Author: Denis Avetisyan
A new framework improves question answering over lengthy documents by understanding their structure and intelligently navigating content.
DeepRead introduces a coordinate-based system for agentic RAG, enhancing long-document reasoning and hierarchical information retrieval.
While recent advances in Retrieval-Augmented Generation (RAG) have enabled more sophisticated agentic search, existing frameworks often treat long documents as unstructured text, overlooking critical organizational cues. This limitation motivates the work ‘DeepRead: Document Structure-Aware Reasoning to Enhance Agentic Search’, which introduces a novel approach to long-document question answering by explicitly leveraging hierarchical structure and sequential discourse. DeepRead employs a coordinate-based system to navigate documents, enabling an agent to efficiently locate and read relevant passages-mimicking human reading patterns and achieving significant performance gains. Could this structure-aware reasoning paradigm unlock even more effective strategies for knowledge extraction from complex, long-form content?
The Limits of Context: Navigating Information Overload
Large Language Models have demonstrated remarkable proficiency in generating human-quality text, translating languages, and even composing creative content. However, their inherent architecture presents a significant bottleneck when applied to tasks requiring extensive knowledge. These models operate with a fixed “context window”-a limited capacity to process input text at any given time. While adept at understanding relationships within this window, they struggle to integrate information from sources exceeding its size. This constraint impacts knowledge-intensive applications – such as answering complex questions based on lengthy reports, legal documents, or scientific papers – because crucial details residing outside the context window remain inaccessible during processing. Effectively, the model’s reasoning and response generation are limited by the amount of information it can actively consider, hindering its ability to provide accurate and reliable answers grounded in comprehensive knowledge.
Attempting to feed extensive documents directly into Large Language Models through simple concatenation-essentially pasting the entire text as context-quickly proves impractical. While seemingly straightforward, this method rapidly overwhelms the model’s limited context window, leading to information loss and diminished performance. Crucially, even within the constrained window, relevant information becomes diluted amongst extraneous details, hindering the model’s ability to accurately identify and utilize key facts. The result is a decline in reasoning accuracy and a propensity for generating responses disconnected from the most pertinent evidence within the source material, effectively negating the benefits of accessing larger knowledge bases.
The inherent constraint of limited context windows within Large Language Models presents a significant obstacle when applied to real-world knowledge sources. Accurate reasoning demands the ability to synthesize information from across extensive documents, yet models falter as crucial details fall outside their processing range. Consequently, answer generation becomes unreliable, prone to inaccuracies or incomplete responses, particularly when dealing with complex or nuanced topics. This isn’t merely a matter of retrieving facts; it’s about establishing the relationships between them, drawing inferences, and applying knowledge appropriately – capabilities severely compromised when the model lacks access to the full informational landscape. The result is a diminished capacity to effectively utilize the wealth of information available, hindering the potential of these models in knowledge-intensive applications.
Initial Retrieval-Augmented Generation (RAG) systems represented a significant step towards addressing the context limitations of Large Language Models, yet often fell short of fully utilizing available information. These early iterations, frequently implemented as one-shot pipelines, primarily focused on retrieving relevant document chunks and appending them to the prompt. While this approach improved performance on knowledge-intensive tasks, it largely disregarded the inherent structure within those documents – the relationships between sections, the importance of headings, and the flow of arguments. Consequently, the models struggled to synthesize information effectively, sometimes producing disjointed or inaccurate responses despite having access to potentially relevant content. The lack of nuanced understanding of document organization meant that crucial contextual cues were often overlooked, hindering the model’s ability to reason deeply and generate truly informed answers.
Beyond Simple Retrieval: Evolving RAG Strategies
Traditional Retrieval-Augmented Generation (RAG) systems initially retrieve documents based on a single query. Modern iterations are moving beyond this approach with techniques such as iterative retrieval and planning to improve information gathering. Iterative retrieval involves formulating follow-up queries based on the content of initially retrieved documents, allowing the system to progressively refine its search and uncover more relevant information. Planning, often implemented using agents or similar architectures, enables the RAG system to decompose complex queries into multiple steps, each requiring specific information retrieval and processing. These methods address limitations of single-pass retrieval by dynamically adjusting search strategies and incorporating feedback from previous iterations, resulting in a more comprehensive and accurate context for the Large Language Model (LLM).
Coarse-to-fine reranking is a two-stage process used to improve the quality of documents retrieved for a Retrieval-Augmented Generation (RAG) pipeline. Initially, a fast, computationally inexpensive method – the ‘coarse’ stage – retrieves a larger set of potentially relevant documents based on initial similarity metrics. This is followed by a ‘fine’ stage, employing a more sophisticated and computationally intensive model, such as a cross-encoder, to re-score these documents based on their relevance to the query and the context. This re-ranking prioritizes documents that are not only semantically similar to the query but also highly relevant in the specific context, resulting in a more focused and accurate set of documents provided to the Large Language Model (LLM).
Embedding models are fundamental to similarity-based retrieval in Retrieval-Augmented Generation (RAG) pipelines. These models transform text into numerical vectors – embeddings – where semantic similarity is represented by proximity in vector space. RAG systems utilize these embeddings to index documents; when a user query is received, it is also converted into an embedding. The system then performs a similarity search, identifying documents with embeddings closest to the query embedding. This allows RAG to retrieve relevant documents without relying on keyword matching, enabling more nuanced and contextually appropriate results. Common embedding models include those based on transformers, such as Sentence-BERT and OpenAI’s embedding models, which are pre-trained on large datasets to capture complex semantic relationships.
Improvements to Retrieval-Augmented Generation (RAG) pipelines, such as iterative retrieval, planning, and coarse-to-fine reranking, directly impact the quality of contextual information supplied to Large Language Models (LLMs). By refining the initial document retrieval and prioritizing the most relevant passages, these techniques reduce noise and ambiguity in the provided context. This enhanced context enables the LLM to more accurately identify and utilize pertinent information, resulting in improved response accuracy, reduced hallucination, and a greater capacity to generate informed and nuanced outputs. The effect is a demonstrable increase in the LLM’s ability to perform complex reasoning and provide reliable answers to user queries.
![DeepRead consistently outperforms a baseline search method across various benchmarks, especially when utilizing a small number of retrieved chunks [latex]k \in \{2,3,5,7\}[/latex], demonstrating the benefit of structure-aware reading in low-resource scenarios.](https://arxiv.org/html/2602.05014v1/x4.png)
DeepRead: A Structure-Aware Agent for Document Reasoning
Traditional Retrieval-Augmented Generation (RAG) systems often fail to adequately account for the inherent structure within documents, treating text as a monolithic block. DeepRead overcomes this limitation by explicitly modeling both document hierarchy – the organizational structure of sections and subsections – and sequential priors, which represent the expected order of information flow. This approach allows the agent to understand the relationships between different parts of a document and to prioritize information based on its position within that structure. By incorporating these structural elements, DeepRead improves the accuracy and relevance of generated responses, particularly in scenarios where understanding context and relationships is critical.
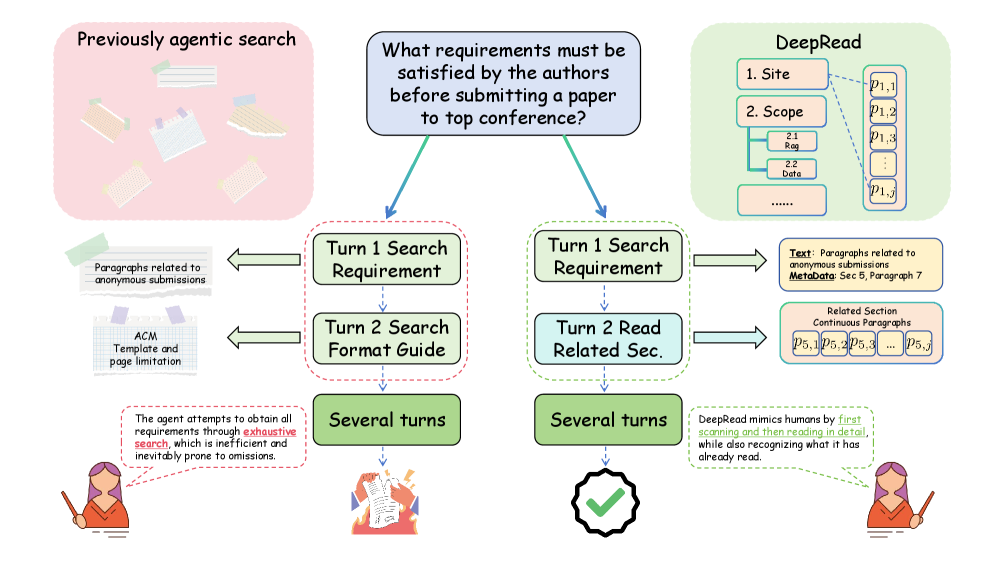
DeepRead employs a two-tool system for document processing: the Retrieve Tool and the ReadSection Tool. The Retrieve Tool initially identifies relevant document sections based on the query. Subsequently, the ReadSection Tool performs contiguous reading, processing text sequentially within those identified sections to maintain the document’s inherent structural order. This scanning-aware localization and sequential reading approach contrasts with methods that randomly sample text, as it prioritizes preserving the relationships between textual elements as defined by the document’s organization, enabling more accurate reasoning and information retrieval.
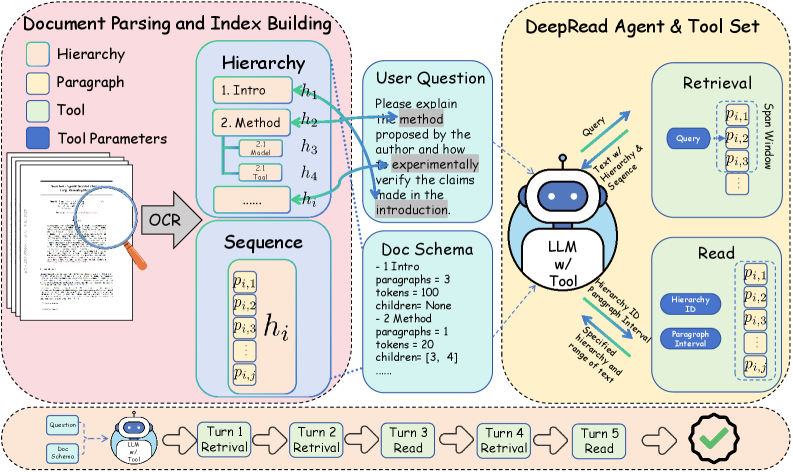
DeepRead addresses the limitations of traditional Retrieval-Augmented Generation (RAG) systems by explicitly modeling document structure through a novel Coordinate System for text location and utilization of Document Sequence. Many agentic RAG systems suffer from “Structural Blindness,” where retrieved text lacks contextual positioning within the original document, hindering accurate reasoning. DeepRead’s Coordinate System assigns precise locations to text segments, while Document Sequence preserves the order of these segments as they appear in the source material. This allows the agent to understand relationships between different parts of the document – such as section headings, lists, and paragraphs – and to prioritize information based on its structural importance, ultimately improving the quality and relevance of generated responses.
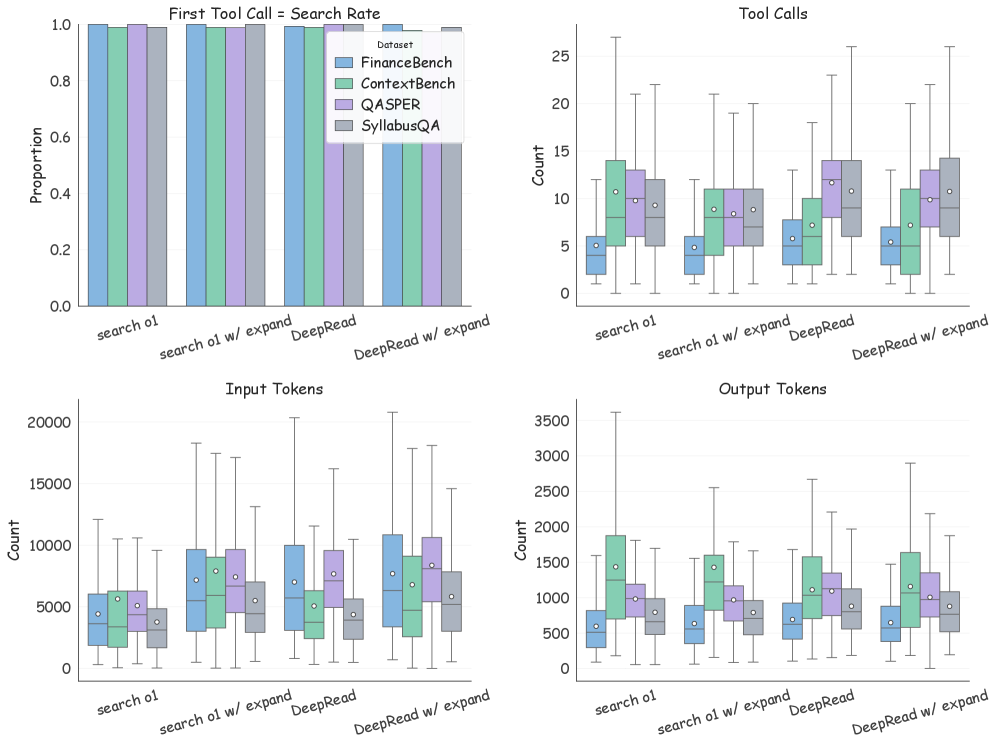
DeepRead’s performance was evaluated using the DeepSeek V3.2 model and question generation facilitated by GLM-4.7, resulting in an average accuracy of 79.5% across four benchmark datasets in multi-turn question answering scenarios. This represents a quantifiable improvement of +10.3 percentage points over current state-of-the-art methodologies. The evaluation methodology focused on assessing DeepRead’s ability to maintain context and provide accurate responses over extended conversational exchanges, demonstrating a statistically significant advancement in performance metrics compared to existing agentic RAG systems.
From Raw Documents to Structured Knowledge: Enabling DeepRead
Multimodal parsing models address the challenge of converting raster-based document images into machine-readable, structured data. These models don’t simply extract text; they analyze the visual layout – including elements like headings, tables, lists, and spatial relationships between blocks of text – and encode this information into a hierarchical representation. This structured representation typically includes bounding box coordinates, detected document elements, and the relationships between them, effectively recreating the document’s original organization. The resulting format facilitates downstream tasks such as information extraction, question answering, and document summarization by providing context beyond the textual content itself.
Optical Character Recognition (OCR) is a technology that converts images of text into machine-readable text data. This process fundamentally relies on pattern recognition and image processing techniques to identify characters within an image. Modern OCR systems utilize deep learning models, specifically convolutional neural networks (CNNs) and recurrent neural networks (RNNs), to achieve high accuracy even with variations in font, size, and image quality. The output of OCR is typically a text string or a structured data format containing the recognized characters, enabling subsequent processing and analysis of the document content. Without accurate OCR, the extraction of textual information from scanned documents, PDFs, and images would not be possible, serving as a critical first step in document understanding pipelines.
PaddleOCR-VL is a document parsing engine leveraging the VLLM (Versatile Language Model Library) to enhance Optical Character Recognition (OCR) performance. This combination allows for improved accuracy in text extraction from document images, particularly in challenging scenarios with varied layouts, fonts, and image quality. VLLM provides optimized inference and serving capabilities, enabling PaddleOCR-VL to process large volumes of documents efficiently. The engine supports multiple languages and document types, delivering a robust solution for converting unstructured document images into machine-readable text for downstream processing within the knowledge extraction pipeline.
The structured representation generated from document parsing enables DeepRead to move beyond simple text extraction and perform advanced reasoning tasks. This representation, which preserves layout and organizational information, allows the model to identify relationships between different document elements – such as headings, paragraphs, tables, and lists – and understand the document’s hierarchical structure. Consequently, DeepRead can accurately locate specific information, answer complex queries requiring cross-document synthesis, and perform tasks like form understanding and data extraction with significantly improved accuracy compared to models operating solely on raw text. This facilitates efficient processing of documents with complex layouts and varied content types, maximizing the retrieval of valuable knowledge contained within.
The Future of Document AI: Towards Genuine Comprehension
DeepRead signifies a considerable advancement in the field of Document AI, moving beyond simple information extraction towards genuine comprehension. Current systems often struggle with the nuances of complex documents, treating them as mere collections of text rather than structured arguments or narratives. This new approach, however, aims to replicate human-like reading abilities, allowing the AI to not just identify facts, but to synthesize information, draw inferences, and reason about the content presented. By incorporating a deeper understanding of context and relationships within the document, DeepRead promises to unlock the full potential of long-form content, enabling applications that require sophisticated analysis and knowledge discovery – from legal document review and scientific research to financial analysis and competitive intelligence. This capability marks a critical step towards creating AI systems that can truly collaborate with humans in knowledge-intensive tasks.
Traditional Document AI often suffers from “structural blindness,” meaning it struggles to interpret the relationships between different sections and elements within complex, organized documents – effectively treating a report as a mere collection of isolated text blocks. DeepRead addresses this by incorporating mechanisms that explicitly model document structure, allowing the system to understand how headings, paragraphs, tables, and figures relate to one another. This unlocks the potential for truly comprehending long-form content, as the AI can now trace arguments, synthesize information across multiple sections, and answer questions requiring an understanding of the document’s overall organization – moving beyond simple keyword matching to genuine knowledge extraction and reasoning.
Continued development in Document AI centers on fortifying these emerging methods against real-world complexities and expanding their capacity to process vast datasets. Current research prioritizes enhancing robustness, allowing systems to reliably extract information even from poorly formatted or ambiguous documents, and improving scalability to handle the exponential growth of digital information. This involves exploring techniques like distributed processing and advanced model compression, alongside innovations in few-shot learning to minimize the need for extensive labeled data. Ultimately, these advancements aim to unlock the potential for Document AI to address increasingly sophisticated knowledge-intensive tasks – from automated legal discovery and scientific literature review to complex financial analysis and personalized healthcare – transforming information processing from simple extraction to genuine understanding and reasoning.
The development of Document AI capable of deep understanding signals a forthcoming revolution in information access. Currently, retrieving knowledge from complex documents often relies on brittle keyword searches or manual review; however, systems that can truly reason over content promise a shift toward intuitive, semantic retrieval. This means users will no longer need to formulate precise queries, but rather pose questions in natural language, receiving concise, relevant answers extracted from vast repositories of organized information. Such advancements extend beyond simple question-answering, fostering capabilities like automated summarization, intelligent report generation, and proactive knowledge discovery – ultimately transforming how individuals and organizations interact with, and benefit from, the ever-growing volume of documented knowledge.
The pursuit of increasingly complex architectures often obscures the fundamental goal: effective information retrieval. DeepRead, with its coordinate-based navigation, embodies a refreshing pragmatism. It acknowledges that structure, when intelligently utilized, can dramatically simplify the process of long-document reasoning. One might observe, as Linus Torvalds famously stated, “Most good programmers do programming as a hobby, and then they get paid to do paperwork.” This framework elegantly minimizes the ‘paperwork’ – the extraneous processing – by focusing on a clear, hierarchical understanding of the document itself. The agent isn’t lost in a sea of tokens; it navigates with purpose, a testament to the power of well-defined structure over brute-force computation.
Further Refinements
The pursuit of agentic reasoning over extended documents reveals, predictably, the intractability of true comprehension. DeepRead offers a pragmatic reduction – a coordinate system imposed upon chaos – and demonstrates improvement. However, it does not solve the problem of information retrieval, merely shifts the locus of difficulty. Future work must confront the inherent ambiguity within document structure itself; headings and sections are human constructs, rarely mirroring the underlying semantic relationships.
A useful direction lies not in increasingly elaborate navigation – more coordinates rarely clarify a clouded map – but in the development of agents capable of selective forgetting. The current paradigm favors accumulation of context; perhaps true intelligence demands ruthless pruning. Efficiency gains will be marginal without a fundamental shift toward minimizing, rather than maximizing, the information considered relevant.
Ultimately, the enduring question remains: can an agent truly ‘understand’ a document, or merely construct a plausible simulacrum? The answer, it seems, is less a matter of algorithmic refinement and more a reckoning with the limits of representation itself. The most promising path may not be to build better agents, but to design systems that acknowledge-and even embrace-their own inherent incompleteness.
Original article: https://arxiv.org/pdf/2602.05014.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- eFootball 2026 “Countdown to 1 Billion Downloads” Campaign arrives with new Epics and player packs
- Gold Rate Forecast
2026-02-08 07:24