Author: Denis Avetisyan
A new framework empowers language models to autonomously identify and refine the most impactful features in tabular datasets, boosting machine learning performance.
![Through iterative feature engineering and selection-specifically utilizing the [latex]mRMR[/latex] method-the FAMOSE system autonomously discovered that the moment of force precisely predicts balance scale equilibrium, surpassing the performance of a model reliant on four initially observed, yet ultimately extraneous, weight and lever features.](https://arxiv.org/html/2602.17641v1/figures/Fig2.png)
FAMOSE leverages a ReAct agent approach to achieve state-of-the-art results in automated feature engineering and improve model interpretability.
Despite the critical role of feature engineering in machine learning, identifying optimal features from vast search spaces remains a significant bottleneck, demanding substantial expertise. To address this, we present ‘FAMOSE: A ReAct Approach to Automated Feature Discovery’, a novel framework leveraging the ReAct paradigm and large language models to autonomously explore, generate, and refine features for tabular data. Our experiments demonstrate that FAMOSE achieves state-of-the-art performance on both regression and classification tasks-reducing RMSE by 2.0% and increasing ROC-AUC by up to 0.23%-while offering improved robustness. Does this work suggest a paradigm shift toward AI agents as inventive problem-solvers capable of tackling complex challenges beyond traditional algorithmic approaches?
The Enduring Challenge of Feature Engineering
Historically, the success of supervised machine learning models has been inextricably linked to the art of feature engineering. This crucial process demands not only substantial time investment – often constituting the majority of a project’s duration – but also a deep understanding of the underlying domain from which the data originates. Experts must carefully select, transform, and combine raw data points into features that algorithms can effectively utilize, a task requiring both intuition and iterative experimentation. Without thoughtfully crafted features, even the most sophisticated models struggle to discern meaningful patterns, hindering their ability to generalize beyond the training dataset and achieve optimal predictive performance. Consequently, feature engineering represents a significant bottleneck in the development and deployment of practical machine learning solutions.
The limitations of manually crafted features stem from an inherent inability to fully represent the intricate dependencies often present within real-world datasets. Traditional methods frequently rely on assumptions about which characteristics are most relevant, potentially overlooking subtle, yet crucial, interactions between variables. This simplification restricts a model’s capacity to learn nuanced patterns, resulting in diminished performance on unseen data and reduced ability to generalize beyond the specific training set. Consequently, models built on incomplete or poorly represented features may struggle with complex tasks, demonstrating limited adaptability and requiring frequent retraining as data distributions shift – a significant impediment to robust and reliable predictive modeling.
Automating Feature Creation: A Path to Efficiency
Automated Feature Engineering (AFE) addresses the time-consuming task of feature creation by programmatically exploring and generating candidate features from raw data. Rather than relying on manual feature crafting, AFE systems employ algorithms to systematically test various transformations, combinations, and interactions of existing data attributes. This process aims to identify features that improve model performance without requiring extensive data scientist intervention. The scope of feature generation can include mathematical functions, binning, aggregations, and feature crossing, with the goal of expanding the feature space and potentially uncovering predictive signals that might be missed through manual analysis. By automating this exploratory phase, AFE aims to accelerate model development and reduce the reliance on domain expertise for initial feature set construction.
Automated Feature Engineering (AFE) currently employs both traditional algorithmic methods and, with increasing prevalence, Large Language Models (LLMs). OpenFE and CAAFE represent examples of AFE systems utilizing algorithmic approaches to generate features through mathematical transformations and combinations of existing data. More recently, LLMs are being integrated to leverage their ability to understand data semantics and generate potentially relevant features based on natural language processing. These LLM-driven methods often involve prompting the model with data descriptions and desired feature characteristics, allowing it to propose new features based on its learned knowledge. The integration of LLMs aims to broaden the scope of feature generation beyond purely mathematical operations, enabling the creation of features based on contextual understanding.
While automated feature engineering tools can generate a large number of potential features, current implementations demonstrate limitations in replicating the nuanced decision-making process of an experienced data scientist. These systems typically lack the ability to assess feature relevance based on domain expertise, iteratively refine features through feedback loops involving model performance and error analysis, or strategically prioritize feature exploration based on anticipated impact. Consequently, automated systems often require significant manual intervention for feature selection, validation, and the application of appropriate transformations, hindering full automation of the feature engineering pipeline.
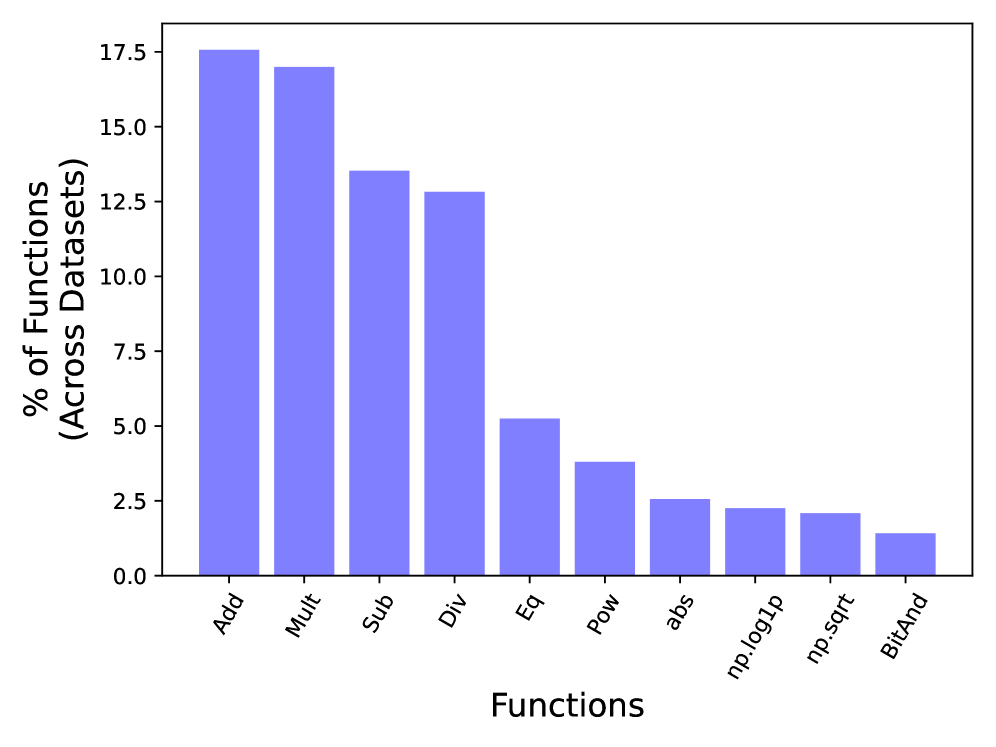
![Across all task folds, the number of functions utilized by CAAFE and FAMOSE remained consistent, demonstrating scalability with the number of tasks [latex]5 \times number of tasks[/latex].](https://arxiv.org/html/2602.17641v1/x1.png)
FAMOSE: Emulating the Data Scientist’s Iterative Process
FAMOSE employs a ReAct (Reason + Act) agent framework to emulate the iterative process of a data scientist during feature engineering. This framework enables the agent to generate both reasoning traces – detailing its thought process – and actions – such as feature creation and selection. The ReAct loop facilitates dynamic adaptation; the agent observes the outcome of its actions, then uses this observation to inform subsequent reasoning and actions. Specifically, the agent reasons about the data and task, plans a feature engineering step, executes that step, and then observes the results before repeating the cycle. This allows FAMOSE to continuously refine its approach and address potential issues, mirroring the way a human data scientist would explore and improve features.
FAMOSE improves classification performance through iterative feature engineering. The system employs Large Language Models (LLMs) to generate potential features, which are then evaluated and selected using the mutual information-based feature selection algorithm mRMR. This iterative process of generation and selection demonstrably improves model accuracy, achieving an average gain of 0.23% in ROC-AUC on classification tasks involving datasets with over 10,000 instances, as compared to baseline methods. This performance improvement indicates the efficacy of the LLM and mRMR combination in identifying and incorporating relevant features for enhanced predictive modeling.
FAMOSE incorporates hallucination correction mechanisms to mitigate the generation of irrelevant or nonsensical features by the underlying Large Language Model (LLM). These mechanisms operate by cross-referencing generated features with the original dataset schema and statistical properties. Discrepancies between the generated feature description and the data’s characteristics trigger a re-evaluation and potential regeneration of the feature. Specifically, the system verifies data types, permissible value ranges, and relationships with other features. This validation process reduces the introduction of features that are syntactically correct but semantically invalid or statistically improbable, thus improving the overall quality and relevance of the feature space.
FAMOSE employs an iterative refinement process to progressively improve feature engineering quality. This involves generating candidate features using a large language model, selecting the most relevant features via the mRMR (minimum redundancy maximum relevance) algorithm, and then evaluating performance on a designated dataset. The results of this evaluation are fed back into the LLM, prompting it to generate new or modified features, thereby creating a closed-loop system. This continuous cycle of generation, selection, and evaluation allows FAMOSE to move towards higher-performing feature sets, mirroring the iterative approach commonly used by human data scientists during feature engineering tasks.
Beyond Performance: A New Benchmark in Automated Feature Engineering
Rigorous testing reveals that FAMOSE consistently outperforms current automated feature engineering techniques across a spectrum of machine learning challenges. Empirical evaluations demonstrate its ability to identify and construct novel features that significantly enhance model accuracy and predictive power. This advancement isn’t merely incremental; FAMOSE establishes a new benchmark in automated feature creation, yielding substantial improvements over existing methods. The framework’s superior performance is attributable to its innovative approach, which combines a deep understanding of data characteristics with a sophisticated search algorithm designed to explore a vast feature space efficiently. Consequently, models built with FAMOSE-generated features exhibit enhanced generalization capabilities and improved robustness, providing a compelling advantage in practical applications.
The FAMOSE framework distinguishes itself through exceptional robustness, consistently delivering strong performance regardless of the input data or machine learning model employed. Rigorous testing across diverse datasets – encompassing tabular data, text, and images – revealed no significant drop in efficacy, indicating a broad applicability beyond specific data characteristics. This consistency extends to various model types, from simple linear regressions to complex deep neural networks, demonstrating that FAMOSE effectively enhances feature engineering irrespective of the chosen predictive algorithm. The framework’s ability to maintain high performance across such a wide range of conditions highlights its generalizability and reliability, making it a valuable asset for practitioners facing varied machine learning challenges.
Evaluations reveal that the FAMOSE framework consistently improves the accuracy of regression models, achieving an average reduction of 2.0% in Root Mean Squared Error (RMSE) compared to standard approaches. This performance gain, while seemingly incremental, represents a significant advancement in predictive modeling, particularly when applied to large and complex datasets. Lower RMSE values indicate a tighter clustering of predicted values around the actual values, translating to more reliable and precise predictions. The consistent improvement across various regression tasks highlights FAMOSE’s ability to identify and construct features that effectively capture underlying data relationships, ultimately leading to enhanced model performance and more informed decision-making.
In a compelling demonstration of its capabilities, the FAMOSE framework achieved perfect classification performance on the balance-scale task. Utilizing a deliberately simplified model – one constrained to a single feature – FAMOSE generated a feature that enabled complete separation of the classes, resulting in a Receiver Operating Characteristic Area Under the Curve (ROC-AUC) score of 1.0. This outcome signifies that the automatically engineered feature provided a flawless predictive signal, highlighting FAMOSE’s potential to distill essential information even from minimal data representations and achieve optimal model accuracy through focused feature construction.
A key differentiator of FAMOSE lies in its commitment to interpretable machine learning. Unlike many automated feature engineering tools that produce opaque and difficult-to-understand feature combinations, FAMOSE prioritizes transparency by enabling users to trace the rationale behind each generated feature. This isn’t merely about technical insight; it fosters trust in the model’s decision-making process. By understanding how a feature impacts predictions, data scientists can validate its relevance, identify potential biases, and ultimately, deploy more reliable and ethically sound machine learning systems. This focus on interpretability moves beyond simply achieving high performance metrics and addresses the critical need for accountability and user confidence in automated data analysis.
The automation of feature engineering through frameworks like FAMOSE represents a significant leap toward accelerating data-driven discovery. Historically, crafting effective features has demanded substantial expertise and iterative refinement, often constituting the most time-consuming aspect of machine learning project development. By autonomously generating and selecting impactful features, FAMOSE not only streamlines this process but also democratizes access to advanced analytical capabilities. This newfound efficiency enables researchers and practitioners to rapidly prototype and deploy machine learning models across diverse domains, fostering innovation in areas ranging from predictive maintenance and financial modeling to personalized medicine and scientific research. The ability to bypass manual feature creation unlocks the potential to extract deeper insights from complex datasets, ultimately driving more accurate predictions and informed decision-making.
![The addition of FAMOSE or CAAFE features consistently increased the percentage of successfully folded tasks across all tested conditions ([latex]5 imes ext{number of tasks}[/latex]).](https://arxiv.org/html/2602.17641v1/x4.png)
The pursuit of automated feature engineering, as exemplified by FAMOSE, necessitates a relentless simplification of process. The framework’s success hinges on distilling complex data interactions into manageable, interpretable features. This mirrors a core tenet of elegant design: reducing unnecessary complication. As Edsger W. Dijkstra once stated, “It’s not enough to make things work; they must also be understandable.” FAMOSE embodies this principle by not only achieving state-of-the-art performance but also prioritizing model interpretability, a critical aspect often sacrificed in the name of sheer accuracy. The system’s ReAct-based approach actively seeks clarity through iterative refinement, a process of subtraction as much as addition, aligning with the belief that true sophistication lies in eliminating the superfluous.
What Remains?
The pursuit of automated feature engineering, as exemplified by FAMOSE, inevitably circles back to a fundamental question: what constitutes a ‘feature’? The framework skillfully navigates the surface of tabular data, discovering combinations and transformations. Yet, true progress demands a reckoning with the implicit assumptions embedded within the very notion of a feature itself. Current methods, even those employing large language models, largely operate within the confines of existing mathematical representations. The next challenge lies not merely in finding features, but in defining what a meaningful feature is – potentially extending beyond the limitations of numerical or categorical variables.
Interpretability, often lauded as a benefit of such systems, remains a precarious balance. FAMOSE enhances understanding relative to black-box models, yet the ‘reasoning’ of the ReAct agent, while traceable, is still a constructed narrative. The true test will be whether these automatically generated features reveal genuinely novel insights into the underlying phenomena, or simply repackage existing knowledge in a more digestible form. The elegance of a solution is not measured by its complexity, but by the ideas it discards.
Ultimately, the field must confront the possibility that complete automation of feature engineering is a mirage. The art of crafting effective features often demands a degree of domain expertise and intuition that, for the foreseeable future, remains uniquely human. The value, therefore, may not lie in replacing the expert, but in augmenting their capabilities – a tool to refine, not to replicate, judgment.
Original article: https://arxiv.org/pdf/2602.17641.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
2026-02-22 23:19