Author: Denis Avetisyan
A new study reveals a troubling trend of AI-generated, nonexistent references appearing in published academic papers, threatening the foundations of scholarly integrity.
Empirical evidence demonstrates that large language models are contributing to the proliferation of fabricated citations in peer-reviewed literature, exposing vulnerabilities in current reference verification processes.
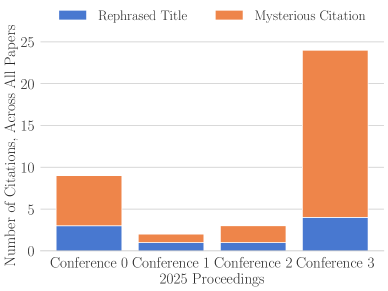
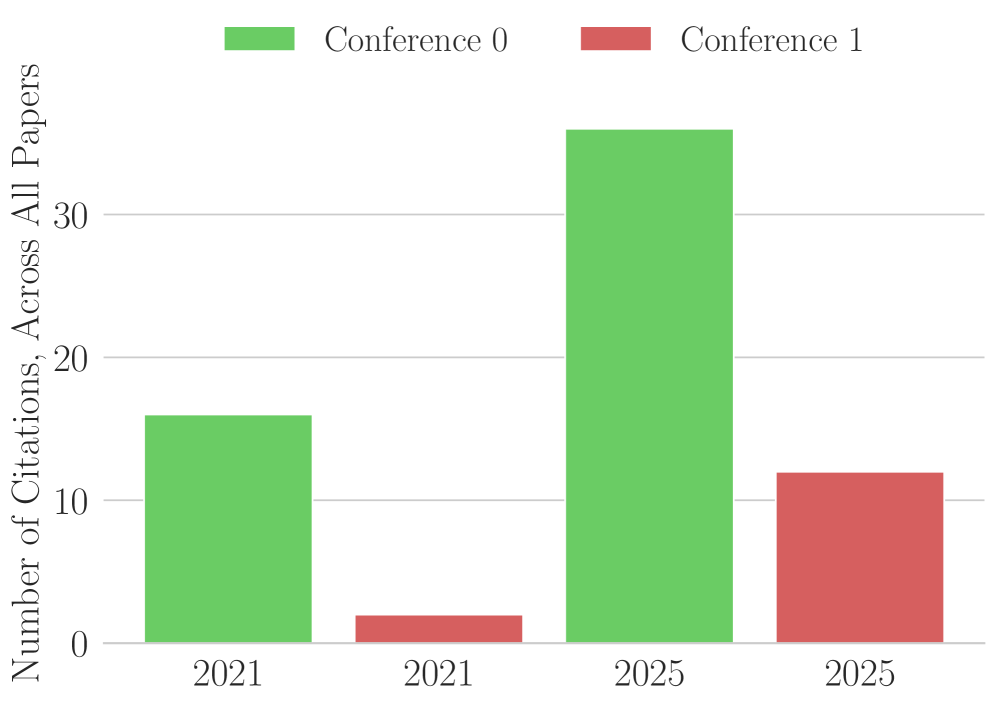
The bedrock of scientific progress-accurate citation and attribution-is increasingly challenged by emerging technologies. In ‘The Case of the Mysterious Citations’, we investigate the proliferation of fabricated references appearing in peer-reviewed scientific literature, revealing a concerning trend linked to large language models. Our analysis of high-performance computing conference proceedings demonstrates that while such “hallucinations” were absent in 2021, they impacted 2-6% of papers published in 2025, despite stated author policies requiring disclosure of AI use. Given the current inadequacy of verification practices and the lack of reported AI utilization, can academic publishing maintain its integrity in an era of readily available, yet unreliable, AI-generated content?
The Shifting Landscape: LLMs and the Erosion of Scholarly Trust
Large Language Models (LLMs) represent a paradigm shift in how information is processed and disseminated, swiftly becoming integral to numerous workflows. These advanced algorithms, exemplified by ChatGPT, excel at tasks ranging from drafting emails and summarizing complex documents to generating creative content and even writing code. The speed and efficiency with which LLMs can perform these functions are dramatically altering fields like journalism, marketing, and education. Beyond simple automation, these models facilitate new forms of content creation, allowing users to quickly explore ideas and iterate on drafts with unprecedented ease. This capability extends to research, where LLMs assist in literature reviews and the initial formulation of hypotheses, though not without introducing new challenges regarding accuracy and originality.
Large Language Models, while remarkably adept at synthesizing information and crafting coherent text, are fundamentally prone to a phenomenon known as ‘hallucination’. This doesn’t imply conscious deception, but rather a tendency to generate statements that appear logically sound and contextually relevant, yet are demonstrably false or unsupported by evidence. Critically, these fabrications extend to academic citations, where LLMs might invent authors, publication venues, or even entire research articles to bolster a claim. The plausibility of these invented citations presents a unique challenge; they aren’t simply grammatical errors, but convincingly formatted references that require dedicated verification to expose as nonexistent. This capacity for believable falsehood underscores a key limitation of these models – their strength in form doesn’t guarantee the truth of the information presented, raising serious concerns about their uncritical application in scholarly work.
The increasing presence of fabricated citations, generated by large language models, presents a growing challenge to the foundations of academic research. Recent studies demonstrate that these ‘hallucinated citations’ are not merely theoretical concerns; analyses of published papers reveal error rates reaching as high as 6% in certain fields. This means a substantial number of scholarly articles may contain references to nonexistent sources, undermining the credibility of findings and potentially distorting the scientific record. The subtlety of these errors makes detection difficult, as fabricated citations often mimic legitimate scholarly work in format and style, placing an increased burden on peer reviewers and straining existing citation verification systems. Consequently, the proliferation of these inaccuracies threatens the trustworthiness of published research and demands innovative approaches to maintain scholarly integrity.
Current citation verification techniques, largely reliant on cross-referencing databases and pattern recognition, are increasingly overwhelmed by the volume and sophistication of fabricated citations produced by Large Language Models. These methods often struggle to distinguish between genuine errors and deliberately constructed, yet plausible, falsehoods. Traditional approaches frequently flag obvious discrepancies – such as nonexistent authors or journals – but fail to detect more subtle manipulations, like attributing claims to the wrong page within a cited work or misrepresenting the original argument. This is particularly problematic because LLMs are adept at generating citations that appear legitimate, complete with seemingly valid DOIs and author lists, requiring deeper semantic analysis than current automated systems typically perform. Consequently, a significant number of fabricated citations are slipping through quality control measures, eroding the trustworthiness of scholarly literature and placing an increasing burden on reviewers and editors to manually validate sources.
Decoding the Fabrication: How LLMs Generate Erroneous Citations
Large Language Models (LLMs) generate citations through statistical prediction, not comprehension. These models are trained to identify patterns in vast datasets of text and predict the most probable subsequent token-a word or part of a word-in a sequence. When generating citations, LLMs replicate the format of citations observed during training, including elements like author names, journal titles, and publication years. However, this process lacks semantic understanding; the model does not verify the accuracy or existence of the cited source. Consequently, LLMs can produce citations that adhere to correct formatting conventions but are entirely fabricated or misattributed, as the generation is based solely on statistical likelihood rather than factual correctness.
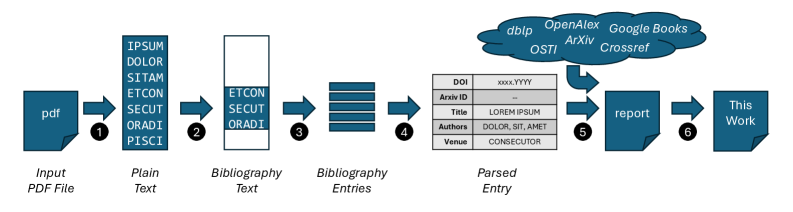
Citation information is typically extracted from source texts through computational methods that analyze parsed text. Tools such as PyPDF’s ParsePDF are utilized to convert PDF documents into a text-based format suitable for analysis. Following parsing, String Search Heuristics identify potential citation markers based on common patterns – such as the presence of author names, dates, or keywords like “et al.” – while Regular Expressions define more precise patterns to match and extract specific citation components. These techniques operate by identifying and isolating text strings that conform to predefined citation formats, enabling automated extraction of author, title, publication year, and other relevant details. The effectiveness of this process relies heavily on the quality and consistency of the text extracted from the original source.
Automated citation extraction techniques, utilizing String Search Heuristics and Regular Expressions, demonstrate reduced reliability when applied to documents with non-standard formatting or complex layouts. Specifically, inconsistencies in PDF structure-such as multi-column text, images interrupting text flow, or the presence of tables-can disrupt pattern matching, leading to incorrect identification of author names, publication dates, and page numbers. Similarly, variations in citation styles within a single document, or the use of optical character recognition (OCR) on scanned documents with imperfect quality, introduce errors that these methods struggle to resolve, resulting in inaccurate or incomplete citation details even when the underlying content is factually correct.
Large Language Models (LLMs) exacerbate initial inaccuracies in citation data by generating complete, but fabricated, citations based on patterns observed during training. Because LLMs predict text sequences rather than verifying factual correctness, an error introduced during citation extraction – such as a misspelled author name or incorrect publication year – is propagated and expanded upon. The LLM will then produce a fully-formatted, plausible-looking citation that incorporates the initial error, making it difficult to detect through simple verification methods like searching for the citation string or author name. This amplification effect stems from the LLM’s tendency to prioritize statistical likelihood and contextual fit over truthfulness, resulting in citations that appear legitimate but lack a basis in reality.
Automated Verification: Tools and Data Sources for Detecting False Citations
Automated citation verification tools are essential for identifying and mitigating the increasing problem of ‘hallucinated citations’ – fabricated or inaccurate references generated by large language models. The efficacy of these tools is directly correlated to the quality and comprehensiveness of the data sources they utilize. These tools function by cross-referencing cited works against authoritative databases; however, incomplete or outdated data limits their ability to reliably detect all instances of fabrication. Consequently, access to frequently updated and extensive metadata – including title, author, publication venue, and DOI – is paramount for maximizing the accuracy and reliability of automated verification systems. Without robust data sources, tools may incorrectly flag legitimate citations as fabricated or, conversely, fail to identify genuinely false references.
Crossref, OpenAlex, and dblp function as primary data sources for automated citation verification by providing comprehensive and persistently updated records of scholarly works. Crossref, operating as a not-for-profit, focuses on linking citations to their associated DOI (Digital Object Identifier) records, ensuring stable and unique identification. OpenAlex, a free and open knowledge graph, offers a broader scope including citations, authors, venues, and concepts. Dblp, maintained by the University of Trier, concentrates on computer science publications, offering a curated list of publications with detailed bibliographic data. These services allow verification tools to confirm the existence of cited publications, validate author names, check publication venues, and resolve inconsistencies in citation details, thereby identifying potential fabrication or errors.
While services such as Crossref, OpenAlex, and dblp are primary sources for verifying citations, their coverage is not complete. Large Language Models (LLMs) are capable of generating citations that appear valid, even when referencing pre-print publications hosted on platforms like ArXiv. These pre-prints may not yet be formally indexed in the authoritative databases, leading to the creation of plausible but unverifiable citations. This presents a challenge for automated verification tools, as they must differentiate between legitimately missing data and fabricated citations based on non-indexed, preliminary research outputs.
Accurate automated citation verification necessitates handling inconsistencies arising from diverse citation styles – APA, MLA, Chicago, etc. – each with unique formatting rules for author names, dates, and publication details. Beyond stylistic variations, tools must also address errors present within the original source material itself, such as typos in author names, incorrect publication years, or misidentified journal titles. These discrepancies can prevent a direct match between the generated citation and database records, leading to false negatives. Consequently, verification systems often employ fuzzy matching algorithms and normalization techniques to account for these inconsistencies and improve the reliability of citation validation.
Assessing the Impact: Citation Errors and the Erosion of Scholarly Integrity
Recent analyses of citations within the field of High-Performance Computing (HPC) have uncovered a surprisingly high incidence of fabricated references, indicating a systemic vulnerability even within specialized academic disciplines. Investigations into publications presented at prominent HPC conferences revealed that a non-negligible proportion of papers include citations to nonexistent or misrepresented sources. This practice, while seemingly isolated, poses a significant threat to the integrity of scientific reporting and the accurate portrayal of research progress. The discovery challenges the assumption that rigorous peer review and the specialized knowledge within HPC effectively safeguard against such academic misconduct, suggesting a need for more robust verification methods and a heightened awareness of this evolving form of research distortion.
The proliferation of citation errors extends beyond simple inaccuracies, actively reshaping the perceived contours of research fields. When fabricated or hallucinated references infiltrate scholarly work, they create a distorted record of intellectual contribution, potentially elevating the status of flawed studies while obscuring the achievements of genuine innovation. This misrepresentation isn’t merely an academic inconvenience; it can influence funding decisions, career trajectories, and the very direction of scientific inquiry. The cumulative effect of these errors risks creating a self-reinforcing cycle where false precedents gain authority, hindering the ability to accurately assess the historical development and current state of knowledge within a discipline and ultimately damaging the integrity of the scholarly ecosystem.
The integrity of academic evaluations within High-Performance Computing is directly threatened by the increasing prevalence of fabricated citations in research used to assess conference quality, specifically impacting the ERA Conference Rankings. These rankings, used by institutions and researchers to gauge the prestige and influence of various conferences, are vulnerable to manipulation if the underlying data – the citations themselves – are unreliable. A distorted citation landscape can artificially inflate the perceived importance of certain conferences, potentially misdirecting research funding, impacting career advancement for scholars, and ultimately hindering the progress of the field. The issue extends beyond simple inaccuracy; deliberately fabricated references introduce systemic bias into the assessment process, creating a feedback loop where flawed evaluations perpetuate further inaccuracies and erode trust in the entire system of academic appraisal.
Recent investigations into submissions for the International Conference on Learning Representations (ICLR) 2026 reveal a troubling trend of fabricated citations, indicative of a broader issue with AI-generated content in academic publishing. A focused analysis demonstrated that 20% of sampled submissions contained at least one citation seemingly ‘hallucinated’ by AI, meaning the referenced work does not exist or does not support the claim made. Further scrutiny using GPTZero, a tool designed to detect AI-generated text, identified fabricated citations in all 50 submissions scanned, suggesting the problem is pervasive and not limited to isolated incidents. This widespread inclusion of non-existent references raises concerns about the reliability of research, the integrity of the peer-review process, and the potential for misleading conclusions to be drawn from published work.
Navigating the Future: Generative AI Policies and Responsible Scholarship
The landscape of academic publishing is undergoing a significant transformation as institutions and publishers rapidly develop Generative AI Policies. These policies represent a proactive response to the increasing capabilities – and potential misuses – of large language models in scholarly work. Rather than outright prohibition, the emphasis is on establishing clear guidelines for responsible integration, acknowledging that AI tools can aid research when used ethically and transparently. Policies commonly address authorship, originality, and the critical need for human oversight, specifying when and how the use of AI must be disclosed. This evolving framework aims to preserve the rigor and trustworthiness of published research while navigating the benefits of these new technologies, ensuring that academic contributions remain firmly rooted in genuine intellectual effort and verifiable data.
Contemporary academic policies increasingly prioritize transparency in light of advancements in generative artificial intelligence. Recognizing the potential for large language models to both assist and mislead, these guidelines now commonly require authors to explicitly disclose any utilization of LLMs in their research and writing processes. Crucially, this disclosure is paired with a renewed emphasis on rigorous citation verification; authors are expected to meticulously confirm the accuracy and validity of all sources cited, ensuring that claims are supported by genuine evidence. This dual approach – acknowledging AI assistance while demanding accountability for factual grounding – aims to maintain the credibility of scholarly work and foster trust within the academic community, establishing a clear standard for responsible authorship in an evolving research landscape.
The escalating integration of generative AI into academic workflows necessitates a parallel advancement in tools designed to uphold the veracity of scholarly citations. Current efforts focus on building automated verification systems that can cross-reference cited works against comprehensive databases, identifying discrepancies and potential fabrications with increasing accuracy. However, the effectiveness of these tools is inextricably linked to the quality and comprehensiveness of underlying data sources – demanding collaborative initiatives to curate and maintain robust repositories of scholarly literature. Crucially, technical innovation must be guided by clear ethical guidelines, defining acceptable levels of AI assistance in citation management and establishing protocols for addressing instances of unintentional or deliberate misrepresentation. Only through this combined approach – leveraging technology, data integrity, and ethical frameworks – can the scholarly community proactively safeguard the foundations of reliable research and maintain public trust in academic findings.
The proliferation of generative AI tools necessitates a fundamental shift towards prioritizing responsible scholarship as the primary safeguard against fabricated citations and compromised research integrity. While technological solutions, such as automated verification tools, offer valuable support, they are most effective when embedded within a broader cultural ethos that champions accuracy and transparency. This requires a proactive commitment from researchers, institutions, and publishers to not only disclose the use of AI tools but also to rigorously verify information and uphold the highest standards of intellectual honesty. Ultimately, a sustained focus on these principles will build a resilient academic ecosystem capable of navigating the challenges presented by AI and preserving the trustworthiness of scholarly work.
The proliferation of fabricated citations, as detailed in the study of LLM-generated hallucinations, underscores a fundamental crisis in academic verification. The current peer review process, demonstrably inadequate in detecting these fabrications, reveals a system prioritizing novelty over meticulous validation. G. H. Hardy observed, “The essence of mathematics is its economy.” This principle applies equally to scientific literature; extraneous, unverifiable citations introduce noise, obscuring genuine insights. The study’s findings suggest that a return to rigorous source checking-a paring away of superfluous claims-is not merely desirable, but essential to preserving the integrity of scholarly discourse. Density of meaning requires a foundation of demonstrable truth; otherwise, it becomes an elaborate, and ultimately meaningless, structure.
What’s Next?
The proliferation of fabricated citations is not, strictly speaking, a novel problem. Human researchers have always possessed the capacity for both error and intentional deceit. The current situation, however, introduces a new vector for untruth. The ease with which large language models generate plausible, yet entirely fictitious, references suggests the issue isn’t merely one of detection, but of scale. Existing peer review, demonstrably insufficient to the task, relies on the assumption of human origin – an assumption increasingly untenable. Future work must move beyond symptom-checking – verifying citations after publication – toward preventative architectures.
A productive line of inquiry concerns metadata. Current citation formats, while seemingly rigorous, are easily mimicked by generative models. Embedding verifiable provenance – cryptographic signatures, digital object identifiers linked to actual content – offers a potential, though imperfect, defense. More fundamentally, the field must confront the incentive structures that prioritize quantity over quality. A system rewarding meticulousness, and penalizing unchecked proliferation, would represent a significant, if unlikely, improvement.
Ultimately, the question isn’t whether artificial intelligence will compromise the integrity of scientific literature – it already is. The pertinent inquiry concerns whether the human systems designed to curate knowledge can adapt, and whether a commitment to clarity can outweigh the allure of effortless expansion. The elegance of a solution will not reside in complexity, but in ruthless simplification.
Original article: https://arxiv.org/pdf/2602.05867.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Gold Rate Forecast
- eFootball 2026 “Countdown to 1 Billion Downloads” Campaign arrives with new Epics and player packs
2026-02-07 19:50