Author: Denis Avetisyan
A new imitation learning framework enhances robot skill acquisition by incorporating real-time visual and haptic cues to guide demonstrators toward physically realizable motions.
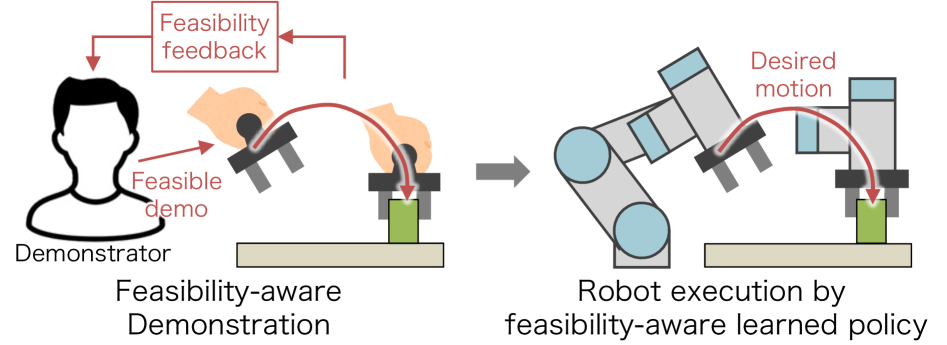
This research introduces FABCO, a system that leverages feasibility feedback to improve the robustness and accuracy of learned robot policies from observational data.
Despite advances in imitation learning, transferring demonstrated robot tasks remains challenging due to discrepancies between demonstrator capabilities and robot dynamics. This paper introduces ‘Feasibility-aware Imitation Learning from Observation with Multimodal Feedback’, a novel framework that addresses this limitation by integrating real-time feasibility estimation with human demonstration. By providing demonstrators with both visual and haptic feedback on motion feasibility, FABCO guides the creation of demonstrations that are readily reproducible by the robot, leading to significantly improved policy learning. Could this approach unlock more intuitive and efficient human-robot collaboration in complex manipulation tasks?
The Fragility of Imitation: Beyond Static Demonstrations
Behavior Cloning, a foundational approach to robot learning, frequently encounters limitations when applied to novel situations. This method relies on directly mapping observed actions to states, effectively memorizing a set of demonstrations; however, this memorization proves brittle outside the precise conditions of the training data. A robot trained solely through Behavior Cloning may perform flawlessly when replicating a demonstrated trajectory, but struggles when presented with even slight variations – a shifted object, altered lighting, or unexpected obstacle. This lack of generalization stems from the model’s inability to infer underlying principles or adapt to unforeseen circumstances, instead rigidly adhering to the provided examples and failing to extrapolate beyond them. Consequently, robots trained exclusively with Behavior Cloning often exhibit limited robustness and struggle to operate reliably in the dynamic and unpredictable environments characteristic of real-world applications.
Robots venturing into unpredictable real-world settings frequently encounter situations not explicitly covered in their initial training data. This limitation of static demonstrations – where a robot simply mimics pre-recorded actions – results in brittle performance and unexpected failures when faced with novel obstacles or variations. A robot trained solely on a fixed dataset may struggle to adjust its movements when an object is slightly misplaced, lighting conditions change, or an unforeseen person enters its workspace. Consequently, these systems exhibit a lack of adaptability, hindering their ability to reliably perform tasks in complex and dynamic environments where consistent, precise repetition of demonstrated behavior is rarely possible.
Effective robot instruction necessitates a shift from passive observation to active learning, where iterative feedback guides the robot toward successful task completion. Traditional methods often rely on robots simply mirroring demonstrated actions, a strategy that falters when encountering novel situations. A robust learning framework, however, allows the robot to explore potential actions and receive signals – whether rewards for correct performance or corrective guidance – that refine its behavior over time. This continuous cycle of action, feedback, and adaptation is crucial for mastering complex tasks, enabling robots to not just replicate demonstrated skills, but to generalize and improve their performance in dynamic and unpredictable environments. Such systems move beyond simple mimicry, fostering true robotic competency and resilience.
![The FABCO framework enhances imitation learning by integrating feasibility feedback-computed via [latex]FDM[/latex] and [latex]IDM[/latex]-into both demonstration refinement and policy learning, enabling the generation of feasible robot motions.](https://arxiv.org/html/2602.15351v1/x4.png)
A Dialogue in Motion: Interactive Learning’s Promise
Interactive Imitation Learning (IIL) addresses the limitations of traditional Imitation Learning, which relies on static datasets of demonstrations. Unlike methods solely based on observational data, IIL enables a dynamic learning process where a robot actively requests guidance from a human teacher during execution. This interaction occurs in real-time; when the robot’s actions deviate from the expected trajectory, it queries the human for the correct action to take in that specific situation. The human provides corrective feedback, which is then used to refine the robot’s policy and improve its performance. This iterative process of action, query, and correction allows the robot to learn more efficiently and generalize to scenarios not explicitly covered in the initial demonstration data, effectively bridging the gap between supervised learning and fully autonomous behavior.
DART (Direct Aggregation of Reactive Trajectories) and DAgger (Dataset Aggregation) are iterative algorithms used in interactive imitation learning. Both function by having a robot execute a policy, then requesting human intervention when the robot’s actions diverge from a demonstrated or desired trajectory. DART directly aggregates the corrective actions provided by the human into the robot’s policy, effectively creating a new trajectory reflecting the correction. DAgger, conversely, collects the human-provided corrective actions as a dataset and uses this dataset to train a supervised learning policy, aiming to mimic the human’s corrective behavior and improve future performance. The key distinction lies in how the corrective feedback is integrated – DART integrates directly, while DAgger uses it for broader policy retraining.
Traditional observational learning methods, where a robot learns solely from demonstrated examples, often struggle with generalizing to novel situations or recovering from errors. Interactive learning addresses these limitations by enabling the robot to actively request feedback from a human teacher when its predicted actions are uncertain or deviate from the desired behavior. This feedback, typically in the form of corrective actions or approval of the robot’s current state, is then used to refine the robot’s internal policy through algorithms like DART or DAgger. By iteratively querying the teacher and incorporating the resulting guidance, the robot effectively expands its training data beyond the initial demonstrations, leading to improved robustness and performance in dynamic or unpredictable environments. This approach allows the robot to learn from its mistakes and adapt its behavior in real-time, a capability not readily achievable through passive observation alone.

FABCO: Aligning Demonstration with Physical Reality
The FABCO framework directly addresses the challenge of aligning demonstrated robotic motions with the robot’s physical capabilities by providing real-time feasibility feedback to the demonstrator. This feedback mechanism operates by assessing the demonstrated trajectory against the robot’s kinematic and dynamic limits, identifying potential execution failures before they occur. The system then communicates this information – whether through visual or haptic channels – allowing the demonstrator to modify the demonstrated motion and ensure it remains within the robot’s operational space. This iterative process of demonstration and feedback is crucial for generating robust policies, as it prevents the robot from attempting physically impossible or unstable maneuvers during learning and deployment.
The provision of real-time feasibility feedback, utilizing either visual or haptic modalities, directly improves a demonstrator’s awareness of the robot’s operational limits during policy learning. Visual feedback typically manifests as highlighted joint limits or predicted trajectory failures displayed to the user, while haptic feedback provides physical resistance or guidance when the demonstrated motion approaches an infeasible state. This allows the demonstrator to modify their movements proactively, avoiding commands that would likely result in robot failure and thereby shaping demonstrations that are inherently more aligned with the robot’s physical capabilities. Consequently, demonstrations incorporating this feedback loop result in policies that exhibit increased robustness and a higher probability of successful execution.
The FABCO framework utilizes a Robot Dynamics Model to anticipate potential execution failures during demonstration. This model predicts the outcome of demonstrated motions based on the robot’s physical limitations and environmental constraints. By analyzing predicted trajectories and forces, FABCO identifies scenarios likely to result in failure – such as collisions, joint limit violations, or unstable movements – and communicates this information to the demonstrator in real-time. This proactive feedback allows the demonstrator to modify the demonstrated motion, avoiding problematic actions and guiding the robot towards a feasible and successful policy. The resulting data, informed by predicted failures, improves the robustness and generalizability of the learned policy by reducing the occurrence of previously problematic states during deployment.
The FABCO framework has been validated through implementation on the Peg Insertion Task and the Circle Tracing Task, both considered complex robotic manipulation challenges. Quantitative results demonstrate a 3.2x improvement in task success rates when utilizing FABCO’s feasibility feedback mechanisms, as compared to scenarios where the demonstrator receives no feedback regarding the robot’s ability to execute demonstrated motions. This improvement represents a statistically significant performance increase across all demonstration methods tested within both tasks, indicating a consistent and reliable benefit derived from integrating feasibility information into the demonstration process.
Statistical analysis of FABCO’s implementation in both the Peg Insertion Task and the Circle Tracing Task revealed significant performance differences between demonstration methods. Specifically, comparisons utilized statistical tests to determine that the observed improvements in task success rates – averaging a 3.2x increase with feasibility feedback – were not due to random chance. These tests confirmed that the inclusion of either Visual Feedback or Haptic Feedback, coupled with the Robot Dynamics Model, resulted in demonstrably improved policy learning compared to demonstrations performed without feasibility information. The statistically significant p-values obtained across both tasks validate the effectiveness of FABCO in guiding demonstrators towards generating feasible and robust robotic policies.
![Learned policies demonstrate varying peg-insertion trajectories-achieved through combinations of visual, haptic, and no feedback-with successful insertions indicated by robot motion paths [latex] ext{(red lines)}[/latex] within the workspace [latex] ext{(green areas)}[/latex].](https://arxiv.org/html/2602.15351v1/x31.png)
Beyond Replication: Towards Resilient and Adaptive Systems
The FABCO framework leverages a Robot Dynamics Model as a core component, moving beyond simple feasibility checks to actively shape the learning process itself. This model doesn’t merely indicate whether a proposed action is physically possible for the robot; it provides nuanced feedback that guides the reinforcement learning algorithm towards more efficient and accurate solutions. By predicting the consequences of actions – how they will affect the robot’s state and trajectory – the model accelerates learning by prioritizing promising strategies and discarding those likely to fail. Consequently, the robot develops policies faster and achieves greater precision in its movements, ultimately leading to improved performance in complex tasks and dynamic environments.
FABCO leverages the power of predictive modeling through techniques like Action Chunking and Temporal Ensembling to significantly improve robotic learning. Action Chunking breaks down complex tasks into manageable, reusable segments, allowing the system to anticipate necessary actions with greater efficiency. Simultaneously, Temporal Ensembling builds upon this by creating a consensus of past policies, smoothing out fluctuations and increasing the robustness of the learning process. This combination not only enhances policy stability – reducing erratic movements and ensuring consistent performance – but also dramatically improves generalization, enabling the robot to adapt effectively to novel situations and variations in its environment. By effectively ‘looking ahead’ and anticipating future needs, FABCO fosters a more reliable and adaptable robotic skillset.
The foundation of the FABCO framework rests upon the strategic use of demonstration data, providing a robust starting point for robotic learning and significantly accelerating the training process. This initial data isn’t merely a static input; the system is designed to be intrinsically interactive, allowing it to actively solicit and integrate new demonstrations as needed. This continuous feedback loop facilitates ongoing refinement, enabling the robot to adapt to nuanced situations and improve performance over time. By combining pre-existing expert knowledge with real-time learning, FABCO moves beyond simple imitation and towards a truly adaptable skillset, capable of handling the complexities of dynamic environments and consistently improving its ability to execute tasks with greater precision and efficiency.
A key metric for evaluating FABCO’s performance lies in its ability to minimize the Hausdorff distance between the robot’s learned motions and those demonstrated by an expert. This distance, essentially measuring the maximum dissimilarity between two sets of points, exhibited a notable reduction when utilizing feasibility-aware policy learning. Lower Hausdorff distances indicate a closer alignment between the robot’s actions and the desired trajectory, signifying improved accuracy and precision in replicating complex movements. This quantitative improvement demonstrates that FABCO not only learns how to perform a task, but learns to do so with a fidelity that closely matches the demonstrated example, suggesting a robust and reliable learning process for intricate robotic manipulations.
The convergence of feasibility-aware policy learning, dynamic modeling, and temporal stability techniques within FABCO establishes a robust framework for next-generation robotics. This integrated approach doesn’t simply enable robots to replicate demonstrated actions, but empowers them to generalize those skills to previously unseen, and inherently unpredictable, scenarios. By anticipating dynamic changes and prioritizing physically plausible movements, FABCO facilitates the development of robots capable of navigating complex terrains, manipulating diverse objects, and adapting to disturbances with greater resilience. Consequently, the system moves beyond static task execution, paving the way for autonomous agents that can operate effectively and reliably within the messy, ever-shifting realities of real-world environments, opening doors to applications in fields ranging from manufacturing and logistics to search and rescue.
![Learned policies using FABCO successfully navigate peg insertion, with full demonstration data consistently yielding smoother trajectories [latex] ext{(c)}[/latex] within the workspace [latex] ext{(green)}[/latex] compared to those trained on only half the data [latex] ext{(a, b, d)}[/latex], demonstrating the benefit of feasibility-aware policy learning.](https://arxiv.org/html/2602.15351v1/x41.png)
The pursuit of robust robotic systems, as detailed in this work, echoes a fundamental truth about all complex creations. The FABCO framework, with its emphasis on feasibility-aware learning and multimodal feedback, doesn’t strive for a perfect, instantaneous replication of demonstrated behavior, but rather a graceful adaptation to the inherent limitations of physical systems. As Ken Thompson observed, “Sometimes it’s better to observe the process than to try to speed it up.” This resonates deeply; FABCO acknowledges that learning isn’t about eliminating challenges, but about developing a system capable of navigating them with increasing competence, allowing the robot to age gracefully into a more reliable and adaptable form.
What Lies Ahead?
The FABCO framework, as presented, represents a commitment-a particular version-in the ongoing chronicle of imitation learning. Each iteration refines the approach to bridging the reality gap, yet the fundamental tension remains: demonstration data, however enriched with feasibility feedback, is still a snapshot of a dynamic system. The observed motions, even with haptic guidance incorporated, represent a specific trajectory through state space, not necessarily a universal solution. Future work will undoubtedly explore methods for extrapolating beyond these constraints-for building policies that gracefully degrade rather than catastrophically fail when confronted with novelty.
A crucial, and often delayed, consideration lies in the meta-learning of feedback itself. The current paradigm assumes a fixed modality and interpretation of feasibility signals. However, the optimal feedback mechanism is likely task-dependent, even demonstrator-dependent. To truly age gracefully, these systems must learn how to ask for help-to actively refine the information provided by demonstrators, rather than passively accepting it. Each delay in addressing this is a tax on ambition, a compounding interest on the limitations of static datasets.
Ultimately, the field edges toward a consideration of embodiment itself. FABCO highlights the value of haptic feedback, yet it remains external to the learning process. The long view suggests a convergence of learning and control, where the robot not only observes skilled demonstrations but experiences them, building an internal model of feasibility that transcends the limitations of any single dataset.
Original article: https://arxiv.org/pdf/2602.15351.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- eFootball 2026 “Countdown to 1 Billion Downloads” Campaign arrives with new Epics and player packs
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Limbus Company 2026 Roadmap Revealed
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
2026-02-19 00:58