Author: Denis Avetisyan
New research explores how carefully designed prompts can significantly improve a robot’s ability to navigate social spaces safely and effectively.

This review investigates the impact of prompt engineering on vision-language models for socially compliant robot navigation, finding optimal strategies vary based on model finetuning.
While large language models show promise for robot navigation, a critical gap remains in understanding how to effectively design prompts for socially compliant behavior, particularly with computationally efficient, smaller models. This work, ‘Probing Prompt Design for Socially Compliant Robot Navigation with Vision Language Models’, systematically investigates prompt engineering along dimensions of system guidance and motivational framing to optimize performance on socially aware navigation tasks. Results reveal that optimal prompting strategies-leveraging competition against humans or a model’s past self-depend on whether the vision-language model is finetuned, and that well-designed prompts can even outperform finetuning in improving action accuracy. Can these findings unlock more robust and adaptable socially intelligent robots capable of navigating complex human environments?
Robots and Humans: The Inevitable Awkwardness
Conventional robotic navigation systems prioritize efficient path planning, often neglecting the subtle, yet critical, social signals that govern human movement. This oversight can result in robots exhibiting behaviors perceived as awkward, intrusive, or even dangerous by people nearby. A robot adhering strictly to the shortest route, for instance, might cut directly in front of a pedestrian, fail to yield to established walking patterns, or maintain an uncomfortably close proximity-actions considered impolite or threatening in human-human interaction. Consequently, these systems struggle in dynamic, crowded environments where anticipating and responding to unstated social norms is paramount for safe and seamless coexistence. Addressing this limitation requires incorporating models of human social behavior into the robot’s navigational framework, enabling it to not only reach a destination, but to do so in a manner that respects and accommodates the surrounding social landscape.
Truly effective robotic navigation within human environments transcends simple path planning and obstacle avoidance. It necessitates a nuanced understanding of human social behaviors – not merely detecting people, but predicting their likely movements and intentions. A robot operating successfully in a crowded space must anticipate how individuals will react to its presence, adjusting its trajectory to avoid collisions and, crucially, to maintain a comfortable social distance. This demands algorithms capable of interpreting subtle cues like gaze direction, body language, and conversational groupings, effectively modeling human behavior to navigate not just physically, but socially, ensuring interactions are perceived as safe, predictable, and considerate. Consequently, the challenge lies in creating robots that aren’t simply ‘aware’ of people, but proactively responsive to the complex, often unspoken, rules governing human spatial interaction.
The development of robots capable of navigating human-populated spaces relies heavily on robust datasets like MUSON and SNEI, which provide crucial real-world observations of pedestrian behavior and complex social interactions. However, these datasets aren’t without their difficulties; they often feature inherent biases reflecting specific locations or demographics, and capturing the full nuance of human unpredictability remains a significant hurdle. Furthermore, the sheer volume and dimensionality of the data-including visual information, motion trajectories, and contextual cues-demand sophisticated machine learning techniques for effective processing. Successfully training robots on these datasets requires not just algorithms capable of recognizing patterns, but also methods for generalizing those patterns to novel situations and accounting for the inherent uncertainty in predicting human actions, ultimately paving the way for more intuitive and safe robotic navigation.
Current approaches to robotic navigation frequently falter when bridging the gap between seeing the environment and understanding the intentions of people within it. While robots can now reliably process visual data to identify pedestrians and obstacles, translating this perception into nuanced, socially-aware behavior remains a significant hurdle. The difficulty lies in the need for robust high-level reasoning – the ability to infer goals, predict trajectories, and anticipate social norms – all while operating in real-time. Existing systems often treat perceptual input and logical reasoning as separate modules, creating a bottleneck where crucial contextual information is lost or misinterpreted, leading to hesitant movements, unexpected stops, or even potentially unsafe interactions. This disconnect prevents robots from seamlessly integrating into human spaces and necessitates the development of more holistic architectures capable of unified perception and reasoning.

Vision-Language Models: A Band-Aid on a Broken System?
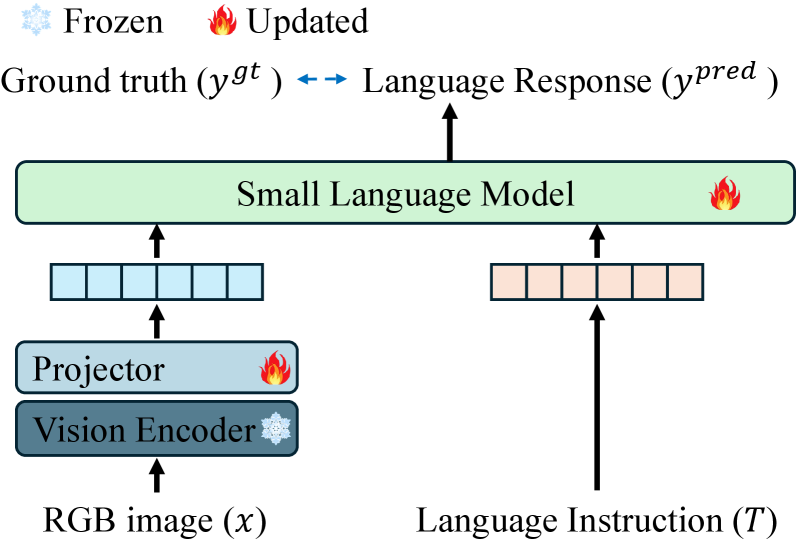
Vision Language Models (VLMs) integrate computer vision and natural language processing to enable robots to interpret visual input and reason about it using language. This is achieved by training models on large datasets of image-text pairs, allowing them to establish correlations between visual features and linguistic concepts. Consequently, a VLM can process images to generate textual descriptions, answer questions about visual scenes, or, critically for robotics, receive language-based instructions related to visual tasks. This capability moves beyond traditional robotic systems reliant on predefined actions triggered by specific sensor readings, allowing for more flexible and adaptable navigation based on high-level linguistic commands and contextual understanding of the environment.
TinyLLaVA is a lightweight, open-source framework designed to facilitate the fine-tuning of large vision-language models (VLMs) for robotic applications. It leverages a modular architecture, enabling researchers and developers to adapt pre-trained VLMs – initially trained on extensive image-text datasets – to specific robotic tasks with limited computational resources. The framework employs a technique called visual instruction tuning, where the VLM is further trained on a dataset of paired visual inputs and corresponding textual instructions relevant to the desired robotic behavior. This process optimizes the VLM’s ability to interpret visual information and generate appropriate actions or responses, effectively bridging the gap between perception and action in robotic systems. The reduced parameter size of TinyLLaVA, compared to larger VLMs, makes it more accessible for deployment on edge devices and resource-constrained robots.
Vision Language Models (VLMs) process visual input from onboard sensors, such as cameras, and integrate this data with natural language processing capabilities. This allows the robot to not only detect objects and features within its environment, but also to interpret those observations in the context of linguistic instructions or queries. Consequently, decision-making extends beyond pre-programmed responses to situations; robots equipped with VLMs can assess environments based on descriptive language, enabling responses to complex, nuanced requests and adapting behavior to previously unseen circumstances. The integration of vision and language facilitates contextual awareness, improving performance in dynamic and unstructured environments.
While Vision Language Models (VLMs) provide a foundational capability for robots to interpret visual input and language commands, achieving reliable performance necessitates careful prompt engineering. The specific phrasing of instructions, including the level of detail and the inclusion of contextual information, significantly impacts the VLM’s output and, consequently, the robot’s actions. Insufficiently detailed or ambiguous prompts can lead to unpredictable behaviors, while well-crafted prompts guide the VLM to focus on relevant features and generate appropriate responses for task completion. This process often involves iterative refinement, testing various prompt structures and keywords to optimize performance for specific robotic applications and environments; simply providing a general command is rarely sufficient for consistent, accurate execution.
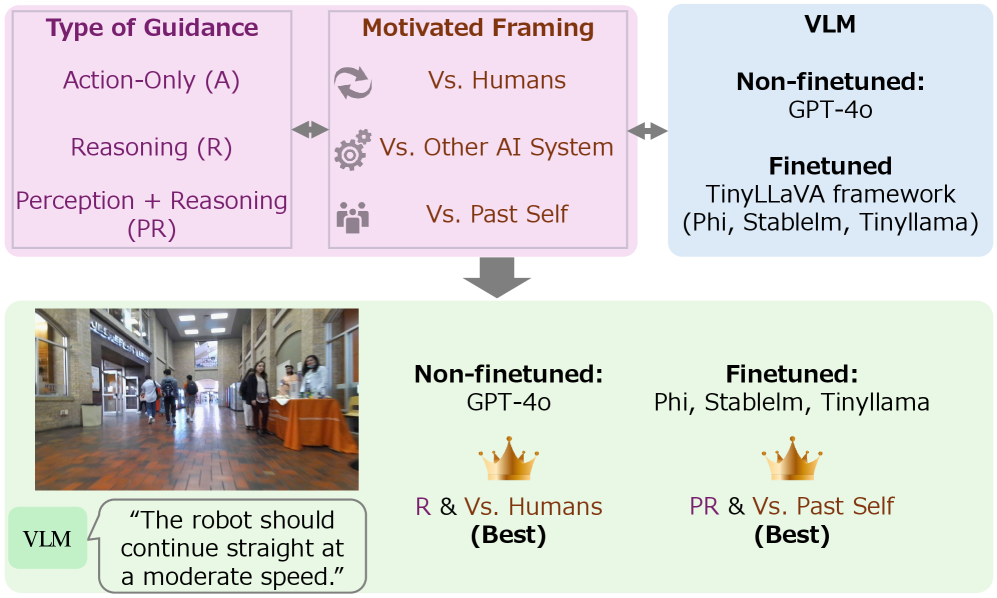
Prompting for Politeness: A Fragile Facade?
Perception-Reasoning Prompts and Reasoning-Oriented Prompts are techniques designed to improve the contextual awareness of Visual Language Models (VLMs) prior to action execution. These prompting strategies explicitly instruct the model to first analyze the surrounding environment – identifying relevant objects, agents, and spatial relationships – before generating a response or navigation command. By decoupling perception from action, these prompts encourage a more deliberate processing of visual information, leading to improved decision-making and a reduction in impulsive or contextually inappropriate behaviors. The model is effectively prompted to “think” about the scene before acting, enabling it to better anticipate consequences and plan feasible trajectories.
Action-Focused Prompts are utilized to limit the scope of a Visual Language Model’s (VLM) output specifically to executable navigation commands. These prompts achieve this by structuring the request to prioritize the generation of actions – such as “turn left”, “go forward”, or “stop” – rather than descriptive or interpretive responses. By explicitly requesting a sequence of feasible actions, the model is constrained to produce outputs directly applicable to robot navigation, reducing the likelihood of generating abstract or impractical instructions. This constraint improves the reliability and efficiency of VLMs in real-world navigation tasks by ensuring the generated output conforms to the action space of the robotic system.
Motivational framing, specifically the introduction of competitive elements within prompting strategies, has demonstrated quantifiable improvements in VLM performance during social navigation tasks. This technique involves structuring prompts to encourage the model to optimize for outcomes beyond simply reaching a goal, such as minimizing completion time or maximizing efficiency relative to a simulated “opponent.” Empirical results from models like VLM-Social-Nav and MAction-SocialNav indicate that competition-based prompts lead to statistically significant gains in both trajectory optimality and social compliance, as measured by metrics including path length, collision rate, and adherence to social norms regarding personal space and yielding to other agents. The competitive framing appears to act as a refinement mechanism, encouraging the VLM to explore and select actions that not only achieve the navigational objective but also demonstrate enhanced strategic behavior.
VLMs, specifically VLM-Social-Nav and MAction-SocialNav, have been empirically shown to produce navigation trajectories that adhere to social norms when utilizing the aforementioned prompting strategies. VLM-Social-Nav achieves this by integrating perception and reasoning prompts to analyze pedestrian behavior and predict future movements, allowing the agent to proactively avoid collisions and maintain a safe distance. MAction-SocialNav further refines this approach with action-focused prompts that constrain the output space to feasible actions, combined with motivational framing, resulting in demonstrably more socially compliant and efficient navigation in simulated pedestrian environments. Quantitative evaluations, utilizing metrics such as collision rate and average distance to pedestrians, consistently demonstrate statistically significant improvements in social compliance when these prompting techniques are implemented compared to baseline VLM navigation models.
Metrics and Mirages: What Does Success Actually Look Like?
Objectively assessing the capabilities of Vision-Language Model (VLM)-driven navigation systems requires a suite of carefully chosen metrics. While semantic understanding is important, evaluating performance solely on language alignment can be misleading; therefore, metrics like BERT-F1 and SBERT, which measure the similarity between predicted and ground truth text, must be complemented by action-oriented assessments. Crucially, Action Accuracy – a direct measure of whether the robot performs the correct navigational action – provides a vital indicator of real-world success. These quantitative measures allow researchers to move beyond subjective evaluations and systematically compare different models, prompt designs, and training methodologies, ultimately driving progress towards robust and reliable autonomous navigation. Without such rigorous evaluation, improvements in language processing may not translate to meaningful gains in a robot’s ability to navigate complex environments.
Recent advancements in Vision-Language Models (VLMs) have yielded navigation systems exhibiting increasingly sophisticated spatial reasoning. Models such as AutoSpatial and OLiVia-Nav don’t simply react to visual inputs; they actively construct an internal representation of the environment, enabling them to plan trajectories that are both efficient and natural. This capability moves beyond basic obstacle avoidance, allowing these systems to anticipate future states and select actions that optimize for long-term goals. By integrating geometric understanding with linguistic instructions, these models demonstrate a marked improvement in path smoothness and a reduction in unnecessary maneuvers, paving the way for more reliable and human-compatible robotic navigation in complex and dynamic spaces.
Reinforcement Learning presents a compelling pathway to elevate the performance of Vision-Language Models (VLMs) in challenging navigational scenarios. By framing navigation as a sequential decision-making process, VLMs can be trained to iteratively refine their actions based on rewards received from interacting with an environment. This approach allows models to move beyond simply understanding instructions and instead learn optimal strategies for achieving goals, even when faced with uncertainty or dynamic obstacles. Unlike supervised learning, which relies on pre-defined correct actions, reinforcement learning enables VLMs to discover effective navigational policies through trial and error, leading to more robust and adaptable performance in complex, real-world settings. The technique effectively transforms the VLM from a passive interpreter of language into an active agent capable of intelligent, autonomous navigation.
The practical implementation of Vision-Language Models (VLMs) for robotic navigation hinges on computational efficiency, particularly when deploying these systems on robots with limited processing power and battery life. Models like SocialNav-MoE address this challenge through the innovative application of Mixture-of-Experts (MoE), a technique that selectively activates only a fraction of the model’s parameters for each input. This sparse activation significantly reduces computational demands without sacrificing performance, enabling complex navigational tasks to be executed on resource-constrained platforms. By strategically distributing parameters and activating only the relevant “experts” for a given scene or instruction, SocialNav-MoE demonstrates a pathway toward scalable and energy-efficient VLM-driven navigation, bringing sophisticated robotic intelligence closer to real-world deployment.
Evaluations reveal that strategically crafted prompts significantly enhance Action Accuracy (AA) in Vision-Language Model (VLM)-driven navigation systems, highlighting the crucial role of prompt engineering. Gains in AA, a direct measure of successful navigational actions, were notably larger in finetuned models compared to improvements observed in semantic metrics such as BERT-F1 and SBERT. This suggests that carefully designing prompts to elicit specific actions has a more substantial impact on performance than simply improving the model’s understanding of language or semantic alignment; the system excels at doing when explicitly guided, even beyond improvements in understanding the instructions. These findings emphasize the potential for optimizing VLM navigation not only through model refinement but also through sophisticated prompt design tailored to action-oriented tasks.
The pursuit of socially compliant robot navigation, as demonstrated in this research, feels predictably fraught. It’s another elegant theory heading straight for production’s brick wall. This paper meticulously dissects prompt engineering for vision-language models – a fine effort, certainly – but one can’t help but anticipate the edge cases. As Carl Friedrich Gauss observed, “If I have seen as far as others, it is by standing on the shoulders of giants.” This feels applicable; each incremental improvement in prompting is built upon previous work, yet the ‘giant’ of real-world unpredictability remains. The study highlights differing optimal prompting strategies based on finetuning, which merely suggests the system is learning to appear compliant, not necessarily be it. Better one carefully tested rule than a thousand nuanced prompts, one suspects.
The Road Ahead
The exercise of coaxing socially acceptable behavior from a robot via cleverly worded text prompts is… predictably complex. The observed divergence in optimal prompting strategies based on finetuning status suggests a fundamental truth: a larger model doesn’t inherently understand social norms; it merely becomes a more sophisticated mimic. And, like all mimics, it requires distinct instruction depending on its prior training. The current reliance on painstakingly crafted prompts feels less like artificial intelligence and more like digital ventriloquism. It works, after a fashion, until someone walks into the frame wearing a brightly colored hat.
Future work will undoubtedly explore automating prompt generation – essentially teaching the robot to negotiate its own behavioral parameters. The inevitable arms race between prompt optimization and adversarial testing will be… entertaining, at least for those not directly in the robot’s path. It’s worth remembering that ‘social compliance’ is a moving target, varying wildly by culture and individual preference. The quest for a universally ‘polite’ robot may be as futile as searching for a perfect algorithm.
Ultimately, this line of inquiry highlights a critical point: the real challenge isn’t building robots that appear social, but building systems robust enough to handle the inevitable chaos of real-world interaction. If a robot consistently crashes into things in a predictable manner, at least it’s predictable. The current emphasis on elegant prompting feels… optimistic. One suspects future generations of roboticists will view these early efforts as charmingly naive, much like digital archaeologists examining the legacy code of a bygone era.
Original article: https://arxiv.org/pdf/2601.14622.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- Gold Rate Forecast
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Magicmon: World redeem codes and how to use them (March 2026)
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Invincible Creator on Why More Spin-offs Haven’t Happened Yet
- Simulating Humans to Build Better Robots
2026-01-22 13:16