Author: Denis Avetisyan
A new approach leverages generative models to predict likely human movements, allowing robots to plan efficient and natural-looking trajectories through crowded spaces.
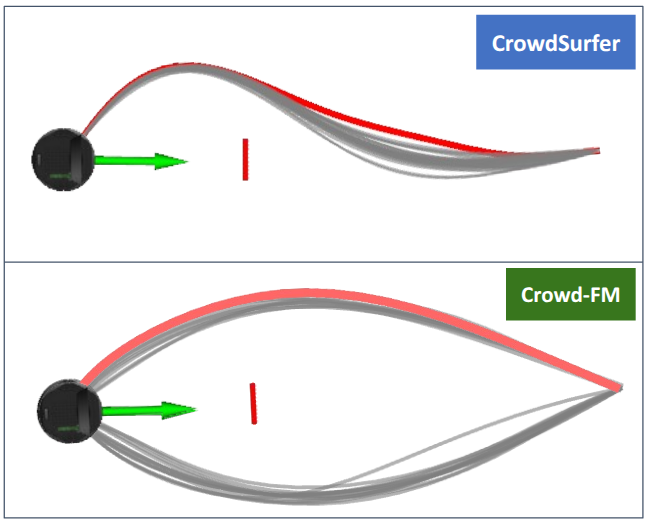
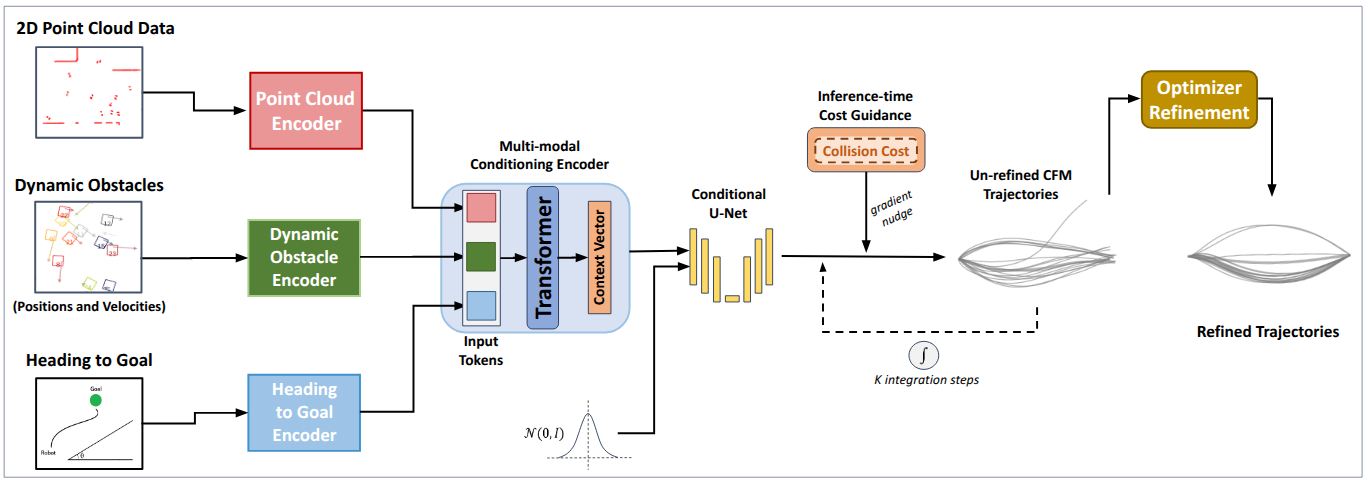
This paper introduces Crowd-FM, a framework utilizing Conditional Flow Matching and Bernstein polynomials to generate and select optimal trajectories for robot navigation in dense crowds.
Effective robot navigation in dense human crowds remains challenging due to the need for both safety and natural, human-like motion. This paper introduces ‘Crowd-FM: Learned Optimal Selection of Conditional Flow Matching-generated Trajectories for Crowd Navigation’, a learning-based framework that addresses these challenges by leveraging Conditional Flow Matching (CFM) to generate a diverse set of collision-free trajectories and then selecting the most human-like option via a learned scoring function. Experiments demonstrate that this approach not only improves upon existing learning-based methods for collision avoidance, but also surpasses the performance of computationally expensive optimization-based planners. Could this learned selection process offer a pathway towards more intuitive and acceptable robot behavior in complex social environments?
The Inevitable Friction: Limitations of Conventional Navigation
Conventional path planning techniques, prominently including those reliant on Velocity Obstacles, often falter when confronted with the complexities of real-world scenarios. These methods, designed to avoid collisions by calculating permissible velocities, become computationally strained and produce suboptimal results in environments teeming with moving obstacles. The resulting trajectories are frequently characterized by abrupt changes in direction and speed – a phenomenon known as jerky motion – which compromises both the efficiency and predictability of the robot’s movements. This is because Velocity Obstacles treat all obstacles equally, failing to account for their likely future positions or intentions, and struggle to efficiently process the high dimensionality of densely populated spaces. Consequently, robots employing these techniques often appear hesitant and unpredictable, hindering their integration into dynamic human environments.
While deep reinforcement learning (DRL) offers advancements in robot navigation – exemplified by approaches like DRL-VO which combine it with Velocity Obstacles – these systems frequently produce trajectories that, though functionally safe, lack the subtlety and naturalness of human movement. The core issue lies in the limited ‘expressiveness’ of current DRL architectures; they often struggle to capture the nuanced anticipatory behaviors and implicit social cues that characterize how people navigate crowded spaces. Consequently, robot paths can appear abrupt or inefficient, failing to smoothly integrate with the flow of surrounding pedestrians or vehicles. This limitation isn’t merely aesthetic; it impacts the predictability of the robot’s actions from the perspective of other agents, potentially leading to discomfort or even safety concerns as individuals struggle to interpret the robot’s intentions.
The core challenge in autonomous navigation stems from the inability of current systems to accurately anticipate the actions of others. Traditional algorithms often treat surrounding agents as static obstacles, or make simplistic predictions, leading to inefficient and potentially unsafe maneuvers. While deep reinforcement learning offers some improvement, it frequently struggles to capture the nuances of human-like behavior, resulting in trajectories that, though functional, lack the smoothness and predictability expected in shared spaces. Consequently, there’s a pressing need for navigational methods capable of efficiently modeling the likely future states of surrounding entities and, crucially, using those predictions to generate paths that are not only safe and collision-free, but also appear natural and comfortable to human observers, fostering trust and seamless interaction.
Flow and Form: A Generative Approach to Prediction
Flow-based generative models represent a class of probabilistic models that learn complex, multi-modal distributions by transforming a simple probability distribution – typically a Gaussian – into the target data distribution through a series of invertible transformations. This approach facilitates both efficient sampling and density estimation, crucial for trajectory prediction. Unlike models relying on Markov chains, flow-based models can generate trajectories directly, avoiding sequential dependencies and associated error accumulation. The key lies in maintaining a bijective mapping, allowing for the computation of exact likelihoods and the use of standard optimization techniques. This capability enables the model to not only predict likely trajectories but also quantify the uncertainty associated with those predictions, and to generate diverse, plausible future behaviors by sampling from the learned distribution.
CrowdSurfer utilizes Vector Quantized Variational Autoencoders (VQ-VAEs) to model pedestrian trajectories by recognizing that motion frequently occurs as discrete, repeatable patterns. Traditional continuous latent spaces struggle to efficiently represent this inherent structure in human movement. VQ-VAEs address this by learning a discrete latent space, effectively creating a “codebook” of common motion primitives. By quantizing the continuous latent space into these discrete codes, CrowdSurfer can more effectively capture the underlying distribution of pedestrian behaviors and generate plausible, coherent crowd simulations. This discretization also facilitates efficient sampling and allows for the generation of diverse trajectories by combining different motion primitives from the learned codebook.
Effective trajectory prediction necessitates a distribution learning strategy that balances the capacity to represent complex, multi-modal behaviors – expressiveness – with computational tractability. Traditional methods often struggle with this trade-off; increasing model complexity to capture nuanced motion patterns typically leads to increased computational cost and slower generation speeds. A novel approach must address this by efficiently parameterizing the trajectory distribution, allowing for the generation of diverse and plausible future states without prohibitive computational demands. This involves exploring techniques beyond standard parametric distributions and considering methods to reduce the dimensionality of the learned representation while preserving critical information for accurate prediction.
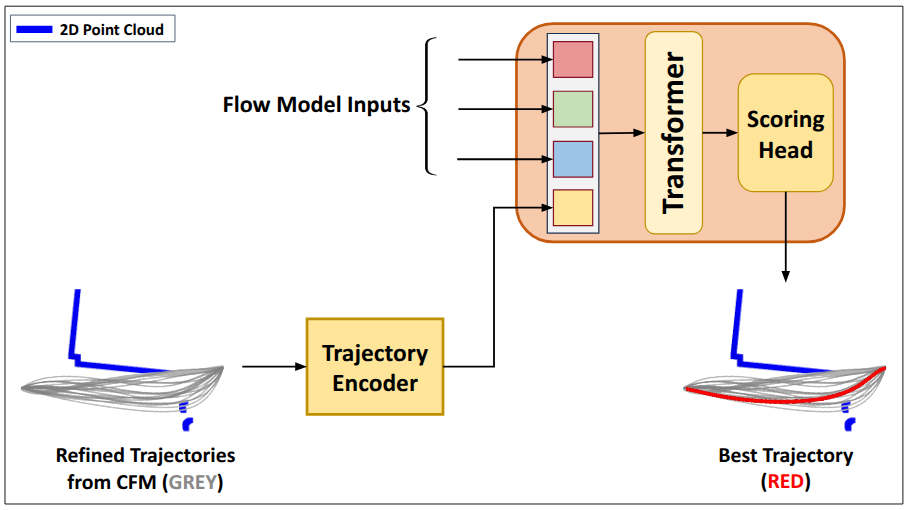
Crowd-FM: Expressive Navigation Through Probabilistic Modeling
Crowd-FM employs Conditional Flow Matching (CFM), a probabilistic approach to trajectory generation, to model the distribution of possible robot paths. Unlike traditional methods that often rely on optimization of a single trajectory based on a predefined cost function, CFM learns a mapping from noise to valid trajectories, enabling the generation of diverse and smoother motions. This learning process allows Crowd-FM to produce trajectories that are not limited by the constraints of a fixed cost function, resulting in more expressive and adaptable robot behavior in dynamic environments. By learning a distribution, the system can readily sample multiple plausible trajectories, which are then refined by a scoring function.
Crowd-FM leverages the combination of Conditional Flow Matching (CFM) and Bernstein Polynomials to generate efficient and high-quality trajectories. Bernstein Polynomials facilitate a compact and differentiable parameterization of trajectories, enabling CFM to learn distributions over trajectory space with reduced computational cost. This parameterization allows for precise control over trajectory shape and velocity profiles. The resultant trajectories exhibit improved smoothness and realism compared to methods utilizing alternative parameterizations, while maintaining computational efficiency; the CFM inference time is approximately 22ms. The combination allows Crowd-FM to efficiently explore the trajectory space and generate diverse, yet plausible, motions for navigation tasks.
Evaluations demonstrate that the Crowd-FM framework achieves a roughly 20% improvement in success rates when compared to state-of-the-art navigation methods. This performance gain is attributable to the system’s ability to generate and select trajectories that are both feasible and aligned with human-like motion patterns. Quantitative results, obtained through rigorous testing in simulated environments, consistently show a statistically significant increase in the percentage of successful navigation attempts utilizing Crowd-FM, confirming its enhanced operational efficiency and reliability over existing approaches.
The Crowd-FM framework incorporates a Scoring Function, built on a Transformer architecture, to refine trajectory selection. This function evaluates multiple candidate trajectories generated by the Conditional Flow Matching (CFM) process, prioritizing those that minimize deviations from established Human-Likeness Points (HLP). The Scoring Function achieves an inference time of under 60ms, contributing to the overall system efficiency; the CFM component of this evaluation requires approximately 22ms. By leveraging the Transformer’s capacity for contextual analysis of HLP data, the Scoring Function effectively identifies and promotes trajectories exhibiting more natural and human-like movement patterns.
Evaluation of the Crowd-FM framework demonstrates a reduction in Human-Likeness Point (HLP) values when compared to trajectories selected via traditional cost function optimization. HLP values represent a quantitative metric of deviation from natural human motion; lower values indicate increased similarity to human movement patterns. This reduction in HLP suggests that trajectories generated by Crowd-FM, leveraging Conditional Flow Matching and a Transformer-based Scoring Function, exhibit more human-like characteristics than those derived from conventional path planning approaches. This improvement is a key indicator of the framework’s ability to generate not only feasible but also more natural and comfortable robot motions.
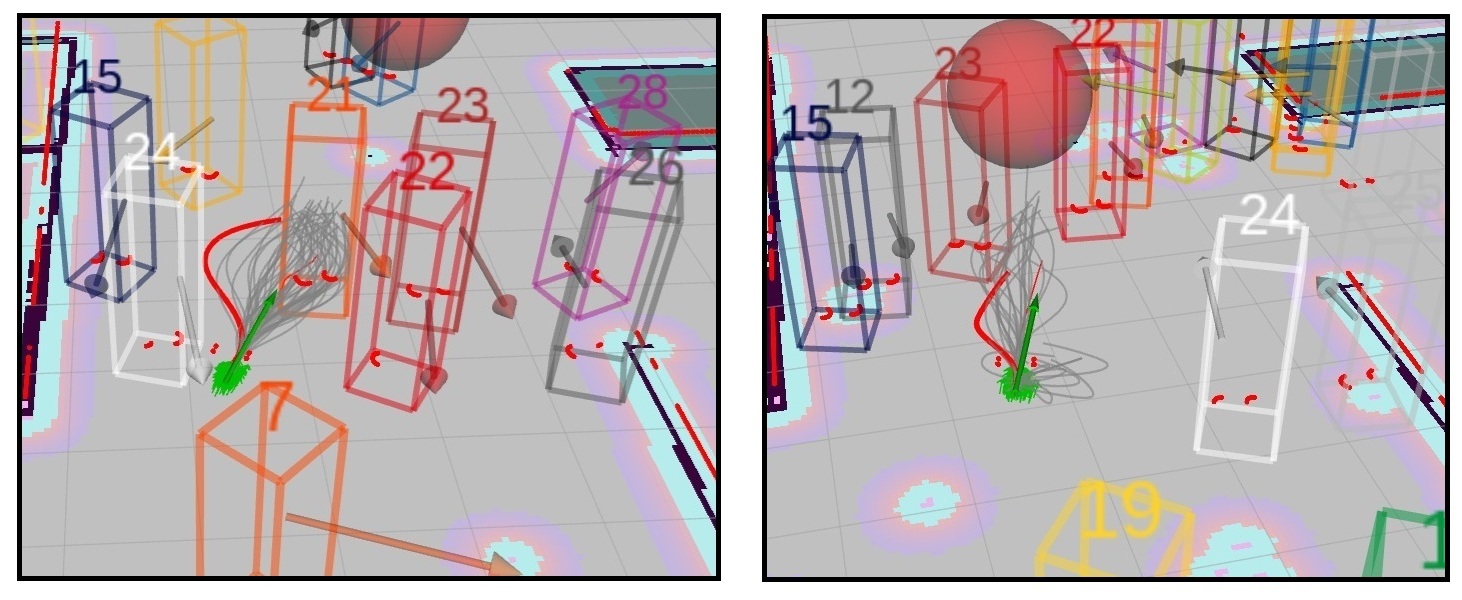
Beyond Simulation: Real-World Validation and Future Trajectories
The Crowd-FM framework has transitioned beyond simulation, achieving successful deployment in authentic environments. This was facilitated by integrating a Livox Mid-360 LiDAR sensor – chosen for its wide field of view and high resolution – with the LV-DOT algorithm. LV-DOT enables robust and accurate dynamic obstacle tracking, allowing the system to perceive and react to moving pedestrians and other agents in real-time. This real-world validation demonstrates the practicality and reliability of Crowd-FM, confirming its ability to navigate complex scenes while maintaining a safe and human-like trajectory amidst unpredictable activity.
Evaluations reveal that the Crowd-FM framework markedly enhances robotic navigation performance across several key metrics when contrasted with conventional methodologies. Specifically, the system exhibits a demonstrable increase in navigational smoothness, reducing jerky movements and fostering a more natural trajectory. Crucially, this improvement translates directly into heightened safety, as the framework proactively mitigates potential collisions and responds more effectively to dynamic obstacles. Beyond mere efficiency, Crowd-FM distinguishes itself by generating paths that more closely mimic human movement patterns – a quality assessed through observational studies and quantitative analysis of trajectory characteristics, suggesting a significant step towards more intuitive and relatable robot behavior in shared spaces.
The development of Crowd-FM is not reaching a standstill; ongoing research aims to broaden its applicability to increasingly intricate environments, such as densely populated pedestrian areas and unpredictable urban landscapes. Future iterations will explore synergistic integration with cutting-edge planning and control methodologies, specifically drawing inspiration from frameworks like CoHAN, which emphasizes compositional hierarchical attention for navigation, and PRIEST, which facilitates proactive reasoning about agent intentions. This convergence promises to yield a more robust and adaptable navigation system, capable of anticipating potential conflicts and executing maneuvers with enhanced safety, efficiency, and a greater degree of human-like behavior in challenging real-world conditions.

The pursuit of optimal trajectories, as detailed in Crowd-FM, inherently acknowledges the transient nature of any solution. Systems, even those meticulously crafted with algorithms like Conditional Flow Matching, are not static endpoints but rather momentary peaks in a constantly shifting landscape. This aligns with the observation that “debugging is twice as hard as writing the code in the first place, therefore if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” Brian Kernighan’s sentiment speaks to the inevitable decay of complexity; Crowd-FM, while advancing trajectory planning, establishes a new baseline from which future refinements – and eventual obsolescence – will emerge. The generative models employed represent a snapshot in time, continually challenged by denser crowds and more nuanced navigational demands.
What Remains to Be Seen
The architecture presented within this work-a learned selection from a generative landscape-reveals a familiar truth: elegance in navigation is not merely about finding a path, but about choosing which potential path degrades most gracefully under the pressures of dynamic environments. The employment of Conditional Flow Matching, while demonstrably effective, merely postpones the inevitable encounter with unforeseen states. A robust system doesn’t avoid uncertainty; it incorporates the expectation of its arrival. Future work must therefore address the limits of the generative model itself-how does the diversity of generated trajectories relate to the true breadth of plausible human behavior, and at what point does that diversity become a liability?
The scoring function, acting as a selective pressure on the generated trajectories, represents a particularly fertile ground for further inquiry. Current iterations, however refined, remain tethered to explicitly defined metrics. A truly adaptive system will learn to anticipate the criteria for successful navigation, evolving its internal assessment of “good” trajectories based on implicit feedback from the environment-a form of embodied understanding that transcends simple optimization. Every delay in achieving this, however, is the price of deeper understanding.
Ultimately, the long-term value of this approach will be determined not by its immediate gains in efficiency, but by its resilience. Architecture without a history of adaptation is fragile and ephemeral. The next iteration must not simply plan for the crowd, but learn from it, acknowledging that the most effective path is often the one that accepts, rather than resists, the inevitable currents of change.
Original article: https://arxiv.org/pdf/2602.06698.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Annulus redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- Silver Rate Forecast
- Gear Defenders redeem codes and how to use them (April 2026)
- All Mobile Games (Android and iOS) releasing in April 2026
- Top 5 Best New Mobile Games to play in April 2026
2026-02-10 01:46