Author: Denis Avetisyan
Researchers have developed a new framework enabling humanoid robots to dynamically generate gestures that align with spoken emotion, creating more natural and engaging interactions.
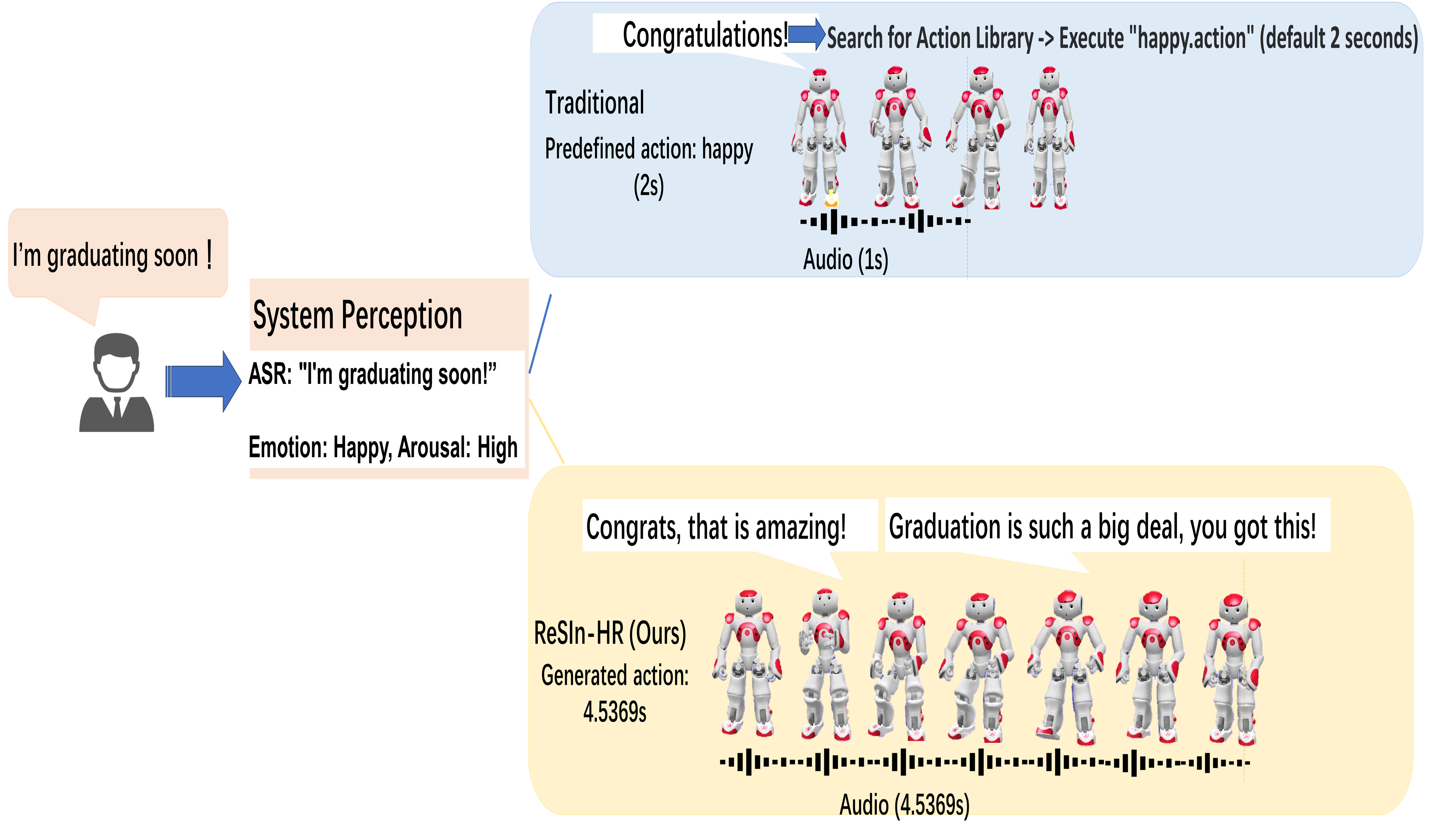
The ReSIn-HR framework integrates speech emotion recognition, adaptive gesture planning, and biomechanical constraints for synchronized, real-time human-robot interaction.
Achieving truly natural human-robot interaction requires more than simply responding to commands; it demands emotionally resonant and temporally coordinated behavior. This is addressed in ‘Real-Time Synchronized Interaction Framework for Emotion-Aware Humanoid Robots’, which introduces a novel framework, ReSIn-HR, for generating synchronized multimodal expressions in real-time. By integrating large language models with biomechanically-constrained gesture planning and duration-aware temporal alignment, the system demonstrates a 21% improvement in emotional alignment compared to rule-based approaches. Could this framework unlock more seamless and intuitive social interactions, ultimately expanding the role of humanoid robots in areas like healthcare and education?
Deconstructing Expression: The Illusion of Natural Movement
Conventional methods of synthesizing robotic gestures frequently depend on either explicitly programmed rules or statistical analysis of motion capture data, yet often fall short of replicating the subtleties of human expression. These approaches, while capable of generating basic movements, struggle to capture the delicate interplay between emotion, timing, and fluidity that characterizes natural human communication. Predefined rules can result in rigid and predictable gestures, while statistical learning, though more adaptable, frequently produces movements lacking emotional nuance or temporal coherence – the subtle shifts in speed and rhythm that convey meaning. Consequently, robotic gestures generated through these means can appear mechanical and disconnected, failing to fully complement the spoken word or effectively communicate the intended emotional state.
Human communication isn’t simply the transmission of words; it’s a richly layered process where gestures act as an inseparable component of spoken language. Research indicates that the subtle nuances of speech – its prosody, encompassing rhythm, stress, and intonation – are intrinsically linked to the timing, shape, and intensity of accompanying gestures. Emotional state further complicates this interplay, as feelings aren’t solely expressed through vocal cues but are also powerfully conveyed through non-verbal signals embedded within bodily movement. This means a gesture isn’t merely added to speech, but rather is often informed by it, arising as a natural extension of the speaker’s emotional and linguistic intent – a complexity that proves challenging to replicate in artificial systems designed to mimic natural communication.
The creation of convincing robotic gestures hinges on more than simply mimicking human movement; it demands a meaningful connection between what is said and how it is expressed through the body. Researchers confront the considerable challenge of ensuring that robotic gestures aren’t merely visually pleasing, but actively reinforce and clarify the spoken message. This requires algorithms capable of interpreting the nuances of speech – not just the literal words, but also the emotional tone and subtle prosodic cues – and translating them into corresponding physical expressions. A disconnect between speech and gesture can lead to confusion or even distrust, while a harmonious congruence enhances communication and fosters a sense of natural interaction. The ultimate goal is to build robots capable of delivering messages with the same expressiveness and clarity as a human speaker, effectively bridging the gap between verbal and nonverbal communication.
Current robotic gesture synthesis frequently produces movements that lack the fluidity and believability of natural human expression due to difficulties in harmonizing emotional nuance, precise timing, and the constraints of physical possibility. Many systems prioritize visual aesthetics or grammatical correctness without fully accounting for the subtle interplay between spoken word and bodily expression; this often results in robotic gestures that feel either emotionally flat or mechanically awkward. A core issue lies in the complexity of replicating the human capacity to dynamically adjust gesture timing and intensity based on both the semantic content and the emotional weight of speech. Without a robust integration of these factors, and a consideration for realistic biomechanical limitations, robotic movements can appear disjointed and fail to effectively convey the intended message, hindering truly natural human-robot interaction.
![Smoother, more natural gestures are correlated with lower mean angular jerk [latex] (rad/s^3) [/latex] across expressed emotions.](https://arxiv.org/html/2601.17287v1/Figures/jerk_barplot_resinhr_ieee_fixed.png)
ReSIn-HR: Orchestrating Synchronized Expression
ReSIn-HR utilizes Large Language Models (LLMs) to address the inherent disconnect between linguistic meaning and appropriate non-verbal expression in robotic communication. Specifically, the framework employs LLMs to parse spoken language and infer the communicative intent, emotional state, and contextual relevance of the utterance. This semantic analysis then informs the selection and parameterization of robotic gestures, moving beyond simple keyword-to-action mappings. By leveraging the LLM’s understanding of natural language nuances, ReSIn-HR enables the generation of gestures that are not only semantically aligned with the speech content but also contextually appropriate, contributing to more natural and expressive robotic behavior. The LLM’s capacity for contextual understanding is critical in situations where multiple gestures could be applicable, allowing the system to choose the most fitting response based on the broader conversational context.
The ReSIn-HR framework utilizes a Dual-Stream Emotion Processing pipeline to interpret communicative intent from both verbal and non-verbal cues. Linguistic content, derived from speech recognition, is analyzed for semantic meaning and emotional sentiment. Simultaneously, speech prosody – encompassing features like intonation, rhythm, and stress – is extracted and assessed for emotional valence and arousal levels. These two streams of information are then integrated to determine the appropriate gesture selection and dynamic adaptation, allowing the system to generate robotic movements that are contextually aligned with the communicated message and emotional state.
ReSIn-HR utilizes a dynamic duration prediction system to synchronize robotic gestures with spoken language. This system analyzes incoming speech to forecast its total duration, and subsequently adjusts the timing of gesture keyframes to align with the predicted speech length. Evaluation has demonstrated a Temporal Synchronization Accuracy (TSA) of 218ms, measured as the average absolute difference between the end of a speech segment and the completion of its corresponding gesture. This level of precision is achieved through continuous recalculation of gesture timing based on real-time speech analysis, enabling a more natural and fluid interaction between the robot and a human interlocutor.
Biomechanical Constraint Verification within ReSIn-HR operates by evaluating generated gesture keyframes against a pre-defined operational space for the NAO Robot. This process utilizes forward kinematics to determine if joint angles and velocities remain within safe and physically achievable limits; exceeding these limits results in gesture modification or rejection. Specifically, the system checks for joint angle violations, velocity constraints, and potential collisions with the robot’s own body, ensuring all movements fall within the NAO’s documented range of motion – typically ±90 degrees for most joints and a maximum velocity of 50 degrees per second. This verification step is critical for preventing motor overload, maintaining robot stability, and ensuring the longevity of the hardware.
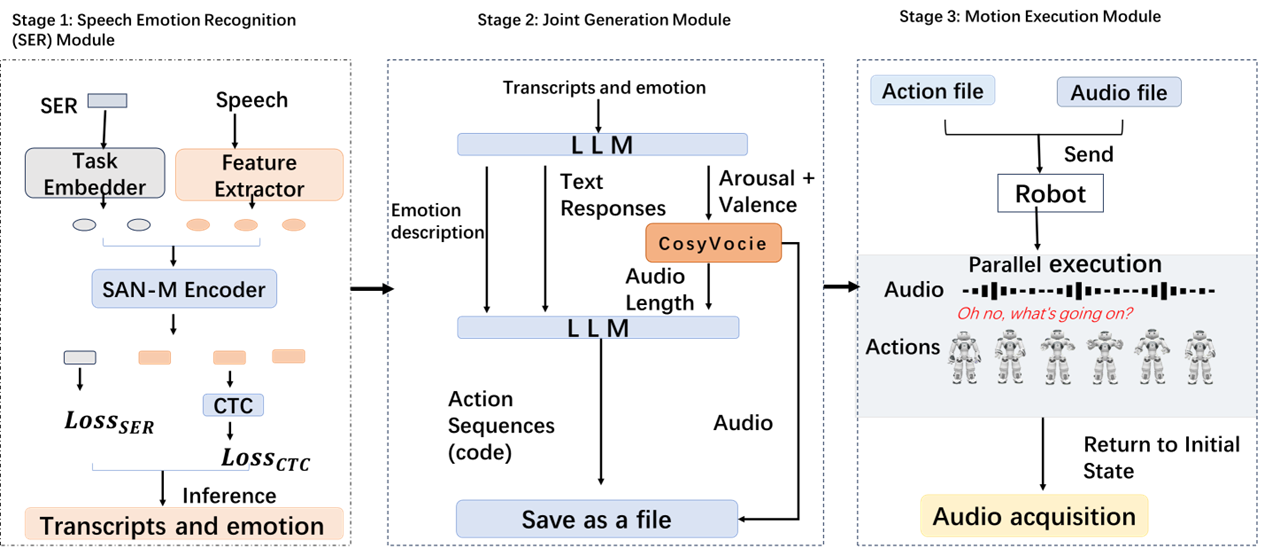
LLMs as the Engine: Policy Generation and Control – A System Unbound
The ReSIn-HR system utilizes Large Language Models (LLMs) as its primary control mechanism, translating high-level directives into executable robotic actions. This is achieved through the generation of “Code-as-Policies,” where LLMs output code directly interpreted by robotic control systems, such as RT-2. Rather than relying on pre-programmed behaviors, the LLM dynamically creates policies based on input, allowing for adaptable and nuanced robotic behavior. This approach facilitates direct control over robotic actuators and movements, bypassing the need for intermediate behavior trees or state machines and enabling a more flexible and responsive system.
MoFusion improves gesture generation by integrating Large Language Models (LLMs) with additional models, specifically diffusion models. This combination allows for the creation of more detailed and varied gestures than achievable with LLMs alone. The diffusion model receives a latent representation generated by the LLM, and then refines this representation into a high-fidelity gesture. This process enables the generation of nuanced movements, including subtle variations in timing, velocity, and articulation, resulting in more expressive and realistic robotic behavior. The architecture facilitates a decoupling of high-level intent, defined by the LLM prompt, from the low-level details of gesture execution, enhancing the overall sophistication of the system.
Prompt engineering is central to achieving desired robotic behaviors within the ReSIn-HR system. Specifically, carefully constructed prompts direct the Large Language Model (LLM) to generate gesture sequences that accurately convey intended emotional states and communicative intent. These prompts incorporate parameters defining desired emotional expression-such as happiness, sadness, or anger-and the specific communicative goal of the gesture, like greeting, requesting, or apologizing. The LLM interprets these parameters and translates them into actionable gesture commands. Iterative refinement of prompt structures is necessary to minimize ambiguity and ensure the generated gestures consistently align with the specified emotional and communicative objectives, improving the fidelity of robotic social expression.
ReSIn-HR utilizes Large Language Models (LLMs) to facilitate robotic expression that extends beyond pre-programmed gesture libraries. Instead of relying on static templates, the system generates robotic movements dynamically based on input prompts, allowing for a potentially infinite range of expressive actions. This capability is achieved by translating natural language instructions into executable code that directly controls the robot’s actuators. Consequently, the system can adapt robotic behavior to specific conversational contexts and intended emotional states, creating more nuanced and responsive interactions than traditional, template-based approaches allow. The LLM’s generative capacity enables the creation of novel gestures tailored to the current situation, rather than being limited to a fixed repertoire.

The Illusion of Life: Naturalness Through Smoothness, Feasibility, and Emotional Resonance
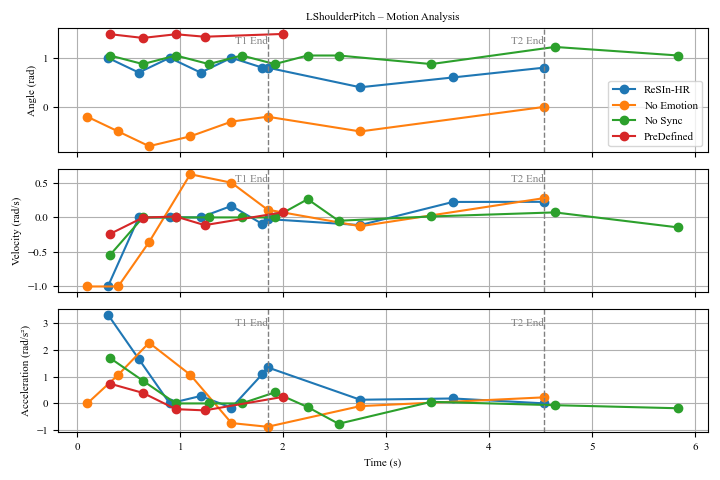
To produce convincingly realistic movements, the system rigorously verifies biomechanical constraints throughout the gesture generation process. This involves a constant assessment of the robot’s physical limitations – its joint limits, range of motion, and velocity capabilities – ensuring that all proposed actions are physically achievable. By adhering to these constraints, the system effectively prevents the creation of jerky, unnatural, or even impossible movements. This careful consideration of robotic anatomy results in smoother, more fluid gestures that closely mimic human motion, enhancing the overall believability and naturalness of the robot’s interactions. The system doesn’t simply plan a movement, but a movement the robot can actually perform, thereby avoiding awkwardness and maintaining a sense of physical realism.
Achieving realistic movement necessitates not only physically plausible trajectories, but also a focus on how those movements feel to observe. The ReSIn-HR framework addresses this through meticulous optimization of gesture smoothness, specifically by minimizing [latex]Jerk[/latex] – the rate of change of acceleration. High jerk values manifest as abrupt, jarring motions that appear unnatural, even if physically possible. By mathematically controlling and reducing jerk throughout a generated gesture, the system creates fluid, more human-like movements. This careful attention to the dynamics of motion ensures that gestures aren’t simply possible, but are perceived as graceful and organic, significantly contributing to the overall believability of the robot’s non-verbal communication.
ReSIn-HR significantly enhances the connection between spoken words and accompanying gestures through a focused alignment of emotional content. The system doesn’t simply map gestures to speech; it analyzes the emotional nuance within the speech and generates movements that are congruent with those feelings. This approach yields a demonstrable 21% improvement in Emotion Compatibility (EC) when contrasted with traditional rule-based systems, which often rely on pre-defined gesture sets irrespective of the speaker’s emotional state. By prioritizing emotional resonance, ReSIn-HR creates more believable and engaging interactions, moving beyond mechanically correct motions to gestures that genuinely feel connected to the message being conveyed.
The generation of convincingly natural full-body movement benefits significantly from the implementation of Human Motion Diffusion Models (HMDMs). These models excel at producing temporally coherent gestures, meaning movements flow smoothly and logically over time, while simultaneously maintaining stylistic consistency throughout an interaction. Rigorous user studies validate this approach; evaluations revealed a high degree of appropriateness, with generated gestures achieving a score of 4.5 on the Gesture Appropriateness (GA) scale. Further bolstering these findings, overall naturalness, as assessed by participants, reached an impressive 4.6 on the Overall Naturalness (ON) scale, indicating a strong perception of realism and believability in the synthesized human motion.
The development of ReSIn-HR exemplifies a fascinating dismantling of conventional boundaries within human-robot interaction. The framework doesn’t simply accept the established limitations of robotic gesture generation; it actively probes and overcomes them through the integration of speech emotion recognition and real-time biomechanical verification. This approach resonates with the sentiment expressed by Blaise Pascal: “The eloquence of a man lies not in what he says, but in how he says it.” Just as Pascal suggests that how something is conveyed matters profoundly, ReSIn-HR prioritizes the timing and emotional resonance of gestures, moving beyond purely functional movement to create genuinely engaging interaction. The system’s ability to dynamically adapt and synchronize gestures in real-time reveals the power of reverse-engineering the subtleties of human communication.
Beyond the Mirror: Charting the Unseen Currents
The ReSIn-HR framework, while a notable step towards synchronized human-robot interaction, inevitably highlights what remains stubbornly unmodeled. Real-time adaptation, predicated on speech emotion recognition, assumes emotions are neatly packaged, readily identifiable signals. Yet, experience demonstrates emotional leakage-the subtle incongruities between expressed affect and underlying state-often provide more information than the overt display. Future iterations must grapple with this inherent ambiguity, perhaps by incorporating models of cognitive dissonance or deceptive behavior. The current focus on generating response neglects the robot’s capacity to genuinely understand-a distinction that, while philosophically fraught, is practically critical.
Furthermore, the emphasis on biomechanical constraints, while preventing robotic awkwardness, risks creating predictable, almost robotic, responses. Human interaction thrives on micro-violations of expectation-the slight stumble, the fleeting asymmetry. Perfect synchronization, ironically, feels less natural. The true challenge lies not in eliminating error, but in skillfully incorporating controlled instability-a robotic analogue of human expressiveness. One suspects that the most compelling interactions will arise from systems deliberately designed to break their own rules.
Ultimately, the pursuit of emotion-aware robotics is less about creating artificial empathy and more about reverse-engineering the complex, often irrational, processes that govern human connection. Each successful (or failed) interaction provides data-not about how to simulate emotion, but about how emotion itself functions as a system. The framework’s true value, therefore, may not lie in its output, but in the questions it forces us to ask.
Original article: https://arxiv.org/pdf/2601.17287.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
2026-01-27 12:33