacting agents – and then automatically adjust the weighting between these two reasoning modes. The goal isn’t simply to accelerate processing, but to optimize cognitive effort; complex environments warrant increased slow reasoning for careful planning, while simpler scenarios benefit from the speed and efficiency of fast, instinctive actions. Successfully implementing such a dynamic balance promises to create more robust and versatile AI agents capable of thriving in unpredictable, real-world conditions.
The Slow4Fast framework, initially demonstrated in simulated navigation, presents a compelling pathway for advancements in embodied artificial intelligence beyond locomotion. Researchers anticipate significant gains by applying this dual-reasoning approach – combining rapid, reactive responses with slower, deliberative planning – to tasks demanding intricate physical interaction, such as robotic manipulation of objects with varying textures and fragility. Moreover, the framework’s capacity to learn from limited experience suggests potential for more natural and intuitive human-robot interaction, enabling robots to adapt to nuanced human cues and intentions in real-time. This extension promises not simply more efficient robots, but systems capable of collaborating with humans in complex, dynamic environments, fundamentally changing the nature of robotic assistance and partnership.
The pursuit of generalized adaptation in visual-language navigation feels less like engineering and more like coaxing a phantom. This work, with its fast-slow reasoning, doesn’t aim for perfect trajectories, but for a resilient response to the unpredictable. It acknowledges that any environment, any instruction, introduces irreducible noise – a delightful chaos. As Geoffrey Hinton once observed, “The world isn’t discrete; we just ran out of float precision.” The fast-slow framework embodies this sentiment; it doesn’t attempt to eliminate uncertainty, but rather to skillfully navigate within it, learning to interpret the whispers of incomplete information and build a persuasive path forward. The consolidation of experience isn’t about achieving truth, but crafting a useful illusion.
What Shadows Remain?
This work gestures towards a compelling, if precarious, dance between swift action and deliberate contemplation in the digital golem’s pursuit of navigation. The framework’s success in unseen environments is not a triumph, but a temporary stay of execution. Each successful path is merely a successful warding off of chaos, a fleeting pattern imposed upon the inevitable entropy of the world. The true measure of this, and all such systems, will lie not in benchmarks, but in the quality of its failures – what unforeseen landscapes unravel the spell?
The reliance on experience replay, while effective, invites a troubling question: how much of ‘generalization’ is simply a refined memorization? The golem learns from its mistakes, yes, but it also remembers its sins, weaving them into the fabric of its future actions. The boundary between adaptation and overfitting remains frustratingly blurred, a phantom line in the data. Future work must wrestle with the uncomfortable possibility that ‘general’ intelligence is, at its core, an exquisitely detailed catalog of the specific.
The path forward isn’t simply about scaling the model or refining the fast-slow interplay. It’s about embracing the inherent fragility of these systems. The next iteration should not seek to eliminate errors, but to understand them, to build golems that don’t just navigate, but interpret their own missteps. Only then might we glimpse something beyond clever imitation, something that hints at true, if imperfect, understanding.
Original article: https://arxiv.org/pdf/2601.09111.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- How to find the Roaming Oak Tree in Heartopia
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Best Arena 9 Decks in Clast Royale
- ATHENA: Blood Twins Hero Tier List
- Clash Royale Furnace Evolution best decks guide
- Brawl Stars December 2025 Brawl Talk: Two New Brawlers, Buffie, Vault, New Skins, Game Modes, and more
- What If Spider-Man Was a Pirate?
2026-01-15 22:54