Author: Denis Avetisyan
Researchers have developed a new system that uses knowledge graphs and large language models to help developers explore and comprehend complex, multi-repository software projects.
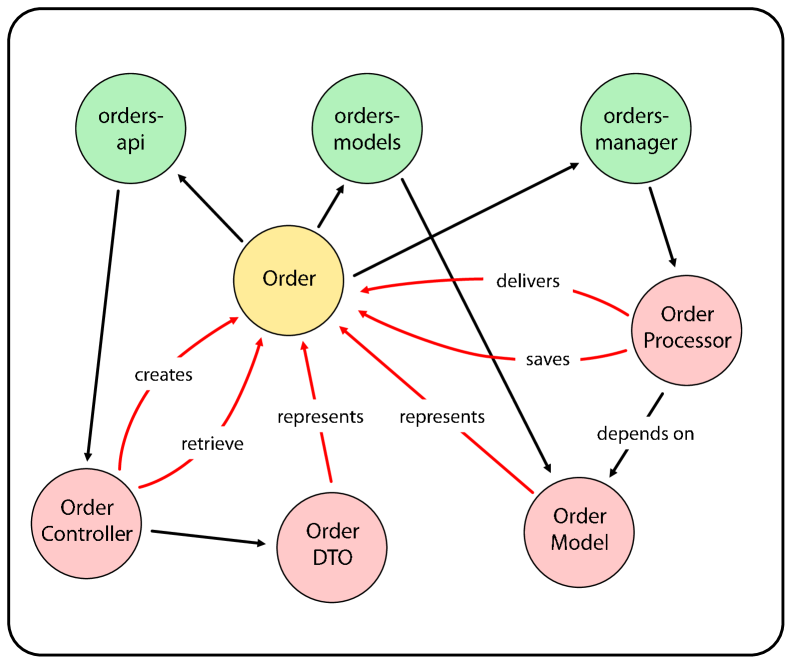
LogicLens employs a semantic code graph and a ReAct agent powered by GraphRAG to facilitate intelligent code exploration.
Understanding increasingly complex software systems presents a fundamental challenge, particularly when code is distributed across numerous repositories. This paper introduces LogicLens: Leveraging Semantic Code Graph to explore Multi Repository large systems, a reactive conversational agent designed to aid developers in navigating these intricate landscapes. LogicLens constructs a semantic multi-repository graph-built from code analysis and enriched with large language models-that captures both structural and functional aspects of the system. By enabling natural language interaction with this graph, LogicLens facilitates tasks like impact analysis and symptom-based debugging; but can this approach unlock even deeper insights into software behavior and accelerate the development process?
The Inevitable Complexity of Modern Systems
Contemporary software development frequently results in systems of immense intricacy, presenting significant challenges to those tasked with their upkeep and evolution. This escalating complexity isn’t merely a matter of increased lines of code; it stems from deeply interwoven dependencies, distributed architectures, and the rapid integration of third-party libraries. Consequently, developers often struggle to grasp the full scope of a system’s behavior, making even minor modifications a potentially risky undertaking. The sheer cognitive load required to navigate these intricate networks can lead to errors, extended debugging cycles, and ultimately, a substantial increase in the cost of software maintenance. This trend underscores the need for innovative approaches to code comprehension that move beyond simple textual analysis and embrace a deeper, semantic understanding of software structure and function.
While conventional code search excels at locating exact text matches within a codebase, it frequently struggles to grasp the meaning behind the code. These tools operate on a purely syntactic level, identifying strings of characters but failing to discern how different code segments relate to one another functionally. Consequently, a developer might find all instances of a variable name, but not readily understand its purpose, its dependencies on other parts of the system, or the broader logic it supports. This limitation proves particularly acute in large, intricate projects where understanding these relationships is crucial for effective debugging, refactoring, and the introduction of new features. The absence of semantic awareness means developers often spend considerable time manually tracing code execution and inferring connections, significantly increasing cognitive load and hindering productivity.
The consequences of inadequate code comprehension extend far beyond simple inconvenience, manifesting as significant economic and reliability challenges for software projects. When developers struggle to grasp the intricate relationships within a codebase, debugging cycles lengthen considerably, as tracing the root cause of issues becomes a protracted and often frustrating process. This extended troubleshooting directly translates into higher maintenance costs, consuming valuable developer time and resources. More critically, a shallow understanding of code dependencies increases the likelihood of introducing new errors during modifications or feature additions; seemingly innocuous changes can trigger unforeseen consequences in distant parts of the system, ultimately compromising software stability and potentially leading to costly failures or security vulnerabilities.
Mapping the System: A Graph-Based Intelligence
LogicLens utilizes a ‘Semantic Graph’ as its foundational data structure, representing a software system as interconnected nodes and edges. ‘Code Nodes’ represent individual code elements – functions, classes, or variables – while ‘Project Nodes’ encapsulate higher-level project organization like repositories, modules, and dependencies. Critically, the graph extends beyond code and project structure to include ‘Entity Nodes,’ which model domain-specific concepts relevant to the software’s purpose – for example, ‘Customer’ or ‘Order’ in an e-commerce application. These node types are linked by edges defining relationships such as ‘calls,’ ‘uses,’ ‘defines,’ or custom relationships derived from static and dynamic analysis, enabling the system to model not just what the code does, but how different parts of the system interact and relate to the broader business domain.
Traditional static analysis and code search tools primarily rely on syntactic matching – identifying code elements based on their textual structure. LogicLens, however, utilizes a graph-based approach to capture the meaning of code, recognizing relationships between different code components regardless of their exact textual form. This allows the system to understand, for example, that a function call and a method invocation are semantically equivalent, even if expressed with different syntax. By representing code as interconnected nodes and edges, LogicLens can infer the intent and purpose of code elements, enabling a more nuanced and accurate understanding of the software’s behavior than is achievable through purely syntactic analysis. This semantic understanding is critical for tasks such as impact analysis, vulnerability detection, and code refactoring, where the underlying meaning of code is more important than its literal representation.
LogicLens integrates Large Language Models (LLMs) to augment its Semantic Graph beyond static code analysis. LLMs process code nodes, project nodes, and entity nodes, extracting contextual information such as function descriptions, variable meanings, and relationships to business logic. This information is then added as attributes and edges to the Semantic Graph, creating a richer representation of the software system. The LLMs also enable reasoning capabilities; given a query, the system uses the LLM to traverse the enriched graph, identify relevant nodes and relationships, and synthesize a contextually-aware response. This process allows LogicLens to understand the intent of the code, not just its structure, improving the accuracy and relevance of its insights.
LogicLens utilizes GraphRAG – a retrieval-augmented generation approach centered on a graph database – to deliver precise and contextually relevant responses. This process begins with graph-based retrieval, where the system traverses the Semantic Graph to identify nodes and relationships pertinent to a given query. Retrieved information isn’t simply presented; it’s fed as context to a Large Language Model (LLM). The LLM then leverages this structured, graph-derived context to generate responses, significantly improving accuracy and reducing the likelihood of hallucination compared to traditional LLM applications. This combination allows LogicLens to reason about the software system based on its inherent structure and interdependencies, rather than solely relying on textual code analysis.
Revealing the System’s Inner Workings
LogicLens introduces a debugging methodology centered around user-reported symptoms, enabling developers to query the system using descriptions of problematic behavior rather than requiring knowledge of specific code locations. This symptom-based approach allows for investigation initiated directly from user feedback, bypassing the need to first isolate the relevant code segment. The system correlates observed symptoms with underlying code dependencies, tracing the execution path responsible for the reported issue. This contrasts with traditional debugging, which typically requires developers to navigate code and manually identify the source of errors, potentially saving significant time and effort in complex systems.
LogicLens’s Impact Analysis capability determines the scope of influence introduced by new code changes. The system identifies all existing code elements-functions, classes, modules-that are directly or indirectly affected by a new feature or modification. This analysis extends beyond direct dependencies to encompass potential regressions, flagging areas where the new code might inadvertently disrupt existing functionality. By mapping these relationships, developers can proactively assess risk, prioritize testing efforts, and ensure the stability of the software as it evolves. The system’s structural graph facilitates this process by representing code dependencies as interconnected nodes, enabling efficient tracing of impact pathways.
LogicLens automatically generates high-level architectural views of the software system, providing developers with a visual and conceptual understanding of its organization. These views are constructed by analyzing the underlying structural graph, which maps code dependencies and relationships. The generated views abstract away low-level implementation details, allowing developers to focus on the overall system structure, identify key components, and understand how different parts of the software interact. This capability facilitates onboarding for new team members, simplifies code reviews, and aids in the planning of future development efforts by clearly illustrating the existing architecture.
LogicLens demonstrates a significant advancement in answering complex software system questions, achieving a 69.5% high-accuracy response rate. This performance represents a substantial improvement over the baseline system, which recorded 0% high accuracy on the same queries. The metric assesses the correctness of LogicLens’s responses when presented with intricate questions about the software’s functionality and internal state, indicating its ability to effectively reason about and understand the system’s behavior.
LogicLens exhibits substantial improvements in response quality as measured by coherence and completeness rates. Evaluations demonstrate a 52.2% coherence rate, indicating the logical consistency and clarity of its responses, a significant increase from the baseline system’s 17.39%. Furthermore, LogicLens achieves a 26.0% completeness rate – the proportion of questions answered with all necessary information – contrasting sharply with the baseline’s 0% rate. These metrics were determined through comparative analysis, highlighting LogicLens’s capability to generate more logically sound and comprehensive answers to complex queries about software systems.
The LogicLens Structural Graph is a representation of the software system constructed by analyzing code-level dependencies, inter-procedural calls, and data flow. This graph explicitly models relationships between software components – functions, classes, modules, and variables – allowing the system to reason about the software’s architecture and behavior. Nodes in the graph represent these components, and edges represent the dependencies between them. This structured representation facilitates automated analysis, enabling features such as symptom-based debugging, impact analysis, and the generation of high-level architectural views by providing a computational basis for understanding how changes propagate through the system and identifying potential issues.
Beyond Current Intelligence: Envisioning the Future
LogicLens represents a significant advancement in code intelligence by building upon the foundations laid by tools such as Sourcegraph, Aroma, Windsurf, and CodeQL. While these existing platforms excel at static analysis and code search, LogicLens distinguishes itself through the implementation of graph-based reasoning. This approach allows the system to move beyond simple pattern matching and instead understand the relationships between different code elements – functions, variables, and data structures. By representing code as a graph, LogicLens can infer complex dependencies, identify potential bugs that would be missed by traditional methods, and ultimately provide a more nuanced and comprehensive understanding of the software’s behavior. This capability unlocks possibilities for more accurate code completion, intelligent refactoring suggestions, and deeper insights into the underlying logic of complex systems.
LogicLens distinguishes itself through a deliberately modular design, prioritizing seamless integration with a diverse range of Large Language Models (LLMs). This architectural choice moves beyond reliance on a single AI engine, instead enabling developers to leverage the unique strengths of models like OpenAI’s Codex and Claude Code – and future iterations – within a unified framework. By functioning as an intermediary, LogicLens allows for experimentation with different LLMs, optimizing for specific tasks such as code completion, bug detection, or automated documentation. This flexibility isn’t merely about choice; it allows for a customized approach to software understanding, tailoring the AI’s analytical power to the nuances of individual codebases and development workflows. Ultimately, this modularity ensures LogicLens remains adaptable and powerful as the field of LLMs continues to rapidly evolve.
LogicLens leverages the power of vector databases, such as Qdrant, to revolutionize how code is understood and retrieved. Traditional code search relies on keyword matching, often missing semantically similar, but syntactically different, code fragments. Vector databases, however, represent code as high-dimensional vectors, capturing its meaning and context. This allows LogicLens to perform semantic searches – finding code not by what it is called, but by what it does. By embedding code fragments into this vector space, the system can quickly identify relevant sections, even if the keywords don’t match, significantly improving the accuracy and efficiency of code understanding tasks and enabling more intelligent code reuse and analysis.
The true potential of LogicLens extends beyond a standalone tool, envisioning a future where deep code understanding is seamlessly woven into the software development lifecycle. Integration with Integrated Development Environments (IDEs) promises real-time analysis, flagging potential bugs or inefficiencies as code is written, and even suggesting optimized solutions. Furthermore, incorporating LogicLens into Continuous Integration and Continuous Delivery (CI/CD) pipelines allows for automated refactoring, ensuring code quality remains consistently high throughout the development process. This proactive approach moves beyond reactive debugging, enabling developers to build more robust and maintainable software with increased efficiency and reduced technical debt – essentially, automating aspects of code review and improvement at every stage.
The pursuit of understanding large, multi-repository systems, as LogicLens attempts, mirrors the inevitable entropy inherent in all complex creations. This work acknowledges that systems aren’t static entities, but rather evolve through a series of interactions and, crucially, incidents-each a step toward maturity. As G.H. Hardy observed, “The most potent weapon in the armory of mathematics is the art of choosing a good notation.” Similarly, LogicLens posits that a well-constructed semantic graph-a robust ‘notation’ for code-is essential for navigating the inherent complexity of software. The system doesn’t promise perfection, but rather a graceful acceptance of decay through improved comprehension and a facilitated path towards system evolution.
What Lies Ahead?
The construction of LogicLens, while a demonstrable step towards more navigable codebases, merely highlights the inherent fragility of architectural understanding. Every system, however meticulously built, accrues entropy; the semantic graph, for all its potential, is not a preservation of intent, but a snapshot in time. The true challenge isn’t simply building the graph, but maintaining its relevance as the codebase inevitably shifts. A delay in updating this representation isn’t a technical flaw; it’s the price of understanding the evolving system.
Future iterations must move beyond static analysis and embrace a dynamic understanding of code lineage. The current approach, reliant on existing repositories, struggles to account for undocumented rationale or implicit knowledge embedded within developer practices. Integrating techniques that infer intent from commit histories, code review discussions, and even developer communication channels represents a necessary, though complex, evolution.
Ultimately, the value of tools like LogicLens isn’t in replacing developer intuition, but in augmenting it. Architecture without history is ephemeral; the graph must become a repository of why decisions were made, not simply what was implemented. The pursuit of complete knowledge is, of course, illusory. But a gracefully aging system, one whose history is preserved and accessible, will always outperform its more youthful, but ultimately more brittle, counterparts.
Original article: https://arxiv.org/pdf/2601.10773.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- World Eternal Online promo codes and how to use them (September 2025)
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
- ‘SNL’ host Finn Wolfhard has a ‘Stranger Things’ reunion and spoofs ‘Heated Rivalry’
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-21 00:18