Author: Denis Avetisyan
Researchers have developed a novel framework that enables robots to manipulate unfamiliar tools and complete tasks without task-specific training data.
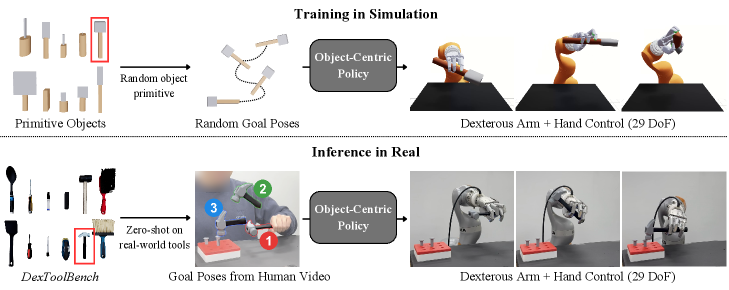
SimToolReal learns a general policy for dexterous manipulation by framing tool use as object-centric control through goal poses, achieving zero-shot transfer on the DexToolBench.
Despite advances in robotic manipulation, generalizing to novel tools and tasks remains a significant challenge. This paper introduces ‘SimToolReal: An Object-Centric Policy for Zero-Shot Dexterous Tool Manipulation’, a framework that learns a universal policy by framing tool use as controlling an object to reach a sequence of goal poses. This approach enables zero-shot transfer to new tools without object or task-specific training, achieving performance comparable to specialist policies. Could this object-centric paradigm unlock truly general-purpose robotic dexterity, allowing robots to seamlessly interact with the diverse tools of our everyday world?
The Challenge of Dexterous Manipulation: A Systems Perspective
The seamless interaction humans achieve with tools stems from an ingrained understanding of physics and an ability to rapidly adapt to unforeseen circumstances; replicating this in robotics proves remarkably difficult. Real-world environments introduce a cascade of complexities – unpredictable lighting, variations in object texture, and the ever-present challenge of maintaining stable grasps amidst external disturbances. These dynamic interactions demand not only precise motor control, but also a robust system capable of sensing, interpreting, and responding to constantly changing conditions. Unlike the controlled settings of a laboratory, everyday tasks present a near-infinite array of possible scenarios, forcing robotic systems to contend with uncertainties that would be trivial for a human operator. Consequently, achieving truly dexterous manipulation necessitates overcoming these inherent challenges in dynamic, unpredictable environments – a problem that continues to push the boundaries of robotics research.
Conventional robotic manipulation systems often falter when confronted with even slight variations in objects or tasks. These systems typically rely on meticulously pre-programmed instructions tailored to specific scenarios – a process demanding significant time and expertise for each new interaction. This approach creates a rigidity that hinders adaptation; a robot proficient at grasping a red block may struggle with a blue one, or fail entirely when asked to perform a subtly different action. The limitations stem from a dependence on precise, explicitly defined parameters, rather than an ability to infer general principles of manipulation and apply them flexibly across a range of circumstances. Consequently, expanding the capabilities of robotic systems requires moving beyond task-specific programming toward solutions that emphasize learning, inference, and robust generalization.
Achieving truly human-like dexterity in robots necessitates a confluence of capabilities extending beyond mere movement precision. Systems must not only execute fine motor control, but also possess the capacity for high-level reasoning about what objects are and what actions they enable – a concept known as affordance perception. This means a robot needs to ‘understand’ that a hammer’s shape lends itself to pounding, a doorknob to turning, and a mug to grasping by its handle, rather than simply registering shapes and sizes. Successfully integrating precise control with this understanding of object affordances allows a robot to dynamically adapt its grasp and manipulation strategies, generalizing beyond pre-programmed routines and operating effectively in unpredictable real-world scenarios. Such integration represents a crucial step toward robots capable of seamlessly interacting with, and assisting humans in, complex and varied environments.
Object-Centric Control: Shifting the Paradigm
Traditional robot manipulation often relies on specifying desired joint angles to achieve a task. An object-centric representation instead defines the manipulation task in terms of the object’s six-dimensional pose – position (x, y, z) and orientation (roll, pitch, yaw) – and its desired trajectory over time. This fundamentally shifts the control paradigm; rather than directly commanding robot joints, the system learns to control the object’s movement in Cartesian space. This decoupling of control from robot kinematics allows the system to treat the robot as a means to an end – achieving the desired object pose – rather than requiring precise coordination of joint movements. Consequently, policies learned within this framework are inherently more transferable, as they are defined relative to the object and independent of specific robot morphology.
Decoupling robot kinematics from the task objective in object-centric control significantly simplifies the learning process. Traditional robot learning methods often require the robot to learn a complex mapping from task goals to specific joint angles, which is highly sensitive to robot morphology and requires retraining for each new robot. By instead learning policies that directly control object pose and trajectory, the system abstracts away the intricacies of robot kinematics. This abstraction reduces the dimensionality of the learning problem and allows a single learned policy to be transferred and adapted to different robot configurations with minimal additional training, improving generalization capabilities and reducing the need for robot-specific tuning.
Direct object control enables adaptation to variations in robot morphology and environmental conditions by decoupling the learned policy from specific robot kinematics. Traditional robot control methods require re-tuning policies when the robot’s physical characteristics or the surrounding environment change. However, policies trained to directly manipulate an object’s pose, independent of the robot’s joint configurations, can generalize across different robotic platforms and scenarios. This is achieved by focusing on the desired object trajectory and allowing the robot’s internal control systems to determine the necessary joint movements to achieve that trajectory. Consequently, the system requires minimal retraining when faced with alterations in robot arm length, link mass, or external disturbances, leading to increased robustness and operational efficiency.
Bridging the Reality Gap: Simulation and Robustness
Directly training reinforcement learning policies in real-world scenarios presents significant challenges related to both safety and data acquisition. Operating robotic systems in uncontrolled physical environments carries inherent risks of damage to the robot, the environment, or personnel. Furthermore, obtaining sufficient labeled data for effective training is often expensive, time-consuming, and potentially dangerous, particularly for tasks involving rare events or complex maneuvers. Consequently, simulation-based training has become a critical methodology, allowing for the safe and efficient generation of large datasets and the exploration of a wide range of scenarios without the constraints and risks associated with real-world experimentation. This approach enables the initial development and refinement of policies before deployment in physical systems.
Sim-to-Real transfer, the process of deploying policies learned in simulation to real-world applications, frequently encounters performance degradation due to the inherent differences between the simulated and real environments. These discrepancies can manifest in various forms, including variations in lighting conditions, textures, friction coefficients, sensor noise, and unmodeled dynamics. Consequently, a policy that performs optimally within the controlled parameters of a simulation may exhibit reduced effectiveness or outright failure when deployed in a real-world setting. This gap in performance necessitates techniques to improve the robustness and generalization capabilities of learned policies, enabling them to effectively adapt to the complexities of the real world.
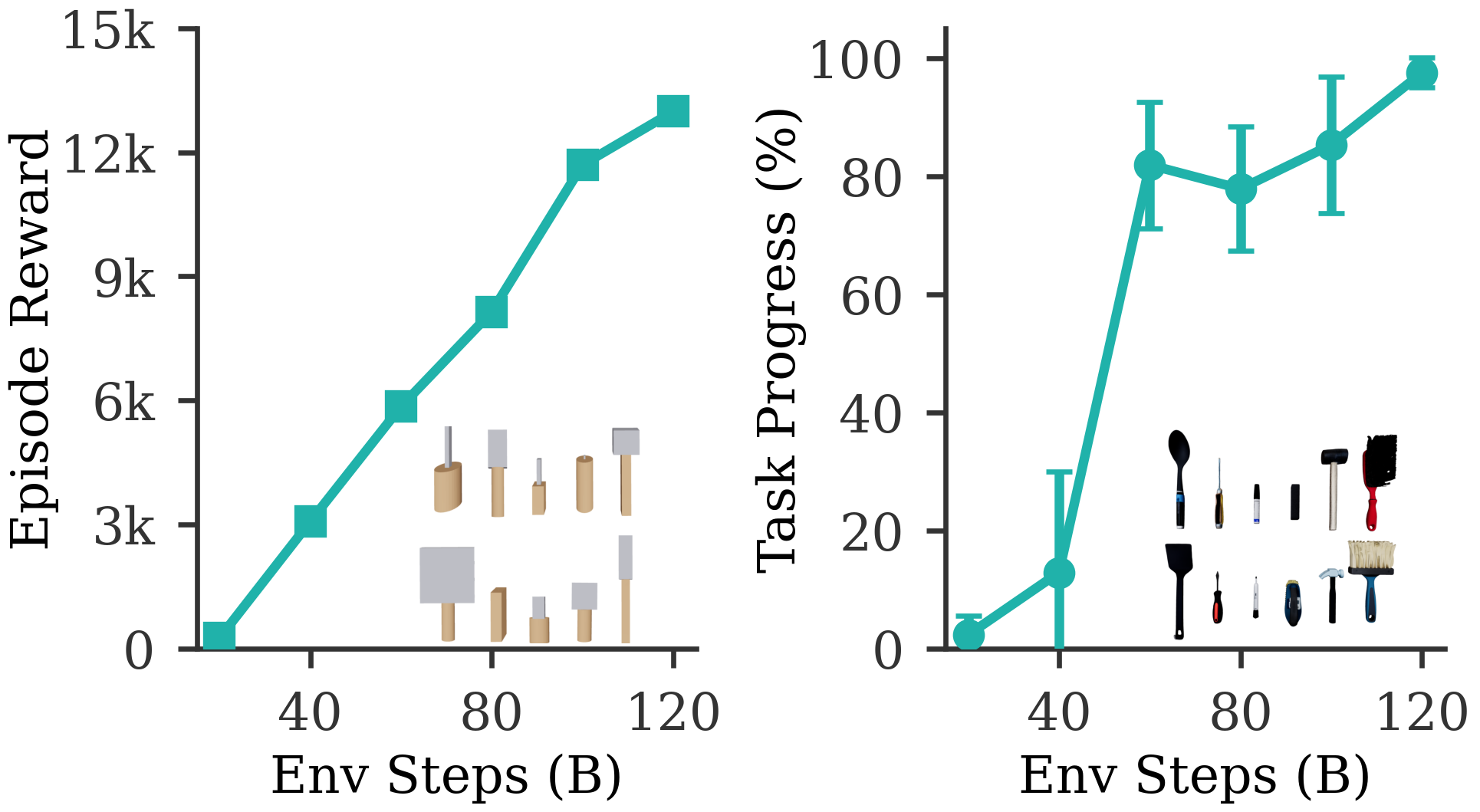
Procedural generation addresses the Sim-to-Real gap by creating a wide variety of training scenarios and object instances, thereby increasing the generalization capability of learned policies. This technique programmatically generates diverse environments, altering parameters such as lighting, textures, object arrangements, and physical properties. By training agents across numerous, randomly varied simulations, the resulting policies become less sensitive to the specific characteristics of any single simulated or real-world environment. Increased diversity forces the agent to learn more robust features and strategies, diminishing the impact of discrepancies between the simulation and the real world, and improving performance in unseen conditions. This approach effectively expands the training distribution to encompass a broader range of potential real-world scenarios, leading to more reliable and adaptable robotic systems.
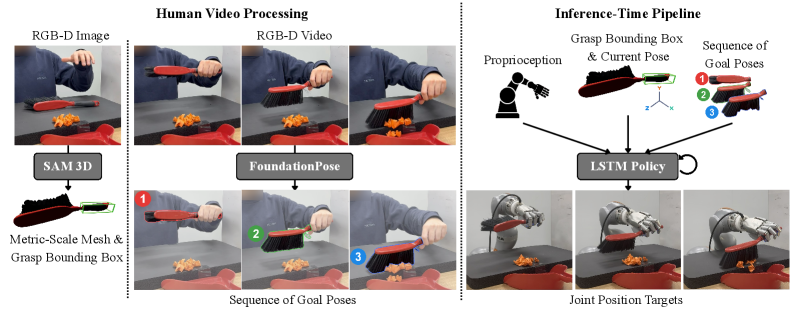
Accurate object pose estimation is fundamental for robotic manipulation and interaction, and FoundationPose and SAM3D represent key advancements in this area. FoundationPose provides a robust and generalizable framework for 6D object pose estimation, leveraging large-scale datasets and novel network architectures to achieve state-of-the-art performance. SAM3D, Segment Anything Model in 3D, extends this capability by enabling the segmentation and pose estimation of objects in 3D scenes, even with limited training data. Critically, both systems are designed to function effectively across both simulated and real-world data, facilitating the transfer of learned policies from simulation to physical deployment. Their ability to reliably determine an object’s position and orientation – including its [latex]x, y, z[/latex] coordinates and roll, pitch, and yaw angles – is essential for successful grasping, manipulation, and interaction tasks in diverse environments.
From Perception to Action: Building a Unified System
Kinematic retargeting enables the execution of planned motions – derived from human demonstrations or simulation – by a robot, despite differences in morphology. This process relies on accurate 3D reconstruction of both the demonstrated motion and the robot’s physical structure. The HaMeR (Hierarchical Matching for Robot) framework facilitates correspondence between the demonstrator and the robot, while Iterative Closest Point (ICP) registration refines the pose estimation. Specifically, ICP minimizes the distance between point clouds to align the robot’s end-effector with the desired trajectory, effectively translating the demonstrated motion to the robot’s kinematic configuration. This allows for the transfer of complex manipulation strategies without requiring the robot to relearn fundamental movements.
Goal-Conditioned Reinforcement Learning (GCRL) facilitates the development of robotic policies focused on achieving defined objectives during object manipulation. Unlike traditional RL which optimizes for cumulative reward, GCRL frames the learning problem around reaching specific goal states, allowing the robot to learn a broader range of behaviors applicable to varying starting conditions. The incorporation of an Asymmetric Critic, a modification to the standard Actor-Critic architecture, further enhances learning efficiency. This approach utilizes separate critic networks for evaluating actions and goals, enabling more accurate value estimation and accelerating the learning process by reducing variance in the policy gradient updates. By decoupling these evaluations, the Asymmetric Critic allows for more effective exploration and faster convergence towards optimal manipulation strategies.
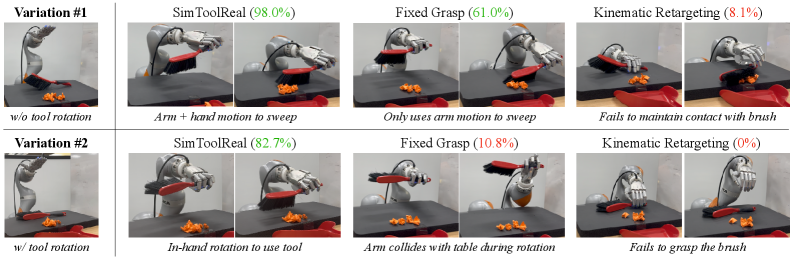
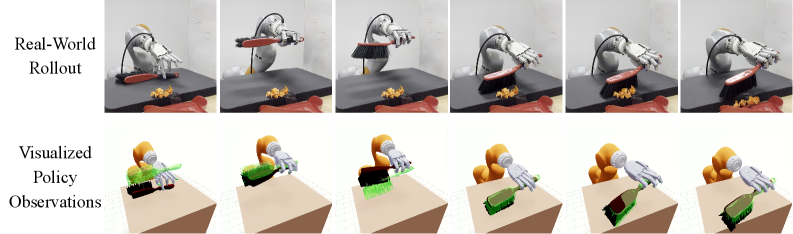
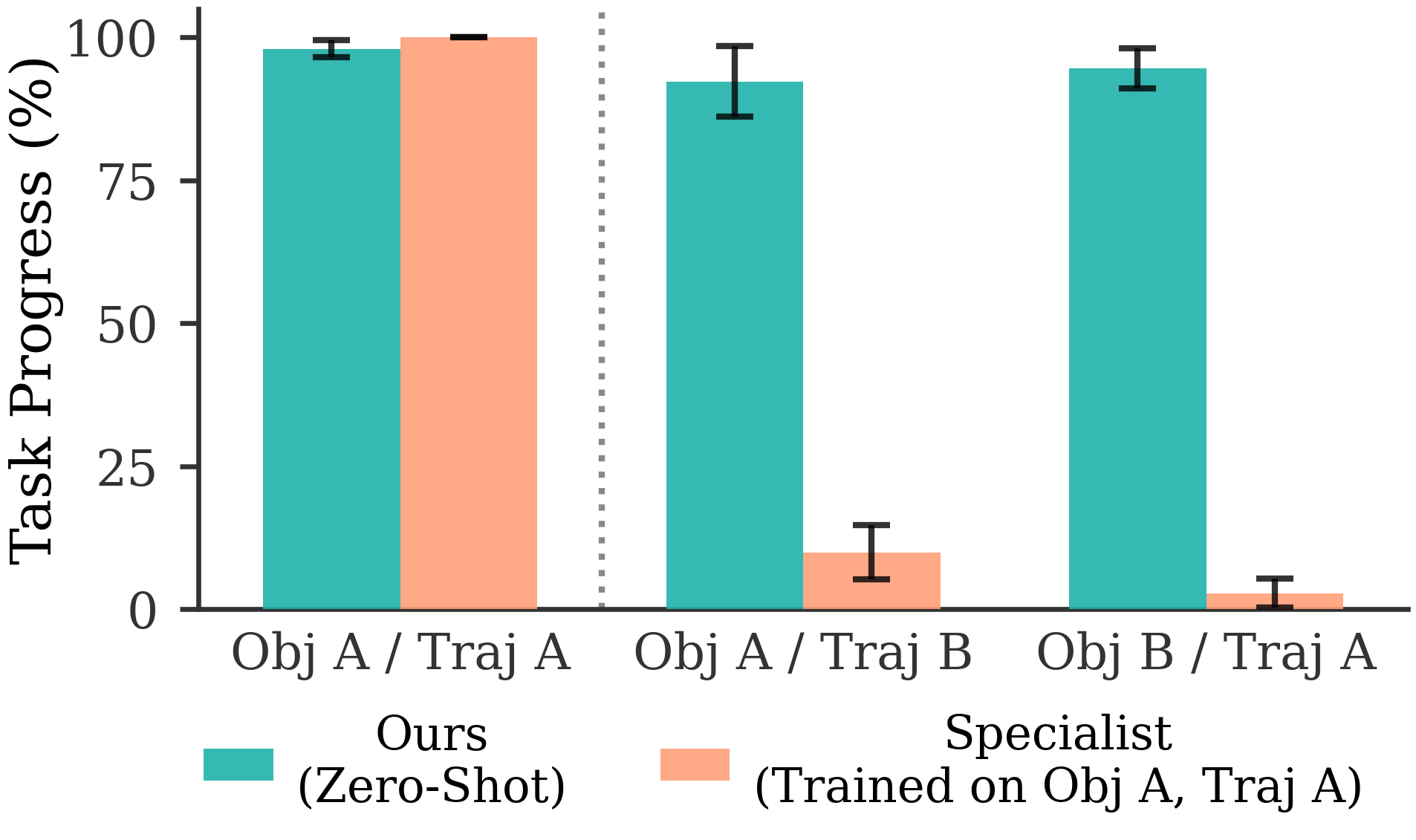
SimToolReal demonstrates the successful integration of kinematic retargeting, goal-conditioned reinforcement learning with asymmetric critics, and accurate 3D reconstruction to enable zero-shot dexterous tool manipulation. This system achieves performance, as measured by Task Progress, that is comparable to specialist policies specifically trained for individual objects or task trajectories. Crucially, SimToolReal accomplishes this capability without requiring task-specific training data, allowing for generalization across a diverse range of manipulation tasks and objects. Evaluations confirm the system’s ability to perform zero-shot transfer, indicating a robust approach to robotic control.
Specialist policies in robotic manipulation achieve heightened performance by explicitly training separate policies for each object or desired task trajectory. This approach necessitates a significant investment in data collection and training time as each new object or trajectory requires a dedicated policy. Conversely, SimToolReal demonstrates competitive performance with these specialist policies without requiring task-specific training; it generalizes across objects and trajectories by learning a unified policy capable of adapting to novel scenarios. This generalization capability is achieved through the integrated framework of kinematic retargeting, goal-conditioned reinforcement learning, and the Asymmetric Critic algorithm, reducing the need for extensive, specialized datasets.
The Future of Adaptive Robotic Manipulation: A Systems Perspective
A novel robotic manipulation strategy centers on understanding the world through distinct objects rather than raw sensory data, enabling a robot to learn complex tasks with greater efficiency. This “object-centric” approach, coupled with training in realistic simulations before deployment in the real world-a technique known as simulation-to-real transfer-represents a substantial advance in robotic autonomy. By learning to predict how objects will behave and interact, the system can generalize its skills to novel situations and previously unseen objects within unstructured environments – spaces lacking precise organization or predictable layouts. This methodology moves beyond pre-programmed routines, allowing robots to adapt and problem-solve during manipulation, ultimately bringing them closer to performing complex tasks independently in dynamic, real-world settings.
The development of robotic systems capable of generalizing manipulation skills across varied objects and tasks unlocks considerable potential across multiple sectors. In manufacturing, such adaptability promises more flexible assembly lines capable of handling a wider range of products without costly re-tooling. Healthcare stands to benefit from robots assisting with delicate procedures or delivering personalized care, even with unpredictable environments and diverse patient needs. Perhaps most visibly, advancements in generalized robotic manipulation could revolutionize domestic service, enabling robots to perform everyday tasks – from preparing meals to tidying spaces – with the same dexterity and problem-solving skills humans employ, fundamentally altering how people interact with their living spaces and freeing up valuable time.
Despite demonstrating successful robotic manipulation, the system currently encounters limitations in practical application, as evidenced by performance metrics collected during testing. Specifically, the robot exhibits a 34.5% object drop rate, indicating a need for improved grasp stability and force control. Furthermore, a 3.6% grasp failure rate suggests challenges in initial object acquisition, while an 18.2% incomplete in-hand rotation rate points to difficulties in precise manipulation and re-orientation. These figures collectively underscore key areas for ongoing research and development, particularly regarding the refinement of learning algorithms, enhanced sensor integration, and the implementation of more robust control strategies to achieve reliable and adaptable manipulation in real-world scenarios.
Ongoing investigation centers on refining the robotic learning process to enhance both its reliability and speed. Current efforts aren’t solely focused on simply teaching robots to grasp, but also on enabling them to understand what an object allows – its ‘affordances’. This involves developing new computational methods that allow robots to predict how an object will respond to different actions, such as whether it can be poured, stacked, or cut. By moving beyond basic object recognition towards a deeper comprehension of object functionality, researchers aim to create systems capable of tackling unforeseen challenges and adapting to novel situations with greater dexterity and efficiency, ultimately leading to more versatile and dependable robotic assistants.
The development of adaptable robotic manipulation systems promises a future where robots move beyond structured factory settings and become truly integrated into everyday human life. This research demonstrates a pathway towards robots capable of assisting with a diverse array of tasks, from simple household chores to complex assembly procedures, all within the unstructured and dynamic environments people inhabit. By enabling robots to learn and generalize their manipulation skills across various objects and situations, this work envisions a collaborative future where robotic assistance enhances productivity, improves quality of life, and provides support in areas ranging from healthcare and elder care to manufacturing and disaster relief. Ultimately, the goal is to create robots that are not merely tools, but reliable and intuitive partners capable of seamlessly operating alongside humans in a shared world.
The presented SimToolReal framework embodies a principle of elegant design through its object-centric approach. By decoupling the policy from specific tool kinematics and focusing on achieving goal poses, the system demonstrates a scalable solution to dexterous manipulation. This aligns with the understanding that simplicity scales, cleverness does not; the abstraction of tool control into object-centric goals allows for zero-shot transfer, minimizing the need for task-specific engineering. As Grace Hopper famously stated, “It’s easier to ask forgiveness than it is to get permission.” This resonates with the framework’s bold approach of abstracting away complexities, prioritizing adaptability and rapid deployment over meticulously detailed, rigid solutions. The system’s ability to generalize to new tools and tasks highlights the power of focusing on fundamental principles rather than intricate, tool-dependent implementations-a testament to architecture that remains invisible until challenged by novel scenarios.
What’s Next?
The elegance of SimToolReal lies in its reduction of tool manipulation to a sequence of poses – a commendable shift toward treating the tool as an extension of the agent’s intent, rather than an entity demanding bespoke control. However, this very simplification reveals the inherent tension in such approaches. A policy optimized for pose control will, inevitably, encounter novel failure modes arising from the physics it necessarily abstracts. The system’s behavior over time will be defined not only by the achieved poses, but by the unforeseen consequences of achieving them-the subtle instabilities, the accumulated errors, the emergent fragility.
Future work must acknowledge this principle: optimization creates new tension points. Simply increasing the complexity of the object-centric representation – adding more features, more layers of abstraction – will not resolve this. Instead, the focus should shift toward understanding how the system fails, and building mechanisms for graceful degradation. This demands a move beyond purely data-driven approaches, toward incorporating principles of mechanical stability and embodied intelligence-a deeper consideration of the interaction between structure and behavior.
The pursuit of zero-shot transfer is laudable, but perhaps misplaced. True generality does not lie in the ability to adapt to any tool, but in the ability to learn how to learn-to rapidly adapt to the unexpected, to diagnose and correct errors, and to build robust strategies in the face of uncertainty. The architecture of the system must reflect this capacity for continual learning, not merely the accumulation of pre-trained skills.
Original article: https://arxiv.org/pdf/2602.16863.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Gold Rate Forecast
2026-02-21 13:38