Author: Denis Avetisyan
A new reinforcement learning framework enables artificial intelligence to dynamically adjust to human teammates, fostering more effective and intuitive collaboration.
![A nested training regime fosters adaptive interaction by first establishing a set of human policies against fixed robotic behaviors, then training a second-level robot against these adaptive policies-a process that utilizes latent embeddings to approximate beliefs over multiple partner strategies within a nested partially observable Markov decision process [latex]I-POMDP[/latex].](https://arxiv.org/html/2602.17737v1/images/arch.png)
Researchers propose a nested training approach based on interactive Partially Observable Markov Decision Processes (I-POMDPs) to achieve mutual adaptation in human-AI teams.
Achieving effective human-AI collaboration requires agents capable of adapting to evolving human strategies, yet current approaches struggle to generalize beyond limited training partners. This paper, ‘Nested Training for Mutual Adaptation in Human-AI Teaming’, addresses this challenge by framing the interaction as an Interactive Partially Observable Markov Decision Process (I-POMDP) and introducing a novel nested reinforcement learning framework. The method trains agents against increasingly adaptive opponents, avoiding the pitfalls of opaque coordination that hinder generalization. By explicitly modeling human adaptation, can we unlock truly collaborative AI systems capable of seamless teamwork with diverse human partners?
The Challenge of Coordination: Modeling Intent in Complex Systems
Truly effective multi-agent systems demand more than independent action; agents must model, predict, and react to the intentions and behaviors of others, a feat particularly challenging within dynamic and unpredictable environments. This requirement for reciprocal adaptation stems from the fact that an agent’s optimal strategy is often contingent on what it believes other agents will do. As environments become more complex, with increased numbers of interacting agents and a wider range of possible actions, the computational burden of anticipating these behaviors grows exponentially. Consequently, systems falter when confronted with novel situations or adversarial agents, highlighting the need for robust algorithms capable of not just reacting to observed actions, but proactively inferring underlying motivations and future plans. The ability to effectively model the mental states of other agents – often termed ‘theory of mind’ – is therefore a cornerstone of intelligent coordination in complex systems.
Conventional reinforcement learning algorithms frequently falter when faced with scenarios demanding an understanding of other agents’ intentions – a concept known as ‘level-2 reasoning’. These methods excel at learning optimal policies assuming a static environment, but struggle when confronted with the shifting strategies of intelligent opponents or collaborators. Consequently, strategies developed through traditional reinforcement learning can become easily exploited or rendered ineffective by even minor deviations in the behavior of others, resulting in ‘brittle’ performance. This predictability stems from the algorithm’s inability to model the reasoning processes of its counterparts, limiting its adaptability and hindering success in complex, multi-agent settings where anticipating actions is crucial for robust performance.
The chaotic kitchen of the video game Overcooked serves as a surprisingly robust arena for artificial intelligence research, particularly in the development of algorithms demanding sophisticated coordination. Unlike many simulated environments focused on individual task completion, Overcooked necessitates agents to not only perform actions – chopping vegetables, cooking meat, washing dishes – but to actively anticipate the actions of teammates. Successful gameplay relies on understanding and reacting to the evolving roles and intentions of others, mirroring the challenges of real-world teamwork. This dynamic, requiring constant adjustment and shared awareness, presents a demanding testbed for multi-agent reinforcement learning, pushing algorithms beyond simple reactive behaviors toward more nuanced and proactive strategies capable of handling unpredictable, collaborative scenarios.
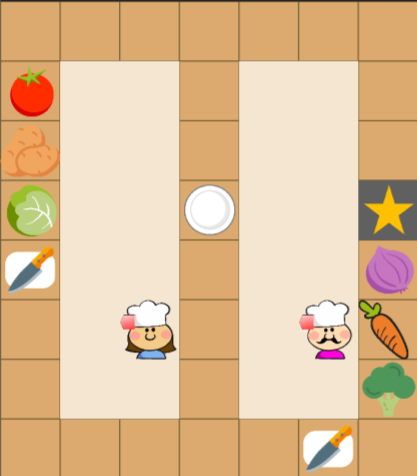
Hierarchical Reasoning: Nesting Reinforcement Learning for Adaptability
Nested Reinforcement Learning implements a hierarchical structure wherein multiple reinforcement learning agents operate at different levels of abstraction. Lower-level policies, responsible for basic actions and immediate responses, provide input and constraints to higher-level policies engaged in more complex planning and decision-making. This allows the system to decompose a complex task into manageable sub-tasks, with each level building upon the outputs of those below it. Specifically, higher-level agents do not directly control low-level actions; instead, they issue goals or modify parameters for the lower-level policies, effectively directing their behavior without specifying every detail. This decomposition improves scalability and allows for more efficient exploration of the action space, as each level focuses on a specific aspect of the overall problem.
The system trains a Level-2 Robot Policy to interact with and against dynamically adjusting Level-1 Human Policies. This is achieved by establishing an adversarial training loop where the Level-2 policy learns to optimize its actions based on the current behavior of the Level-1 policies, and the Level-1 policies simultaneously adapt to maximize their performance against the Level-2 policy. This reciprocal training process forces both policies to evolve strategies that account for the anticipated responses of the other, resulting in a more robust and adaptable interaction model. The Level-1 policies are not pre-defined but are trained concurrently, allowing the system to model realistic, evolving human behavior and improve the Level-2 policy’s ability to generalize to novel interaction scenarios.
The system utilizes an Interactive-Partially Observable Markov Decision Process (Interactive-POMDP) framework to model multi-agent interactions where agents must reason about the beliefs and actions of others. Unlike standard POMDPs which focus on a single agent navigating an uncertain environment, Interactive-POMDPs explicitly represent the other agents as part of the environment, allowing the learning agent to model their beliefs, intentions, and potential responses to actions. This is achieved by extending the state space to include the beliefs of other agents, and defining transition and observation functions that account for their actions. Consequently, the agent can formulate policies based not only on its own observations but also on its beliefs about the information and reasoning processes of other agents, enabling more sophisticated strategic behavior and coordination.
Level-0 Robot Policies function as a fixed, pre-trained foundation for developing adaptive human-like policies, termed Level-1 Human Policies. These Level-0 policies are initially deployed as the opponent within the training environment, providing a consistent and predictable benchmark against which the Level-1 policies can learn. This initial training phase establishes a baseline performance level, allowing the system to measure the progress of the adaptive policies as they learn to interact and compete. The Level-0 policies remain static throughout this process, ensuring that any observed improvements in the Level-1 policies are attributable to their learning algorithms and not to changes in the opponent’s behavior. After sufficient training against the Level-0 policies, the Level-1 policies are then utilized as opponents for subsequent training iterations.
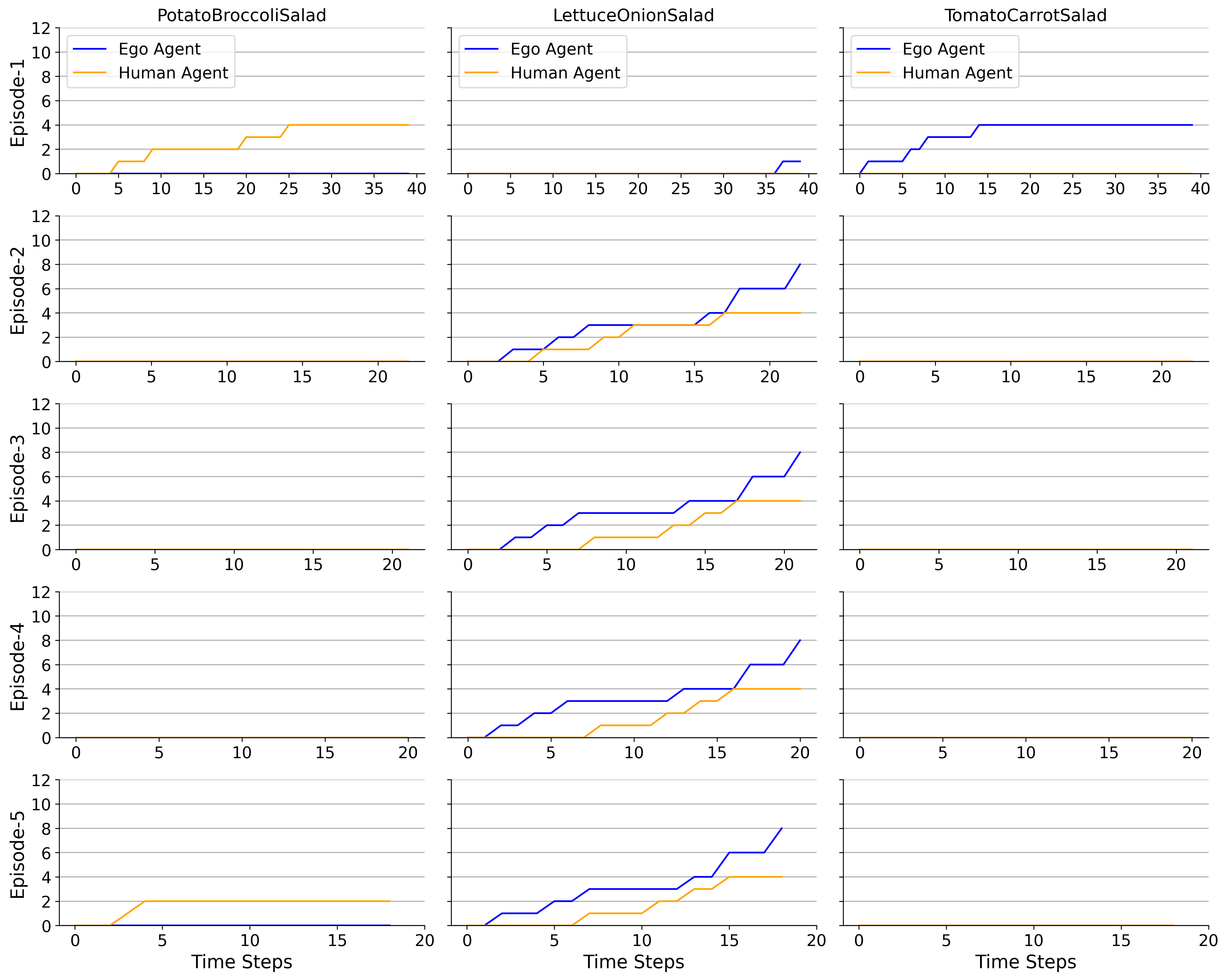
Evidence of Adaptability: Non-Convergence as a Sign of Intelligent Behavior
Experimental results indicate that the implemented nested training regime produces policies that do not converge to a singular, fixed strategy. This ‘Non-Convergence to Single Convention’ is characterized by continuous adaptation during training and evaluation, preventing the agent from settling on a specific behavioral pattern. Data shows the learned policies maintain a degree of stochasticity, allowing them to explore and refine strategies throughout the learning process, rather than optimizing for a single, predetermined solution. This behavior is consistently observed across multiple training runs and evaluation scenarios, indicating it is not a result of random chance or hyperparameter sensitivity.
The observed non-convergence to a single strategy indicates the agents are developing adaptive behaviors rather than relying on memorization of specific coordination patterns. This is evidenced by the framework’s ability to maintain performance across diverse interaction scenarios; the agents do not lock into a single solution optimized for a limited set of partner behaviors. Instead, the policies demonstrate flexibility, effectively generalizing to novel partner strategies not encountered during training. This adaptability is a key differentiator from conventional reinforcement learning approaches, which often exhibit brittle behavior when faced with deviations from the training distribution.
The Level-2 policy within our framework utilizes a latent embedding to represent the history of interactions between agents. This embedding is a low-dimensional vector that captures relevant information from past joint actions and observations, allowing the policy to maintain a contextual understanding of the ongoing game. By approximating the interaction history, the latent embedding enables the Level-2 policy to dynamically adjust its behavior based on the perceived tendencies of its partner, rather than relying on a fixed strategy or memorized patterns. The dimensionality of this embedding is a key hyperparameter, optimized to balance representational capacity and computational efficiency.
Comparative benchmarking demonstrates the superior performance of the proposed framework against established reinforcement learning algorithms. Specifically, the system achieved an average success rate of 0.900 in short evaluation scenarios and 0.935 in extended evaluations. This represents a substantial improvement over the next-best performing baseline, a Generalist Policy, which achieved a success rate of 0.575 under the same conditions. The algorithms used for comparison included LILI and PACE, though specific performance metrics for these are detailed elsewhere in the report.
Implications for Intelligent Systems: Toward Mutual Adaptation and Robust Coordination
Nested Reinforcement Learning demonstrates a compelling route towards creating agents that thrive through ‘Mutual Adaptation’ within dynamic environments. Unlike conventional methods that depend on predetermined strategies or static models of collaborators, this approach allows agents to learn not just how to act, but also to anticipate and respond to the evolving strategies of others. This iterative process of modeling and adapting fosters a synergistic relationship between agents, leading to more robust and efficient performance in complex scenarios. The resulting systems exhibit a remarkable ability to navigate uncertainty and achieve collective goals, even when faced with unpredictable interactions – a crucial advancement for the development of truly intelligent multi-agent systems.
Traditional multi-agent systems often falter when faced with unpredictable partners or dynamic environments, because they operate with pre-programmed strategies or rely on simplified models of other agents’ behavior. Nested Reinforcement Learning, however, allows agents to construct internal representations of what other agents believe and intend, effectively modeling the reasoning processes of their counterparts. This capability transcends the limitations of fixed models, enabling agents to anticipate actions, adapt to evolving strategies, and coordinate more effectively even when facing novel or adversarial behavior. By actively inferring the mental states of others, these agents can move beyond reactive responses and engage in proactive, collaborative problem-solving, opening new avenues for robust and flexible multi-agent systems.
The advent of Nested Reinforcement Learning extends far beyond theoretical advancements, promising tangible benefits across a diverse spectrum of applications. In robotics, this approach could facilitate more seamless human-robot collaboration, allowing machines to anticipate and adapt to human intentions with greater precision. Autonomous driving stands to gain from agents capable of modeling the behavior of other vehicles and pedestrians, leading to safer and more efficient navigation in complex traffic scenarios. Even in the realm of game playing, this technology offers the potential for creating more realistic and challenging artificial opponents. Perhaps most significantly, the ability to model the reasoning of others unlocks new possibilities for human-computer interaction, paving the way for interfaces that are truly intuitive, responsive, and capable of building genuine rapport with users.
Future investigations are poised to extend Nested Reinforcement Learning beyond current limitations, specifically addressing the challenges of increased environmental complexity and data scarcity. Researchers aim to develop techniques that allow agents to maintain robust adaptive behavior even when faced with significantly larger state and action spaces. A key area of exploration involves methods for efficient knowledge transfer and generalization, enabling agents to learn effectively from a minimal amount of training data – a critical requirement for real-world applications where exhaustive data collection is often impractical. This includes investigating meta-learning approaches and leveraging simulation-to-real transfer techniques to bridge the gap between controlled environments and the unpredictable nature of complex, real-world scenarios, ultimately paving the way for more versatile and resourceful multi-agent systems.
The pursuit of effective human-AI teaming, as detailed in this work, hinges on recognizing the interconnectedness of system components. The proposed nested reinforcement learning framework, built upon the finitely nested I-POMDP formulation, exemplifies this principle; adaptation isn’t merely about optimizing individual agents, but fostering a collaborative dynamic where mutual understanding scales performance. This echoes Brian Kernighan’s observation: “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” Just as convoluted code hinders comprehension, a complex, non-adaptive system stifles effective collaboration. The elegance of this approach lies in its simplicity – a scalable system built on clear ideas, acknowledging that true intelligence emerges from well-structured interaction.
The Road Ahead
The presented framework, while demonstrating a pathway toward more robust human-AI collaboration, merely sketches the contours of a deeply complex landscape. The reliance on a finitely nested Interactive Partially Observable Markov Decision Process (I-POMDP), though elegant in its formulation, highlights an inherent limitation: real-world interactions rarely adhere to neatly defined levels of reasoning. The question isn’t simply whether an agent can reason about another’s beliefs, but how that reasoning is constrained by cognitive load and imperfect information-factors currently treated as externalities. Future work must grapple with the messy reality of incomplete models, both of the environment and of the collaborative partner.
Furthermore, generalization remains a persistent challenge. Demonstrating improved coordination within controlled laboratory settings is a necessary, but insufficient, step. The true test lies in deploying these systems in dynamic, unpredictable environments where the structure of the task itself evolves. The current approach tacitly assumes a degree of task stability that is rarely encountered in practice. A more holistic design would integrate mechanisms for continuous model refinement and adaptation, allowing the AI to not only learn with the human, but also to learn about the changing nature of the collaboration itself.
Ultimately, the pursuit of mutual adaptation is not merely a technical problem, but a philosophical one. It forces a re-evaluation of the very notion of “intelligence” – shifting the focus from maximizing individual performance to fostering emergent collective behavior. The most fruitful avenues for future research likely lie at the intersection of reinforcement learning, cognitive science, and the study of complex systems, where the emphasis is on understanding how simple interactions can give rise to surprisingly intricate and resilient forms of collaboration.
Original article: https://arxiv.org/pdf/2602.17737.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Total Football free codes and how to redeem them (March 2026)
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- ‘Project Hail Mary’s Soundtrack: Every Song & When It Plays
2026-02-24 00:59