Author: Denis Avetisyan
Researchers have developed an AI system capable of understanding and executing complex photo editing instructions, achieving professional-level results with remarkable consistency.
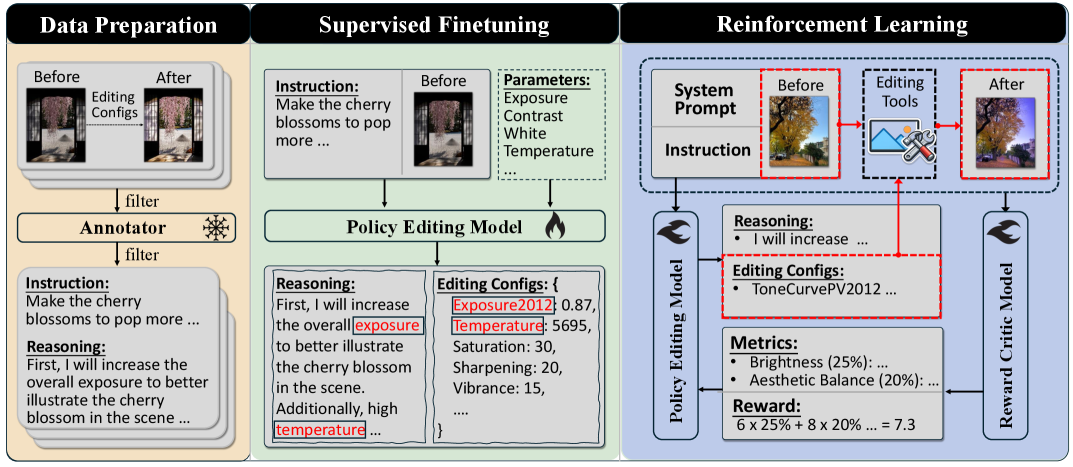
RetouchIQ leverages multimodal large language models and a novel reward training approach to perform instruction-based image retouching with state-of-the-art perceptual quality.
Achieving nuanced, instruction-based image editing remains challenging due to the subjective nature of aesthetic quality and the difficulty of defining reliable reward signals. This work introduces RetouchIQ: MLLM Agents for Instruction-Based Image Retouching with Generalist Reward, a framework employing multimodal large language model agents guided by a learned, generalist reward model to bridge high-level editing intentions with precise parameter control. Through policy-guided reward training and a curated dataset of 190k instruction-reasoning pairs, RetouchIQ demonstrably improves both semantic consistency and perceptual quality compared to existing MLLM and diffusion-based methods. Could this approach pave the way for more intuitive and powerful AI-driven creative tools for professional image editing?
The Erosion of Manual Precision: A Paradigm Shift in Visual Refinement
For decades, achieving polished visual results from digital images necessitated a substantial investment in both time and specialized knowledge. Traditional image editing workflows often involved painstakingly adjusting countless parameters – from color balance and exposure to intricate masking and selective enhancements – demanding considerable expertise and manual effort. This reliance on skilled practitioners created a significant barrier to entry for casual users and severely limited the scalability of image modification processes. Consequently, efficiently handling large volumes of images – a common need in fields like e-commerce, social media, and scientific data analysis – proved challenging and resource-intensive, highlighting the limitations of a predominantly manual approach to visual refinement.
The increasing desire for streamlined image manipulation has catalyzed a move towards instruction-based editing techniques. Rather than relying on precise pixel-level adjustments, these emerging systems interpret user requests expressed in everyday language – commands like “increase saturation” or “remove the background” – and automatically enact the corresponding changes. This approach bypasses the steep learning curves and time-intensive processes traditionally associated with professional image editing software, opening up creative possibilities to a wider audience. By bridging the gap between human intention and computational action, instruction-based methods promise a future where image editing is as simple as describing the desired outcome, fundamentally altering how visual content is created and refined.
The progression towards instruction-based image editing demands a sophisticated interplay between natural language processing and computer vision. Systems must move beyond simply recognizing keywords; they require a deep semantic understanding of user requests to accurately interpret the desired visual outcome. This necessitates the ability to decompose complex instructions – such as “make the sky more dramatic” or “replace the car with a vintage model” – into a series of precise image manipulations. Furthermore, these systems aren’t just performing simple filters; they are executing nuanced edits that involve object recognition, scene understanding, and realistic image synthesis, effectively bridging the gap between textual command and complex visual realization.

RetouchIQ: An MLLM-Based Agent for Precise Visual Control
RetouchIQ functions as an autonomous agent by integrating Multimodal Large Language Models (MLLMs) to bridge natural language instructions with executable image editing operations. These MLLMs process both textual prompts and visual data from images, allowing the agent to understand the desired modifications. This capability enables RetouchIQ to parse requests such as “reduce the saturation” or “remove the person in the background” and subsequently translate them into specific parameters and actions within an image editing environment. The core innovation lies in the MLLM’s ability to reason about visual content and connect semantic meaning to concrete image manipulations, thereby automating tasks traditionally requiring manual intervention by a skilled user.
RetouchIQ utilizes Adobe Lightroom as its primary tool for image manipulation, functioning as an intermediary between high-level instruction and low-level pixel adjustments. The agent parses user requests – expressed in natural language – and translates them into specific Lightroom parameters and operations, such as adjusting exposure, contrast, highlights, shadows, or applying localized edits via masking. This translation process enables semantic understanding – the meaning of an edit request – to be converted into precise, executable commands within Lightroom, allowing for automated and complex image modifications. The system doesn’t directly manipulate pixels; instead, it controls Lightroom’s established image processing algorithms to achieve the desired visual changes.
Supervised Fine-Tuning (SFT) forms the initial training phase for RetouchIQ, utilizing a dataset of paired image-instruction examples to establish a foundational understanding of image editing operations. This process involves presenting the MLLM with images and corresponding textual instructions detailing desired edits, and then training the model to predict the appropriate sequence of actions within the Adobe Lightroom execution environment. The SFT phase aims to create a baseline model capable of recognizing common editing requests and translating them into executable parameters, serving as a crucial precursor to more advanced training methodologies and enabling initial functional capability.

Refining Aesthetic Judgement: Policy-Guided Reward Training
Policy-Guided Reward Training (PGRT) is a Reinforcement Learning (RL) methodology used within RetouchIQ to improve the accuracy of reward estimation. Unlike traditional RL approaches that rely on externally defined reward functions, PGRT incorporates signals directly from the policy editing model itself. This feedback loop allows the system to refine its understanding of desirable image edits, effectively using the policy’s own behavior as a source of guidance for reward calculation. By leveraging the policy model’s internal logic, PGRT enables more precise reward signals, leading to improved performance in image editing tasks and higher accuracy when evaluating edits generated by the policy.
Image Perturbation is a key component in generating the training data for RetouchIQ’s Generalist Reward Model (GRM). This technique systematically introduces variations to input images, creating a diverse dataset of edited results. These perturbations encompass a range of modifications, including adjustments to color, contrast, and the application of various filters. The resulting data, consisting of both the original and perturbed images, is then used to train the GRM to accurately assess the quality and aesthetic appeal of different image edits, enhancing its ability to generalize across a variety of editing styles and content.
The Generalist Reward Model (GRM) within RetouchIQ’s Policy-Guided Reward Training (PGRT) framework functions by assessing the quality of image edits using a suite of generated metrics; these metrics collectively form the Reward Signal utilized to train the Reinforcement Learning (RL) agent. This signal directly influences the agent’s policy, driving iterative improvements in editing performance. Critically, RetouchIQ, through the implementation of PGRT, demonstrates superior performance, achieving the highest accuracy – as measured by the reward model – when evaluating data generated by its own policy compared to alternative methodologies. This indicates an effective feedback loop between policy generation and reward assessment, leading to refined editing capabilities.
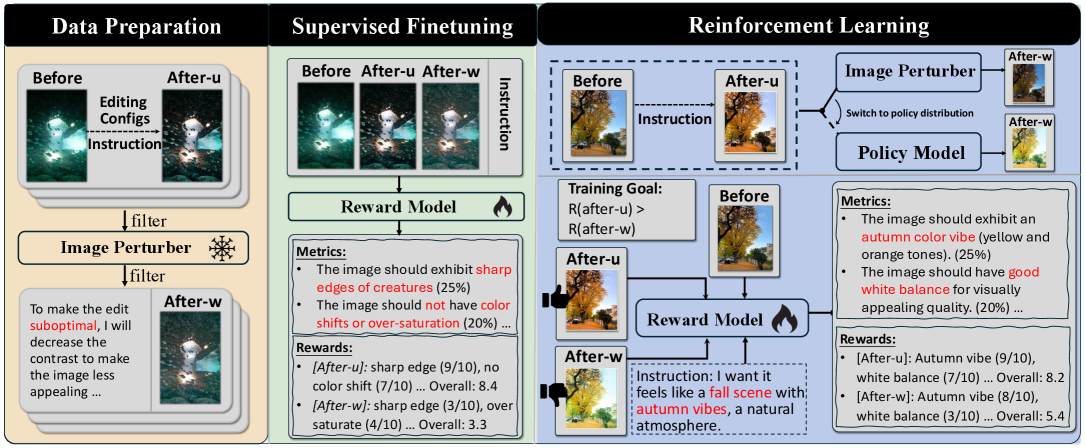
Beyond Approximation: A Paradigm Shift in Image Manipulation
RetouchIQ represents a departure from current image editing techniques, most notably those reliant on diffusion models. While diffusion excels at generating novel images, RetouchIQ focuses on precise, controlled manipulation of existing photographs. This system prioritizes semantic accuracy and stylistic refinement through the direct application of carefully defined Editing Parameters, allowing for adjustments that are both nuanced and predictable. Unlike diffusion’s probabilistic approach, RetouchIQ offers deterministic control, proving particularly advantageous when fidelity to the original image and adherence to specific aesthetic goals are paramount – a critical distinction for professional image retouchers and applications demanding repeatable, high-quality results.
RetouchIQ distinguishes itself through a carefully engineered system of Editing Parameters, enabling remarkably precise image adjustments that respond to subtle user direction. Unlike methods reliant on broad stylistic changes, this approach decomposes retouching into granular controls – governing aspects like skin smoothing, blemish removal, and localized color correction – each meticulously tuned for nuanced effect. The system doesn’t simply alter an image; it responds to specific instructions concerning how to alter it, allowing for highly targeted modifications. This granular control facilitates professional-level editing, moving beyond generic filters to address individual image characteristics and user preferences with exceptional fidelity. Consequently, RetouchIQ achieves a level of semantic alignment and stylistic control that surpasses many contemporary image manipulation techniques.
Rigorous evaluation of the system’s performance relies on objective Image Quality Metrics, moving beyond subjective assessments to provide quantifiable validation of its capabilities. Testing on the challenging RetouchEval benchmark demonstrates that this approach consistently achieves superior results compared to existing methods, while gains observed on the widely-used MIT-Adobe5K dataset further confirm its effectiveness. These improvements aren’t merely aesthetic; the data suggests enhanced semantic alignment – meaning the edits accurately reflect the intended changes – and a notable advancement in professional styling, producing results that closely mimic the work of skilled image editors.
The pursuit of semantic consistency, as demonstrated by RetouchIQ, echoes a fundamental principle of mathematical elegance. The system doesn’t merely approximate desired edits; it strives for a provably correct transformation of the image, guided by instruction and reinforced through a generalist reward model. This aligns with the notion that a robust solution isn’t defined by its performance on specific tests, but by its adherence to underlying invariants. As Fei-Fei Li aptly states, “AI is not about replacing humans, it’s about augmenting them.” RetouchIQ exemplifies this, empowering users with an agent capable of precise, instruction-based editing – a tool rooted in mathematical principles and aimed at enhancing, not supplanting, human creativity.
What’s Next?
The demonstration of RetouchIQ, while achieving demonstrable improvements in image manipulation, merely highlights the persistent chasm between algorithmic execution and genuine understanding. The reliance on a ‘generalist’ reward model, however cleverly trained, remains a pragmatic concession – a statistically derived approximation of aesthetic judgment. True elegance would lie in a system deriving its corrective actions from first principles – a formalization of visual harmony, not simply an imitation of human preference. The current methodology, while functionally effective, skirts the core issue: can an algorithm truly comprehend the semantic intent embedded within an instruction, or is it perpetually doomed to pattern matching?
Future work must address the brittleness inherent in these systems. A slight deviation in phrasing, an ambiguous instruction – these readily expose the limitations of purely data-driven approaches. The field requires a move beyond incremental gains in perceptual quality towards provable semantic consistency. The current emphasis on ‘policy-guided reward training’ feels, ultimately, like refining the map rather than understanding the territory.
In the chaos of data, only mathematical discipline endures. The pursuit of truly intelligent image editing necessitates a shift in focus: from mimicking outcomes to formalizing the underlying principles of visual cognition. Only then will these systems transcend the realm of clever tools and approach genuine understanding.
Original article: https://arxiv.org/pdf/2602.17558.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Limbus Company 2026 Roadmap Revealed
- EMEA Masters Winter 2026 introduces official Qualifier for Esports World Cup
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Total Football free codes and how to redeem them (March 2026)
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
2026-02-21 17:23