Author: Denis Avetisyan
A new workflow automatically extracts material properties from scientific literature, offering a powerful tool for more accurate and efficient cultural heritage conservation.
This review details an agentic framework leveraging large language models to build a structured database of mechanical constitutive models for materials informatics in cultural heritage.
Despite increasing reliance on data-driven approaches in cultural heritage conservation, critical mechanical properties remain trapped within decades of unstructured scientific literature. This work, ‘Automated Extraction of Mechanical Constitutive Models from Scientific Literature using Large Language Models: Applications in Cultural Heritage Conservation’, addresses this challenge by presenting an automated framework leveraging Large Language Models to extract [latex]\text{constitutive equations}[/latex] and calibrated parameters from research papers. The system successfully constructed a structured database from over 2,000 documents, achieving 80.4% extraction precision and reducing manual curation time by approximately 90%. Will this approach unlock a new era of predictive maintenance and facilitate the creation of comprehensive “Digital Material Twins” for built heritage?
The Foundations of Predictive Modeling for Heritage Materials
The ability to accurately predict how a heritage structure will respond to external forces hinges on the use of precise constitutive models. These models mathematically define a material’s intrinsic behavior under stress – encompassing elasticity, plasticity, creep, and even failure. Essentially, they translate applied force into resulting deformation or strain, allowing engineers to simulate structural performance. For instance, a model might predict how much a wooden beam will deflect under a given load, or how a stone arch will distribute weight. The fidelity of these simulations is directly proportional to the accuracy of the constitutive model employed; even slight inaccuracies can lead to significant errors in predicting long-term stability or identifying potential failure points. Therefore, developing and validating robust constitutive models is paramount to effective preservation and informed restoration strategies.
The inherent complexity of heritage materials presents a formidable challenge to predictive modeling. Unlike manufactured materials with consistent composition, objects like ancient ceramics, historic wood, or aged stone exhibit substantial variability even within a single artifact. Decades, or even centuries, of environmental exposure and biological activity introduce micro-cracking, compositional changes, and altered mechanical properties. Traditional constitutive models, developed for homogenous, modern materials, often fail to capture this intricate internal heterogeneity. Successfully simulating the behavior of these objects, therefore, demands a nuanced understanding of how age and past conditions influence their response to stress, necessitating advanced characterization techniques and modeling approaches that account for material anisotropy, damage accumulation, and the influence of degradation products.
The effective preservation of heritage materials is increasingly reliant on computational modeling, yet a significant bottleneck exists in translating scientific understanding into actionable data. Current methods for extracting constitutive models – the mathematical descriptions of how a material will behave under stress – from the vast and often fragmented body of scientific literature prove remarkably unreliable. Research findings are dispersed across diverse journals, presented with varying levels of detail, and frequently lack the standardized formats necessary for direct computational input. This necessitates laborious manual extraction and interpretation, introducing potential for error and limiting the scalability of modeling efforts. Consequently, restorers and conservators often lack the precise material data required to accurately predict the long-term effects of interventions, hindering evidence-based decision-making and potentially compromising the structural integrity of valuable artifacts and historical structures.
An Intelligent Framework for Automated Model Extraction
The proposed Agentic Framework leverages a two-tiered agent system to automate model extraction from documents. The initial stage employs a ‘Gatekeeper Agent’ responsible for rapidly assessing document relevance based on pre-defined criteria, thereby reducing the processing load on subsequent stages. Documents passing this initial filter are then forwarded to the ‘Analyst Agent’, which performs a more detailed, fine-grained analysis to identify and extract specific models, equations, and associated parameters. This division of labor optimizes the extraction process by prioritizing speed for large volumes of documents while maintaining accuracy in the detailed analysis phase.
The Analyst Agent utilizes Contextual Fusion, a process involving the integration of information from multiple sources within a document to resolve ambiguity and accurately identify relevant equations and parameters. This goes beyond simple keyword matching; the agent considers surrounding text, section headings, and the overall document structure to determine the semantic meaning of each element. Specifically, the agent analyzes relationships between variables, units of measurement, and the context in which [latex]y = mx + b[/latex] or other equations appear, differentiating between definitions, applications, and incidental mentions. This contextual understanding minimizes false positives and ensures that only genuinely relevant data is extracted for standardized output.
The application of a JSON Schema is central to ensuring data integrity and interoperability within the automated extraction pipeline. This schema defines a strict contract for the structure and data types of extracted information, including identified equations and associated parameters. By validating all outputs against this predefined schema, inconsistencies and errors are minimized, guaranteeing that each extracted data point adheres to a uniform format. This standardization is critical for reliable downstream analysis, enabling efficient data integration with existing systems and facilitating automated processing without requiring manual data cleaning or transformation. The schema explicitly defines required fields, allowable data types (e.g., numerical values, strings, arrays), and permissible ranges, thereby establishing a consistent and predictable data structure for all extracted results.
Constructing a Comprehensive Database of Heritage Material Properties
The Data Ingestion Module utilizes PDF parsing to automate the upload and initial processing of scientific literature relevant to material properties. This module extracts text and tabular data from PDF documents, converting it into a structured format suitable for subsequent analysis. Automation minimizes manual data entry, increasing throughput and reducing the potential for human error. The system is designed to handle a large volume of documents, enabling the creation of a comprehensive database of heritage materials data. Extracted data includes material compositions, mechanical properties, and environmental degradation rates as reported in the source literature.
The Analyst Agent mitigates the problem of ‘Mathematical Noise’ – the presence of extraneous or irrelevant equations within source literature – through a targeted filtering process. This agent doesn’t simply extract all equations, but rather employs algorithms to identify and prioritize those representing key constitutive relationships – mathematical expressions defining the behavior of materials. This selective approach focuses on equations that directly link stress, strain, and other relevant physical quantities, ignoring those related to experimental setup, data analysis, or unrelated phenomena. The agent’s functionality ensures that the database contains only the constitutive models essential for heritage conservation, improving data quality and reducing computational overhead.
The developed framework processed over 2,000 scientific papers to yield a database of 185 distinct constitutive model instances, alongside a total of 450+ calibrated parameters. Evaluation of the data extraction process demonstrated a precision rate of 80.4% in correctly identifying and isolating relevant data pertaining to heritage conservation materials. This indicates the system’s ability to accurately parse and categorize complex scientific literature, generating a substantial and reliable dataset for materials modeling and preservation efforts.
![The automated data ingestion interface extracts information from uploaded PDFs, automatically identifying the constitutive model, displaying the corresponding equation [latex] ext{equation}[/latex], and populating fitted parameters for user verification.](https://arxiv.org/html/2602.16551v1/figures/discovery_1.png)
Unlocking New Possibilities Through Semantic Access and Knowledge Retrieval
The ability to pinpoint precise material characteristics or model parameters through semantic knowledge retrieval represents a substantial advancement for researchers and conservationists. This system moves beyond simple keyword searches, instead understanding the meaning behind queries to deliver highly relevant results from a complex database. Consequently, projects requiring detailed material data – such as the reconstruction of historical structures or the development of novel materials – experience significant acceleration. Instead of manually sifting through countless publications, users can efficiently access the specific information needed, fostering innovation and reducing the time required for both research and the meticulous work of heritage restoration.
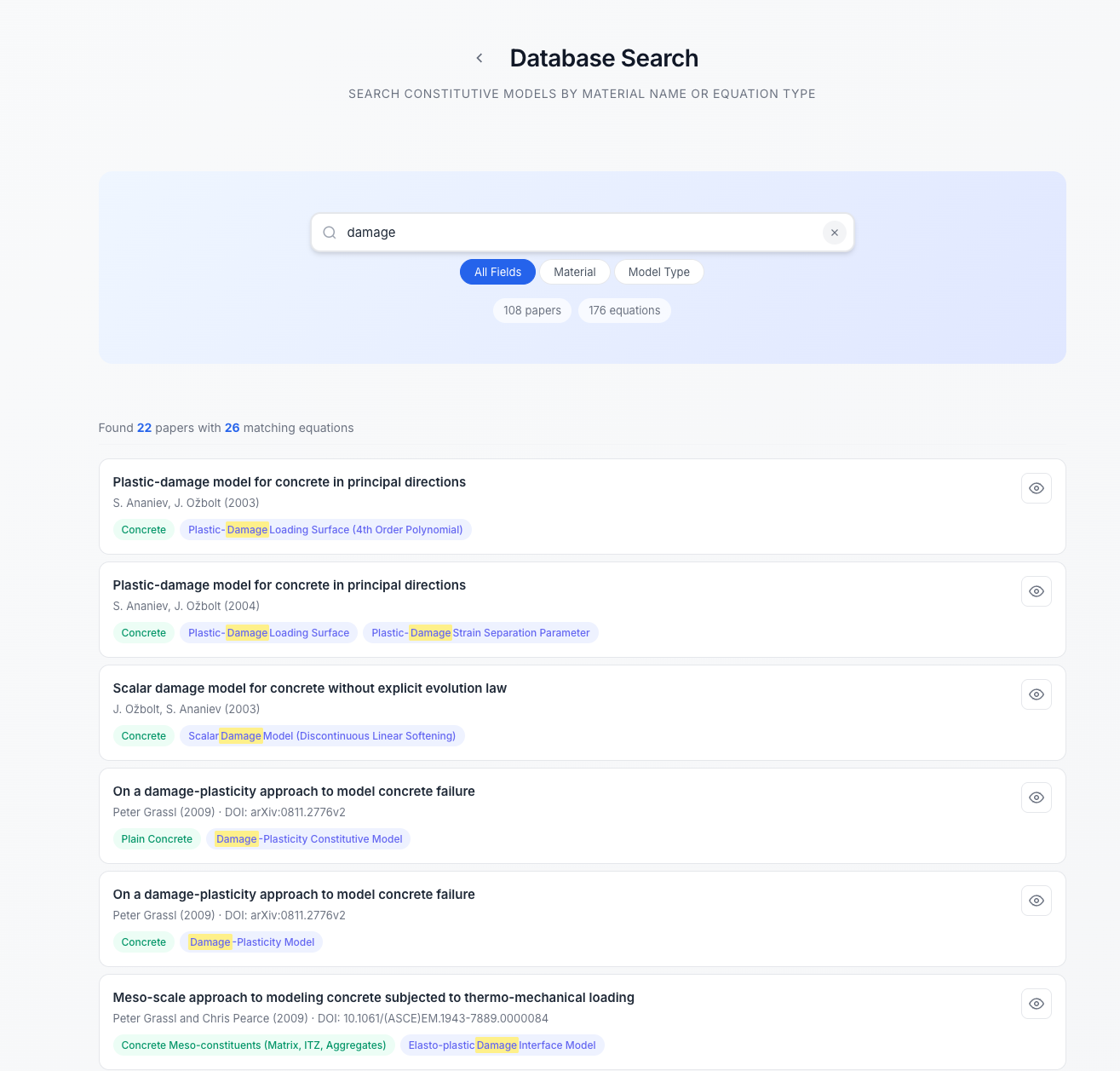
A significant challenge in heritage conservation stems from the dispersed and often unstructured nature of material property data necessary for accurate restoration and predictive modeling. This system directly addresses this gap by automatically extracting and structuring constitutive models – the mathematical relationships defining how materials behave under stress – from a corpus of 113 core research papers. By converting unstructured text into a usable, organized format, the system provides conservation scientists with rapid access to crucial data previously locked within academic literature. This automated process not only streamlines workflows but also enables more informed decision-making regarding material selection, repair strategies, and long-term preservation efforts for culturally significant structures and artifacts.
The implementation of automated data extraction demonstrably streamlines heritage conservation research. A recent evaluation revealed a remarkable 90% reduction in manual effort typically required for comprehensive literature review. This efficiency is achieved without compromising accuracy; the system attained an F1-Score of 81.9%, indicating a strong balance between precision and recall in identifying relevant constitutive models. Further validating its performance, the Area Under the Curve (AUC) reached 0.782, demonstrating the system’s robust ability to discriminate between pertinent and irrelevant information within the analyzed corpus of 113 core papers. This substantial improvement in both speed and reliability positions automated semantic access as a pivotal advancement in the field, enabling researchers to focus on analysis and interpretation rather than exhaustive data collection.
![Using a Jeffreys-type Viscoelastic model, our agent successfully extracts and structures fragmented constitutive laws from a complex PDF into a verified JSON format with correct symbolic grounding ([latex]\xi \rightarrow[/latex] structural kinetics) and physically plausible scale resolution.](https://arxiv.org/html/2602.16551v1/x2.png)
The presented work emphasizes a holistic approach to knowledge representation, mirroring the principle that structure dictates behavior. Extracting mechanical constitutive models from diverse scientific literature and integrating them into a structured database isn’t merely about data aggregation; it’s about establishing a coherent system. As Brian Kernighan aptly stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This resonates with the need for clarity and simplicity in constructing the knowledge base; an overly complex system, like convoluted code, becomes intractable. The Agentic Framework, central to this research, benefits from this principle, ensuring the extracted models function as a cohesive whole rather than isolated components.
The Road Ahead
The automation of knowledge extraction, as demonstrated by this work, feels less like a solution and more like a refinement of an old problem: the inherent messiness of translating observation into predictive structure. The current approach, while promising, rests on the assumption that constitutive models are consistently, and explicitly, articulated in the primary literature. This is, to put it mildly, optimistic. A truly robust system will need to account for implicit knowledge, experimental nuance, and the frustratingly common practice of researchers burying critical details within narrative prose.
The pursuit of digital twins for cultural heritage-accurate, living representations of fragile artifacts-demands a shift in focus. The emphasis should move beyond simply finding models to validating them. Any automated pipeline will inevitably generate errors, and the consequences of those errors-a miscalculated stress limit, a flawed restoration plan-are far more significant when dealing with irreplaceable objects. An agentic framework offers a potential path forward, but only if the agents are equipped with a healthy dose of skepticism and a rigorous methodology for cross-validation.
Ultimately, the elegance of any system will be judged not by its cleverness, but by its resilience. A fragile solution, built on brittle assumptions and lacking internal consistency, will inevitably fail. The true challenge lies not in automating the extraction of information, but in building a system that can gracefully handle uncertainty, acknowledge its own limitations, and adapt to the inherent complexity of the world it seeks to model.
Original article: https://arxiv.org/pdf/2602.16551.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
2026-02-19 17:47