Author: Denis Avetisyan
Researchers are developing language models that can continuously process and reason about audio, moving beyond simple transcription to true comprehension.
This paper introduces audio-interleaved reasoning, a technique that enhances large audio language models by enabling continuous engagement with audio during complex reasoning tasks.
While Large Audio Language Models (LALMs) hold promise for human-like audio comprehension, current approaches often bottleneck performance by encoding audio content only once. This limitation motivates the work presented in ‘Echo: Towards Advanced Audio Comprehension via Audio-Interleaved Reasoning’, which proposes a novel framework that treats audio as an active component in the reasoning process, enabling sustained engagement and perception-grounded analysis. By introducing audio-interleaved reasoning-instantiated through supervised fine-tuning and reinforcement learning-and a structured data generation pipeline, the authors demonstrate that LALMs can dynamically re-listen to audio during reasoning, achieving superior performance on challenging benchmarks. Could this approach unlock a new era of truly intelligent audio understanding?
The Echo Chamber: Beyond Transcription’s Limitations
Current large language models frequently process audio by first converting it into textual representations, a method that introduces a significant constraint on their ability to fully grasp the information contained within the sound itself. This reliance on text as an intermediary-often termed ‘audio-conditioned text reasoning’-can lead to a loss of crucial details, particularly those related to the subtle nuances of prosody, timbre, and the precise timing of events. The conversion process inherently discards information that isn’t easily captured in linguistic form, creating a bottleneck where the model’s comprehension is limited by the quality and completeness of the transcription, rather than a direct understanding of the acoustic signal. Consequently, the model’s reasoning capabilities become tethered to the imperfections of speech-to-text technology, hindering its potential for genuinely insightful audio analysis.
The prevalent approach of converting audio into textual representations before analysis by large language models introduces critical limitations in processing temporal information and maintaining engagement with the audio’s duration. This ‘audio-conditioned text reasoning’ effectively creates a summary, discarding the subtle nuances of timing, rhythm, and evolving acoustic features integral to full comprehension. Consequently, models struggle with tasks demanding precise temporal awareness-such as identifying the order of events in a soundscape or recognizing gradual shifts in emotional tone-and exhibit diminished performance when dealing with extended audio sequences. The reliance on textual proxies hinders the model’s ability to directly ‘listen’ and retain a continuous understanding of the auditory experience, leading to fragmented or incomplete interpretations of complex sound events.
![Switching from audio-conditioned to audio-interleaved reasoning allows LALM to significantly increase its focus on audio tokens ([latex]\Delta +140\%[/latex]), resulting in more meaningful and traceable audio analysis.](https://arxiv.org/html/2602.11909v1/x1.png)
Echo: A System That Listens, Not Translates
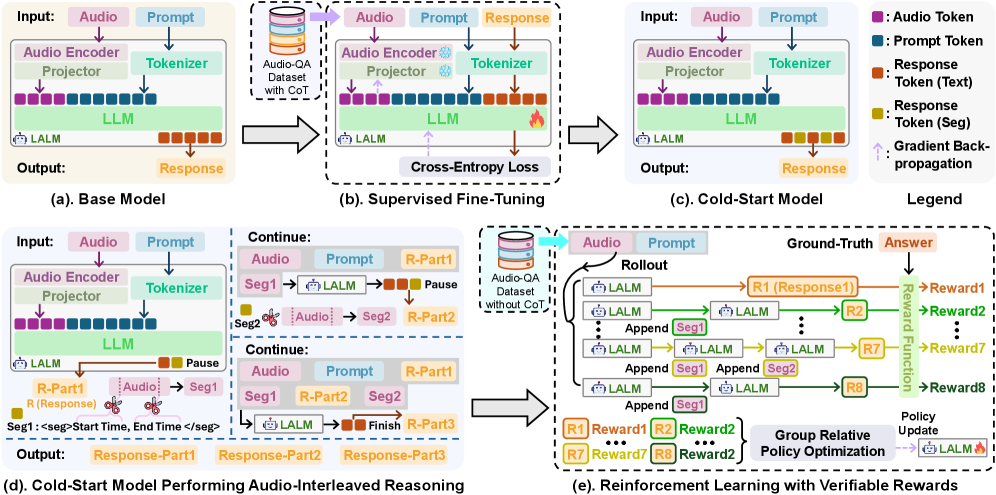
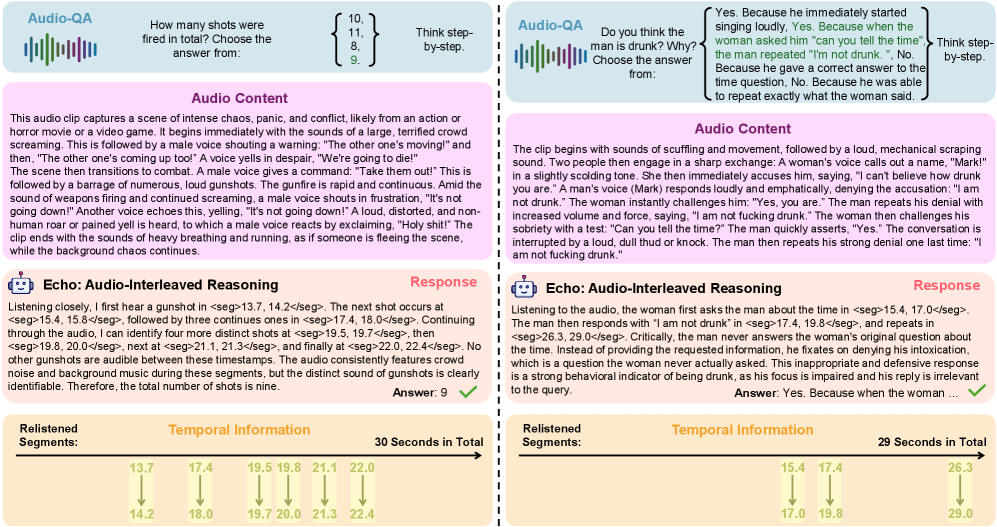
Echo is a Large Auditory Language Model (LALM) distinguished by its implementation of audio-interleaved reasoning. This methodology deviates from traditional approaches by integrating audio processing as a continuous, iterative component within the model’s reasoning process. Rather than processing an entire audio segment prior to analysis, Echo dynamically processes audio in conjunction with its internal reasoning steps, allowing it to actively seek and analyze relevant audio features as needed. This direct integration facilitates a feedback loop between audio perception and cognitive processing, forming the core of Echo’s architecture and enabling more nuanced auditory comprehension.
Echo’s architecture implements dynamic attention mechanisms that allow the model to selectively focus on relevant segments of an audio stream during processing. Unlike models relying on fixed-length audio encodings, Echo can revisit and re-analyze specific audio portions as required by the reasoning task. This selective attention is crucial for robust temporal understanding, as it enables the model to prioritize information based on its contextual relevance and maintain a coherent representation of events unfolding over time. The model doesn’t process the entire audio sequence uniformly; instead, it adaptively allocates computational resources to the most informative audio segments, improving performance on tasks demanding precise temporal reasoning.
Unlike traditional models that rely on a static, pre-processed audio encoding, Echo incorporates a design allowing for iterative and sustained audio processing. This means the model doesn’t simply convert audio into a fixed representation at the beginning of a task; instead, it can revisit and re-analyze specific audio segments as needed during the reasoning process. This dynamic engagement with the audio stream demonstrably improves performance on complex audio comprehension tasks requiring temporal understanding and nuanced interpretation, exceeding the capabilities of models limited to initial audio encodings.
Sculpting the Listener: Echo’s Training Regimen
Echo’s training utilizes a two-stage framework beginning with supervised fine-tuning (SFT). During SFT, the model learns to identify and localize relevant segments within audio inputs. This initial stage establishes a foundational understanding of audio event boundaries and durations. Subsequently, reinforcement learning (RL) is employed to refine the model’s reasoning process when presented with interleaved audio and textual data. RL optimizes the model’s ability to integrate audio information into its responses, improving the coherence and accuracy of its audio-based reasoning capabilities beyond the initial localization achieved through SFT.
The training framework utilizes temporal metadata present in datasets such as the AudioGrounding Dataset to establish precise alignment between audio events and model reasoning. This metadata details the start and end times of specific audio segments, enabling the model to learn the duration and temporal boundaries of relevant sounds. By grounding the model in these precise timings, the framework improves the accuracy of audio event localization and enhances the overall audio-interleaved reasoning process, allowing it to correctly identify and process sounds occurring at specific moments in time.
Large Language Models (LLMs), specifically DeepSeek-R1, contribute to the training of Echo through two key functions. First, they facilitate data synthesis, generating additional training examples to augment existing datasets and improve model generalization. Second, LLMs are utilized for manuscript polishing, refining the textual outputs of the model to enhance clarity and coherence. This process involves evaluating and correcting grammatical errors, improving sentence structure, and ensuring the overall quality of the generated text, ultimately contributing to a more robust and reliable audio-interleaved reasoning process.
A New Standard for Auditory Comprehension
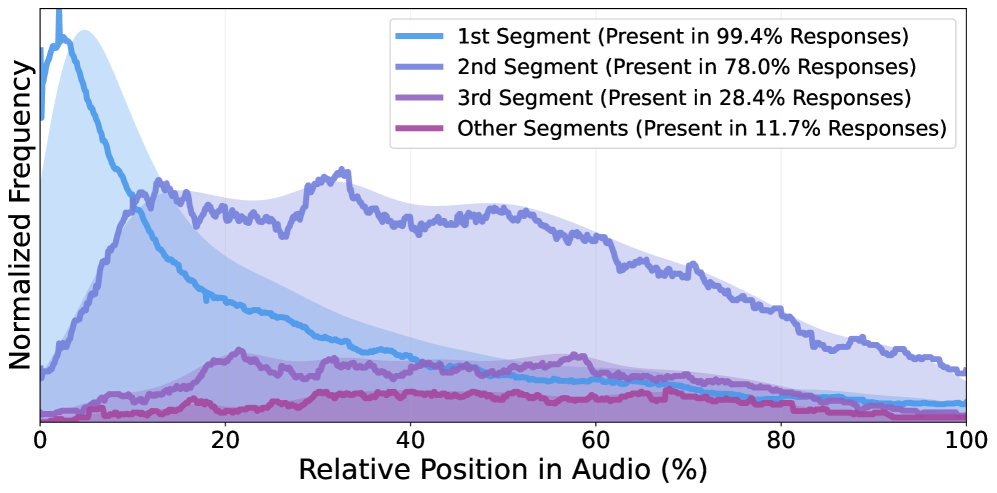
Echo establishes new performance standards in audio comprehension, exceeding existing benchmarks on both the challenging MMAU and MMAR datasets. These evaluations assess a model’s ability to process and understand spoken language, with MMAU focusing on multi-turn audio understanding and MMAR evaluating more complex reasoning capabilities. By achieving state-of-the-art results across both, Echo demonstrates a significant advancement in its capacity to accurately interpret and respond to diverse audio inputs – a crucial step toward more natural and effective human-computer interactions. The system’s performance suggests a robust architecture capable of handling the nuances and complexities inherent in spoken communication, setting a new high bar for future research in the field.
Evaluations demonstrate that Echo significantly outperforms established Large Audio Language Models (LALMs), including industry leaders such as GPT-4o and Gemini-2.0-Flash. Specifically, on the ‘MMAU-mini’ benchmark – a challenging test of multi-modal understanding – Echo achieves a 1.22% improvement in accuracy compared to its competitors. This result highlights Echo’s enhanced capacity for processing and interpreting audio information within a broader context, showcasing a measurable advancement in the field of audio comprehension and establishing a new standard for performance in multi-modal AI systems.
Despite incorporating audio processing into its reasoning loop, Echo maintains a consistent latency increase of approximately 13% – a trade-off demonstrating stable performance regardless of audio length. Detailed analysis reveals a high degree of segment precision, with Echo achieving 97.75% accuracy – measured as Intersection over Union (IoU) greater than or equal to ρ – when processing audio segments lasting between 11 and 20 seconds. This consistent latency and impressive precision highlight the system’s ability to effectively integrate and process audio information without significant performance degradation, even with varying input durations, suggesting a robust and scalable architecture for real-world applications.
The observed performance gains with Echo stem from a fundamental shift in how audio information is processed; rather than treating audio as a separate input for preliminary transcription, the system directly incorporates audio processing into its core reasoning mechanisms. This allows for a more holistic understanding of the input, capturing subtle cues, prosody, and contextual nuances often lost in transcription. By avoiding the information bottleneck inherent in converting audio to text, Echo can draw more accurate inferences and exhibit a more nuanced comprehension of spoken language, ultimately leading to improved performance on complex audio reasoning tasks and demonstrating the benefits of a tightly integrated audio-reasoning loop.

The pursuit of advanced audio comprehension, as detailed in this work, inevitably reveals the limitations of static systems. The architecture proposes audio-interleaved reasoning, a method of continuous engagement – a fascinating attempt to move beyond brittle, pre-defined structures. It’s a recognition that complete predictability is an illusion. As David Hilbert observed, “We must be able to answer the question: can mathematics be reduced to mechanics?” This resonates deeply; the effort to reduce complex audio understanding to a series of discrete steps feels similarly constrained. Stability, in the context of these large audio language models, is merely an illusion that caches well – a temporary respite before the inevitable emergence of unforeseen complexities. Chaos isn’t failure – it’s nature’s syntax, and this research leans into that beautifully.
What Lies Ahead?
The pursuit of audio comprehension, framed as large language models encountering sound, reveals a fundamental tension. This work, with its emphasis on interleaved reasoning, does not solve understanding – it merely refines the architecture of expectation. Each improvement in performance charts a more elaborate path toward inevitable misinterpretation. Monitoring becomes the art of fearing consciously; the system doesn’t err randomly, but predictably, given the limits of its constructed world. The real challenge isn’t building a model that sounds like it understands, but accepting that true intelligence resides in graceful degradation.
The focus on continuous engagement is a tacit acknowledgement that discrete analysis is a fallacy. Sound isn’t segmented; it flows. Yet, this flow is inevitably discretized within the computational framework, creating a phantom limb sensation for the model. Future iterations will likely explore methods for embracing this inherent friction, perhaps through architectures that deliberately introduce controlled instability. The system will not be ‘fixed’ – it will learn to respond to its own failures.
True resilience begins where certainty ends. The current trajectory, toward ever-larger models and more comprehensive datasets, risks building exquisitely fragile systems. The next step isn’t simply more data, but a radical re-evaluation of what constitutes ‘understanding’ in the first place. That’s not a bug – it’s a revelation.
Original article: https://arxiv.org/pdf/2602.11909.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Physics Proved by AI: A New Era for Automated Reasoning
- Total Football free codes and how to redeem them (March 2026)
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Invincible Creator on Why More Spin-offs Haven’t Happened Yet
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
2026-02-15 14:34