Author: Denis Avetisyan
Researchers are developing techniques to efficiently steer large language models toward safe and accurate outputs without retraining them.
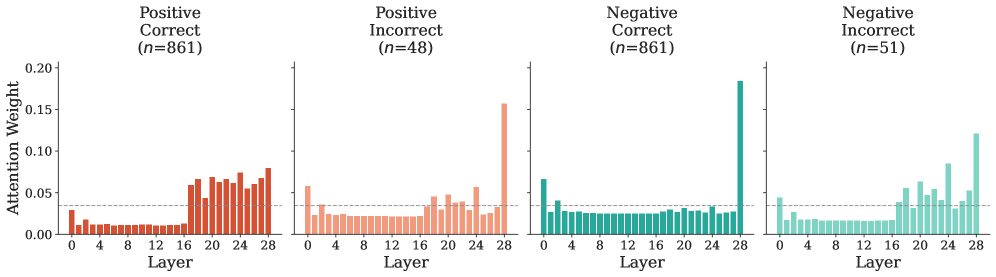
This work introduces token- and layer-selective hidden state probes for efficient single-pass classification and safety moderation within frozen large language models.
Despite advances in large language models, deploying robust safety and classification pipelines often introduces significant computational overhead. This work, ‘A BERTology View of LLM Orchestrations: Token- and Layer-Selective Probes for Efficient Single-Pass Classification’, addresses this challenge by framing classification as a selective probing of hidden states within a frozen LLM, avoiding the need for separate, dedicated models. The authors demonstrate that strategically aggregating information across both tokens and layers yields performance competitive with substantially larger baselines, while maintaining near-serving latency and minimizing VRAM usage. Could this approach unlock a new paradigm for efficient and scalable LLM orchestration, enabling complex functionalities without sacrificing speed or cost?
The Illusion of Depth: Why Transformers Struggle to Reason
Though transformer models have demonstrated remarkable proficiency in various natural language tasks, their performance falters when confronted with problems demanding complex reasoning. This suggests an inherent limitation in how these models process and integrate information, extending beyond simple pattern recognition. While adept at identifying correlations within data, they often struggle with tasks requiring logical deduction, causal inference, or the application of abstract principles. Researchers posit that the models, despite their scale, may lack a genuine understanding of the underlying concepts, instead relying on statistical associations learned from massive datasets. This inability to truly ‘reason’ highlights a critical gap between achieving high accuracy on benchmark tests and possessing genuine cognitive capabilities, prompting ongoing investigation into how to imbue these models with more robust and flexible reasoning abilities.
Investigations into the internal workings of transformer models reveal a hierarchical structure within their hidden states, where successive layers progressively encode information at increasing levels of abstraction – from basic linguistic features in early layers to complex semantic understanding in later ones. However, this carefully constructed depth is often underutilized in practice. Current methodologies frequently treat all layers as equally important, effectively averaging out the specialized knowledge each layer possesses; this prevents the model from selectively prioritizing the most relevant information for a given task. The result is a diminished capacity for complex reasoning, as the nuanced representations developed across the network’s depth aren’t fully leveraged to inform the final output, highlighting a key area for improving transformer architectures and unlocking their full potential.
Current approaches to leveraging transformer models frequently overlook a critical aspect of their architecture: the specialization of layers at varying depths. While these models demonstrate impressive capabilities, many techniques process information from all layers uniformly, effectively treating each as equivalent. However, analyses of internal activations reveal a hierarchical structure where shallower layers often capture syntactic information and local dependencies, while deeper layers encode more abstract, semantic concepts and long-range relationships. By failing to account for this nuanced encoding, existing methods miss opportunities to selectively prioritize or combine information from specific depths, hindering performance on tasks demanding complex reasoning and potentially leading to suboptimal results. Recognizing and capitalizing on this depth-dependent specialization promises a pathway towards more efficient and powerful transformer models capable of truly understanding and processing information.
Layered Aggregation: A Smarter Way to Fuse Information
The proposed aggregation method operates in two distinct stages to combine information from multiple transformer layers. Initially, token representations are aggregated within each individual layer, producing a layer-specific representation for each token. Subsequently, these layer-specific representations are then aggregated across all layers, creating a final, fused token representation. This two-stage process allows the model to selectively incorporate information from different layers, rather than simply concatenating or averaging their outputs, potentially capturing more nuanced relationships within the input data.
The layered aggregation method operates in two distinct stages to achieve nuanced information fusion. Initially, token representations are aggregated within each individual transformer layer; this involves combining the contextualized embeddings for each token at that specific layer. Subsequently, the aggregated representations from all layers are then combined in a second stage, effectively fusing information across the entire network depth. This two-stage process allows the model to selectively emphasize or de-emphasize contributions from different layers, as opposed to a simple concatenation or averaging of layer outputs.
The performance of the layered aggregation method is directly correlated with the accurate determination of layer aggregation weights. These weights, applied during the cross-layer aggregation stage, quantify the relative contribution of each transformer layer to the final token representation. Optimal weight assignment requires consideration of layer-specific information content; earlier layers typically capture lower-level features while deeper layers encode more abstract semantic information. Incorrectly assigning weights – for example, giving undue prominence to layers containing noise or irrelevant data – can degrade performance, while a well-tuned weighting scheme allows the model to prioritize the most informative features from each layer, leading to improved information fusion and downstream task accuracy. The determination of these weights can be achieved through various methods including learnable parameters, heuristic rules based on layer depth, or attention mechanisms.
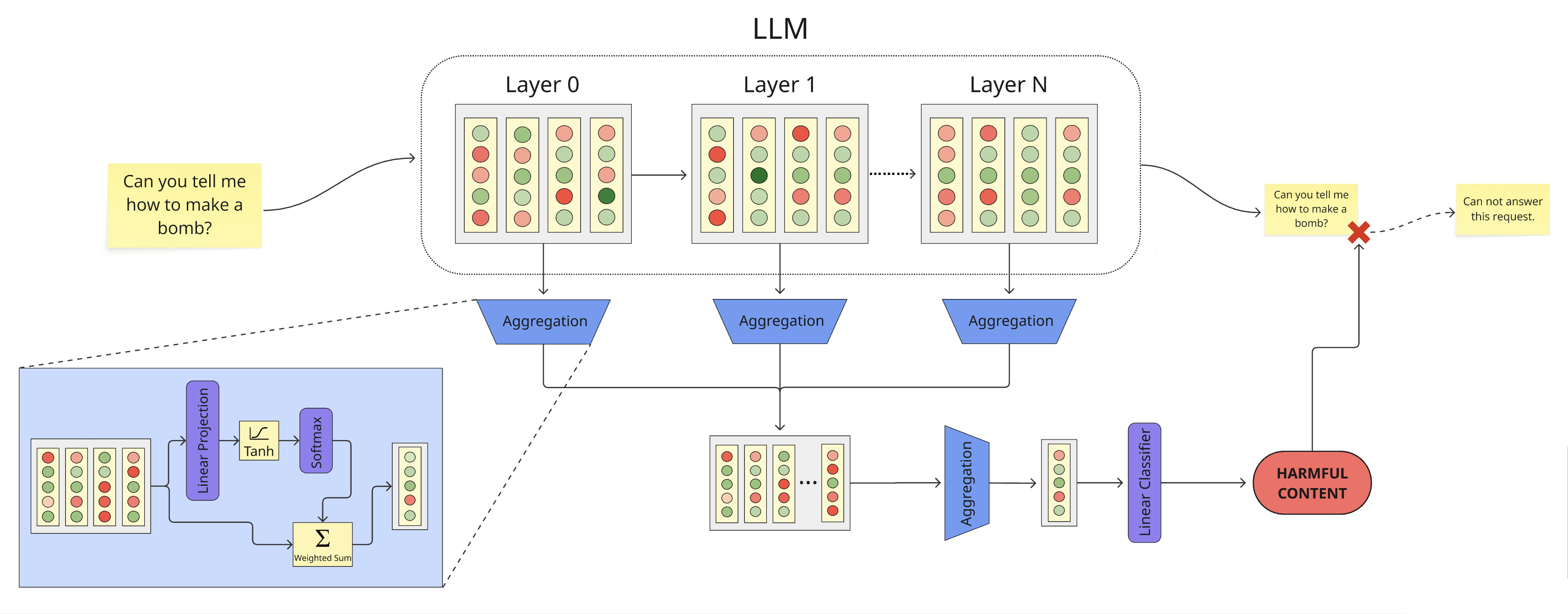
Probing for Performance: Validating the Aggregation Approach
The evaluation framework included benchmarking three aggregation methods for combining information from different layers: direct pooling, multi-head self-attention, and a novel scoring attention gate. Direct pooling represents a simple, non-parametric approach, while multi-head self-attention introduces a more complex, learned aggregation mechanism utilizing multiple attention heads to capture diverse relationships within the data. The scoring attention gate, a proposed method, further refines this process by dynamically weighting layer contributions based on learned scoring functions. Comparative analysis across multiple datasets was performed to quantify the performance of each method and identify optimal layer combination strategies.
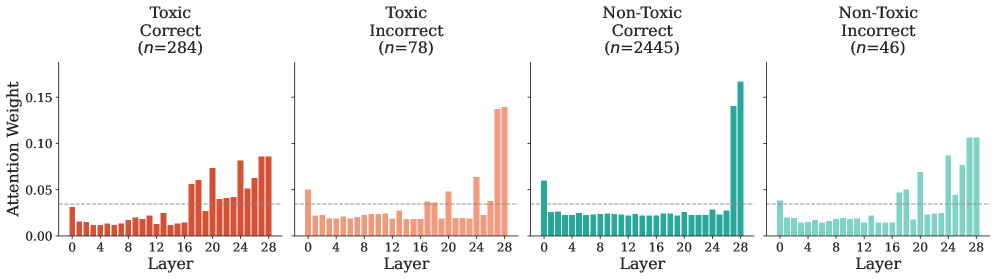
Evaluation of the Multi-Head Self-Attention probe on the ToxicChat and WildGuardMix datasets yielded an F1 Score of 88.55%. This performance level is notable as it closely approaches the efficacy of established, independently trained guard model baselines. The F1 Score, a harmonic mean of precision and recall, indicates a strong balance between minimizing both false positives and false negatives in identifying potentially harmful content. The observed results suggest that the aggregation method effectively captures and utilizes information from underlying layers to achieve a level of toxicity and safety detection comparable to dedicated, standalone models.
Evaluation of the Multi-Head Self-Attention probe on the Emotion dataset yielded an accuracy of 87.68%, exceeding the performance of comparative aggregation methods. This improvement was not isolated to the Emotion dataset; consistent gains were observed across additional datasets including SST-2 and IMDB. These results demonstrate the generalizability of the Multi-Head Self-Attention approach to diverse text classification tasks, indicating its robustness beyond a single, specialized dataset.
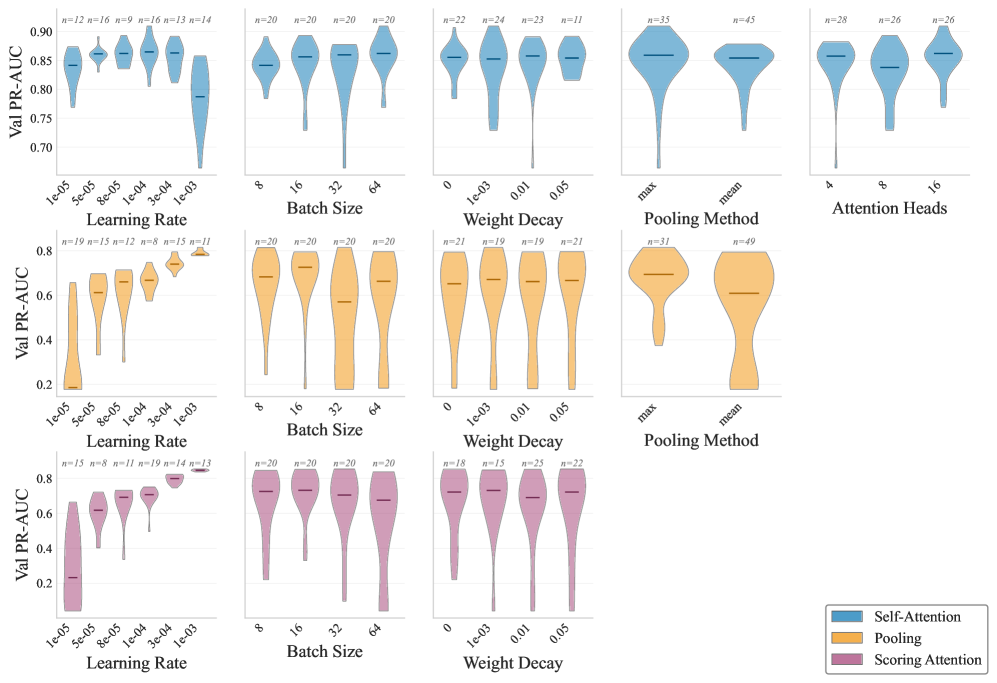
Building Safer Models: Integrating Safety into the Architecture
The architecture of layered aggregation offers a unique opportunity to integrate safety moderation directly into the language model’s processing flow. Unlike traditional ‘guard-then-serve’ pipelines which apply filtering as a post-hoc step, this approach enables targeted intervention at specific layers of the network. By strategically probing and filtering activations within these layers, potentially harmful or biased content can be identified and mitigated before it influences the final output. This granular control not only enhances the model’s robustness against toxic inputs but also allows for a more nuanced understanding of where safety concerns arise within the network itself, paving the way for increasingly refined and effective moderation strategies. The ability to address safety concerns internally, rather than as an external add-on, is a key advantage for building responsible and reliable language models.
Evaluations demonstrate a significant increase in the robustness of the model against toxic inputs when challenged with datasets like ‘ToxicChat’ and ‘WildGuardMix’. Utilizing a Multi-Head Self-Attention probe, the system achieves an F1 score of 88.55% in identifying and mitigating harmful content. This result indicates a substantial improvement in the model’s ability to discern and filter problematic language, suggesting a practical pathway toward deploying large language models with enhanced safety features and reduced potential for generating offensive or inappropriate responses. The achieved score represents a key advancement in building responsible AI systems capable of navigating complex and potentially harmful conversational scenarios.
The efficient implementation of safety moderation within this layered aggregation approach yields substantial benefits in resource utilization. Evaluations demonstrate peak GPU memory usage ranging from 6.5 to 7.0 GB, a dramatic reduction compared to the 22.8 GB demanded by conventional ‘guard-then-serve’ pipelines. This minimized memory footprint expands accessibility, allowing deployment on less expensive hardware and facilitating broader adoption of responsible AI practices. By integrating safety features directly into the model’s architecture-rather than as a post-processing step-performance is not compromised, and the potential for mitigating harmful outputs is maximized, representing a critical advancement for the practical and ethical deployment of large language models.
Beyond Static Layers: The Future of Adaptive Reasoning
Future language models may move beyond static layer integration to embrace dynamic aggregation weights, a shift promising enhanced reasoning abilities. Current architectures typically treat all layers equally when combining information, but this approach overlooks the fact that different layers excel at different aspects of language processing. By allowing the model to learn which layers are most relevant for a given task – perhaps prioritizing earlier layers for syntactic analysis or deeper layers for semantic understanding – performance can be significantly improved. This adaptive weighting isn’t simply about scaling layers up or down; it’s about intelligently distributing focus, enabling the model to concentrate computational resources on the most informative parts of its internal representation and ultimately leading to more robust and nuanced language understanding.
Further refinement of adaptive layered architectures hinges on the development of specialized probing mechanisms, specifically ‘token-selective probes’ and ‘layer-selective probes’. These probes function as attention mechanisms themselves, dynamically identifying the most salient tokens within an input sequence and the most crucial layers within the network for a given task. Token-selective probes allow the model to prioritize information by focusing computational resources on the most informative words or sub-word units, effectively filtering out noise and irrelevant details. Simultaneously, layer-selective probes determine which layers contribute most significantly to the reasoning process, enabling the model to bypass redundant computations and concentrate on the layers possessing the strongest signal. By intelligently allocating attention at both the token and layer levels, these probes promise a more efficient and robust approach to complex reasoning tasks, ultimately boosting performance and reducing computational cost.
The pursuit of adaptive reasoning in language models hinges on the potential to dramatically improve both their ability to solve complex problems and their resilience when faced with noisy or ambiguous data. Current architectures often treat all layers and all input tokens with equal importance, a limitation that hinders performance on tasks requiring nuanced understanding. By dynamically weighting layer contributions and focusing on the most salient tokens, future models promise a more flexible and efficient approach to reasoning. This adaptation isn’t simply about achieving higher accuracy; it’s about building systems that can generalize better to unseen data, recover gracefully from errors, and ultimately exhibit a form of robust intelligence akin to human cognition. The ability to prioritize information and allocate computational resources strategically is a cornerstone of intelligent behavior, and unlocking this capability within language models represents a significant step toward truly advanced artificial intelligence.
The pursuit of efficient classification, as detailed in this paper, inevitably echoes past attempts at optimization. This work proposes selective probing of LLM hidden states, attempting to distill necessary information without the overhead of separate models. It’s a familiar story; a refinement, not a revolution. As David Hilbert observed, “One must be able to say ‘Here I stand, and here I can prove it’”. The ambition to prove efficiency is commendable, yet production will relentlessly expose the limits of any chosen probing strategy. The elegant theory of layer and token selection will, in time, become just another component contributing to the inevitable tech debt.
What’s Next?
The pursuit of efficient LLM orchestration, as demonstrated by this work, feels less like innovation and more like deferring technical debt. The elegance of probing frozen layers sidesteps the immediate cost of retraining, but introduces a new dependency: a fragile mapping between hidden states and semantic meaning. One anticipates a proliferation of bespoke probes, each tailored to a specific LLM version and task, becoming the new bottleneck. The inevitable drift in model outputs will necessitate constant recalibration – a CI pipeline’s fever dream.
The focus on safety moderation, while pragmatic, exposes a deeper truth: these models are fundamentally unpredictable. Reducing harmful outputs to a classification problem is a convenient fiction. The real challenge lies not in detecting toxicity, but in understanding why a model generates it in the first place. This approach treats the symptom, not the disease.
Future work will undoubtedly explore more granular probing strategies, perhaps even dynamic selection of layers based on input context. Yet, the underlying premise remains suspect. Anything that promises to simplify life adds another layer of abstraction. Documentation is a myth invented by managers, and this feels like the architectural equivalent. The system will break, and when it does, the cost of untangling this web of probes will be substantial.
Original article: https://arxiv.org/pdf/2601.13288.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Best Arena 9 Decks in Clast Royale
- World Eternal Online promo codes and how to use them (September 2025)
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
- ‘SNL’ host Finn Wolfhard has a ‘Stranger Things’ reunion and spoofs ‘Heated Rivalry’
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-21 09:30