Author: Denis Avetisyan
A new framework translates human instructions directly into efficient robot control policies, enabling versatile performance across a range of tasks.
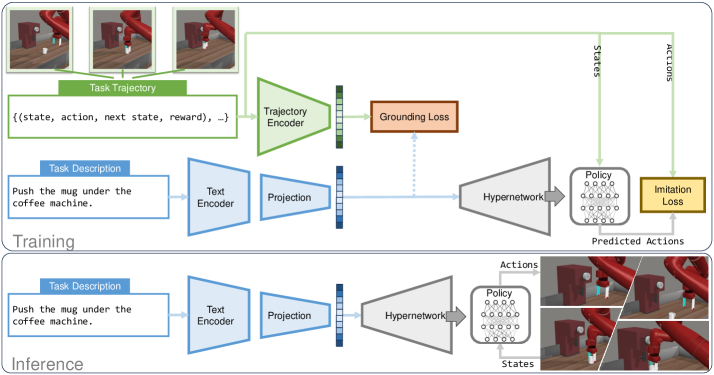
TeNet generates compact policies from text descriptions, achieving high control frequencies and strong multi-task learning capabilities.
Current approaches to robot control via natural language often rely on either inflexible, hand-designed interfaces or computationally expensive, end-to-end models. To address this, we introduce ‘TeNet: Text-to-Network for Compact Policy Synthesis’, a framework that generates lightweight, task-specific robot policies directly from language descriptions by conditioning a hypernetwork on text embeddings. This allows for strong performance in multi-task settings and high-frequency control, while maintaining the general knowledge and robustness of pretrained language models. Could this text-to-network approach unlock more adaptable and resource-efficient robotic systems for real-world applications?
Beyond Direct Control: The Illusion of Robotic Mastery
Conventional robotic systems are fundamentally built upon the principle of precise, pre-programmed control – a methodology that, while effective in structured environments, reveals limitations when confronted with the unpredictable nature of real-world tasks. These robots excel at repeating defined motions, but struggle with adaptability, requiring extensive re-programming even for slight variations in their surroundings or goals. This reliance on explicit control hinders their ability to navigate dynamic scenarios, manipulate novel objects, or respond intelligently to unforeseen circumstances. Consequently, robots designed under this paradigm often prove inflexible and inefficient when applied to complex, open-ended problems that demand a degree of autonomy and intuitive reasoning – a challenge driving the development of more sophisticated control architectures.
Robotics is undergoing a shift towards more intuitive human-machine interaction through language-conditioned control. This approach moves beyond traditional programming, allowing operators to direct robotic actions using natural language – commands like “pick up the red block” or “navigate to the kitchen” become actionable instructions. The system translates these semantic requests into specific motor commands, enabling robots to perform tasks described in everyday language, rather than requiring precise, coded instructions. This capability not only simplifies the user interface but also opens possibilities for broader applications, including collaborative work environments where robots can respond dynamically to changing instructions and complex, nuanced requests, mirroring human adaptability and communication styles.
A core difficulty in language-conditioned robotics lies in the substantial semantic gap separating human language from robotic action. Robots don’t inherently ‘understand’ requests like “bring me the red block”; instead, they require translation of these abstract commands into precise motor controls and environmental perceptions. Current approaches struggle with ambiguity; the same phrase can necessitate vastly different actions depending on context, requiring robots to infer intent – a cognitive feat that remains elusive. Furthermore, language is inherently compositional, meaning meaning arises from the arrangement of words, but robots often treat language as a series of isolated commands. Effectively bridging this gap demands advancements in natural language understanding, reasoning, and the capacity to map linguistic concepts onto complex, real-world actions, representing a key hurdle in achieving truly intuitive human-robot interaction.
A persistent limitation of contemporary language-conditioned robotics lies in its struggle to extrapolate learned behaviors to novel situations. While a robot might successfully execute a command like “pick up the red block” within a carefully designed environment, performance frequently degrades when presented with a slightly altered scenario – a different colored block, a cluttered workspace, or an entirely new room. This lack of generalization stems from the reliance on narrowly trained models that excel at specific tasks but fail to grasp the underlying principles governing them. Consequently, robots often require extensive retraining for each new environment or task variation, hindering their potential for truly autonomous operation and widespread applicability. Researchers are actively exploring techniques – including meta-learning and transfer learning – to imbue these systems with the capacity to adapt and perform reliably even when faced with the unexpected, moving closer to robots that can genuinely understand and respond to instructions in a dynamic, real-world context.
Unlocking Intelligence: Language Models and Offline Reinforcement
Large Language Models (LLMs), including architectures like LLaMA and BERT, demonstrate proficiency in natural language understanding due to their transformer-based design and training on extensive text corpora. These models utilize attention mechanisms to weigh the importance of different words in a sequence, enabling them to capture contextual relationships and semantic nuances. Specifically, LLMs represent words and phrases as high-dimensional vectors – known as embeddings – where similar meanings are located closer together in the vector space. This allows the models to perform tasks such as sentiment analysis, question answering, and text summarization by comparing the semantic similarity of input texts. The scale of these models, often containing billions of parameters, contributes to their ability to generalize from observed data and accurately interpret the meaning conveyed in natural language.
Offline Reinforcement Learning (RL) addresses limitations of traditional RL by enabling policy training solely from a fixed dataset of previously collected experiences, eliminating the need for costly and potentially dangerous online interaction with the environment. This approach is particularly beneficial in robotics where data acquisition can be time-consuming, expensive, or physically risky. The data, typically consisting of state-action-reward tuples, is used to train a policy that maximizes cumulative reward without further environmental feedback. Consequently, offline RL offers a data-efficient alternative, allowing robots to learn complex behaviors from pre-collected demonstrations or previously executed policies, and is applicable in scenarios where online exploration is impractical or undesirable.
Combining Large Language Models (LLMs) with Offline Reinforcement Learning (RL) enables the development of robotic policies with improved generalization capabilities. Traditional RL often struggles with tasks not explicitly seen during training. LLMs, pre-trained on extensive text corpora, provide a mechanism to understand and represent task variations expressed in natural language. When integrated with Offline RL, the LLM’s semantic understanding allows the agent to infer relationships between observed data and novel task instructions. This allows the agent to adapt previously learned policies to new, unseen scenarios without requiring further online interaction or data collection, effectively broadening the scope of tasks the robot can successfully perform.
Effective integration of Large Language Models (LLMs) into Offline Reinforcement Learning necessitates converting natural language task instructions into a structured representation suitable for a reinforcement learning agent. This encoding process typically involves techniques such as embedding the instruction text into a vector space, generating reward functions from the textual description, or formulating the instruction as constraints within the RL environment. The chosen encoding method must preserve the semantic meaning of the instruction while also providing a quantifiable signal that the agent can optimize during training. Furthermore, the encoded representation should be robust to variations in phrasing and ambiguity within the natural language input, ensuring consistent policy learning across diverse task descriptions.
TeNet: Weaving Language and Action into Compact Policies
TeNet utilizes a hypernetwork architecture conditioned on text embeddings generated by a Large Language Model (LLM). This conditioning process allows the hypernetwork to synthesize the weights of a policy network, effectively translating language instructions into specific behavioral parameters. Rather than directly outputting actions, the LLM processes instructions and creates a textual representation, which is then encoded into an embedding vector. This vector serves as input to the hypernetwork, guiding the generation of a compact policy network tailored to the given instruction. This approach decouples policy generation from the LLM itself, enabling efficient and scalable policy creation without requiring the LLM to be continually re-executed during deployment.
The TeNet framework achieves significant model compression by generating policies with only 40,000 parameters. This represents a substantial reduction in size compared to the Prompt-DT approach, which requires between 1 million and 39 million parameters to achieve comparable results. This parameter efficiency is enabled by conditioning a hypernetwork on text embeddings derived from a large language model, allowing for the creation of specialized policies directly from language instructions without the need for massive, fully parameterized networks. The resulting compact policies maintain performance while drastically reducing computational cost and memory requirements.
Trajectory Encoders are essential components within the TeNet framework, functioning to process expert demonstration data into a condensed, usable format. These encoders take raw trajectory data – representing sequences of actions taken by an expert agent – and transform it into a fixed-size embedding vector. This embedding encapsulates the key information within the demonstrated behavior, allowing for efficient comparison and alignment with language embeddings. The encoder’s architecture is critical; it must effectively capture the temporal dependencies and nuances present in the trajectory to generate a meaningful representation that accurately reflects the expert’s strategy. The quality of this embedding directly impacts the performance of subsequent alignment and policy generation stages.
Contrastive Alignment and Mean Squared Error (MSE) Alignment are employed within TeNet to optimize the correlation between language embeddings, generated from Large Language Models (LLMs), and trajectory embeddings derived from expert demonstrations. Contrastive Alignment utilizes a loss function that encourages similar embeddings for matching language-trajectory pairs and dissimilar embeddings for mismatched pairs, maximizing the distance between negative examples. MSE Alignment, conversely, minimizes the Euclidean distance between corresponding language and trajectory embeddings, enforcing a direct reduction in embedding difference. Both methods operate on the embedding space, refining the relationship between textual instruction and desired robot behavior, and demonstrably improve policy performance by creating a more consistent and accurate representation of the task.
Validating the System: Performance Across Simulated Worlds
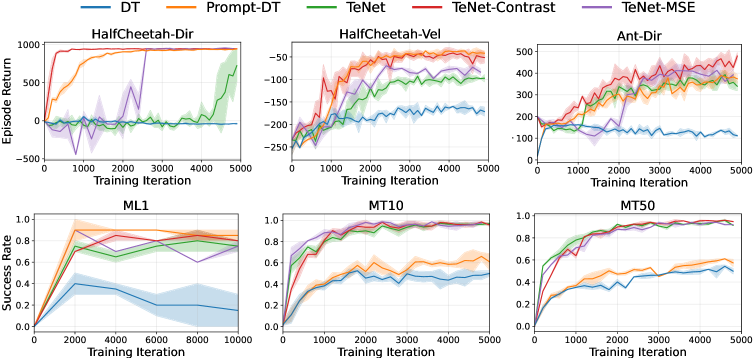
The TeNet framework has undergone rigorous testing across two prominent robotic simulation environments, Mujoco and Meta-World, successfully demonstrating its capacity to acquire and execute complex motor skills. These environments present distinct challenges – Mujoco emphasizes precise physics-based control, while Meta-World focuses on task generalization and few-shot learning – and TeNet’s consistent performance across both indicates a robust and adaptable learning architecture. Evaluations showcase the framework’s ability to master tasks requiring intricate coordination and sequential decision-making, paving the way for broader applications in robotic automation and artificial intelligence. The successful validation on these benchmarks highlights TeNet as a promising approach for developing versatile and intelligent robotic agents capable of operating in diverse and unpredictable scenarios.
The TeNet framework distinguishes itself through remarkable computational efficiency, consistently achieving control frequencies that surpass 9 kHz. This represents a substantial advancement over existing methods, notably exceeding the performance of Prompt-DT by more than ten-fold – an order of magnitude improvement. Such high-frequency control is critical for real-time robotic applications demanding precise and rapid responses to dynamic environments. The speed attained by TeNet not only enables more fluid and natural movements but also unlocks the potential for tackling increasingly complex tasks requiring intricate coordination and timing, pushing the boundaries of robotic dexterity and responsiveness.
TeNet’s learning process benefits substantially from an initial phase of Behavior Cloning, a technique where the system learns from expert demonstrations before independent exploration. This pre-training effectively establishes a strong foundation of viable behaviors, allowing the robotic agent to rapidly acquire successful strategies within its environment. Rather than beginning with random actions, the agent starts with informed movements, significantly reducing the time needed to master complex tasks. Consequently, this initialization step not only improves the efficiency of learning but also contributes to a more stable and reliable performance, enabling the system to achieve proficient control with fewer training iterations and a higher degree of consistency.
Evaluations on the challenging Meta-World benchmarks, specifically the MT10 and MT50 suites, reveal a substantial performance advantage for TeNet over the Prompt-DT framework. This isn’t merely incremental improvement; TeNet consistently achieves a demonstrably higher success rate across a diverse array of robotic manipulation tasks. The framework’s ability to generalize and adapt to novel situations within these benchmarks highlights its robust learning capabilities and suggests a greater capacity for real-world application. This superior performance is particularly noteworthy given the complexity of the tasks and the limited training data available, positioning TeNet as a promising advancement in robotic control and imitation learning.
Beyond Simulation: Charting a Course Towards True Robotic Intelligence
Ongoing research prioritizes scaling the TeNet framework to address increasingly intricate tasks and dynamic environments. Current efforts involve developing more robust state abstraction techniques, enabling the system to effectively manage extended sequences of actions and perceive nuanced changes within complex surroundings. This expansion necessitates advancements in hierarchical reinforcement learning, allowing TeNet to decompose large problems into manageable sub-goals, and improvements in transfer learning, facilitating rapid adaptation to novel scenarios without extensive retraining. By focusing on these areas, the framework aims to move beyond controlled laboratory settings and demonstrate reliable performance in unpredictable, real-world applications, paving the way for robots capable of autonomously navigating and interacting with complex spaces.
The current TeNet framework excels at interpreting and executing tasks described through language, but its comprehension could be significantly broadened by incorporating visual data. By enabling the system to ‘see’ the environment and the objects within it, researchers anticipate a more nuanced understanding of task intent. This integration would move beyond simply processing textual commands – for example, distinguishing between “pick up the red block” and “pick up the blue block” even if the color isn’t explicitly stated in the instruction. Such multimodal input allows for grounding language in the physical world, resolving ambiguities, and enabling the robot to infer goals from observation – critical steps toward achieving robust and adaptable robotic intelligence capable of handling the complexities of real-world scenarios.
Continued advancements in large language model (LLM) architectures and training methodologies represent a crucial pathway towards significantly improved robotic control. Current research suggests that exploring alternatives to the standard transformer architecture – such as state space models or mixtures of experts – could address limitations in long-context handling and computational efficiency, enabling robots to reason about more extended sequences of actions and observations. Moreover, innovative training strategies, including reinforcement learning from human feedback and self-supervised learning techniques tailored for robotic data, promise to enhance the LLM’s ability to generalize to novel situations and refine its understanding of task objectives. These explorations aren’t simply about scaling up existing models; they’re about fundamentally rethinking how language models are designed and trained to effectively bridge the gap between linguistic instruction and physical action, ultimately fostering more adaptable and intelligent robotic systems.
The long-term vision of this work extends beyond specific task demonstrations, striving instead to foster the emergence of truly general-purpose robotic intelligence. This necessitates systems capable of adapting to unforeseen circumstances, reasoning about complex goals, and seamlessly integrating diverse sensory information – abilities currently limited in most robotic platforms. Researchers anticipate that a framework like TeNet, continually refined through exploration of advanced language models and multimodal inputs, will serve as a crucial stepping stone towards robots that can autonomously address a broad spectrum of real-world challenges, from assisting in disaster relief and healthcare to performing complex manufacturing tasks and exploring previously inaccessible environments. The ultimate goal is not simply automation of existing processes, but the creation of robotic systems capable of independent problem-solving and proactive engagement with the world.
The pursuit within TeNet, distilling complex robotic control directly from language, mirrors a fundamental tenet of systems understanding. Every exploit starts with a question, not with intent. Vinton Cerf articulated this principle succinctly: “The Internet treats everyone the same, and that’s both its greatest strength and its greatest weakness.” Similarly, TeNet’s strength lies in its generalized approach-a single network conditioned by language to handle diverse tasks. However, this very generality necessitates rigorous testing, a systematic ‘questioning’ of the system’s boundaries to ensure robust performance and uncover potential vulnerabilities in trajectory grounding, mirroring the internet’s open architecture and inherent risks. The framework’s capacity for compact policies is not merely an engineering feat, but a demonstration of how effectively a system can be reverse-engineered from its desired outcome.
What Breaks Down From Here?
The elegance of TeNet lies in its circumvention of explicit trajectory demonstration. Yet, one immediately asks: what happens when the language itself becomes ambiguous, or, more provocatively, lies? Current evaluations assume a correspondence between instruction and achievable action. But a system built on language-conditioned control must eventually grapple with deception, or at least, semantic drift. Can a policy be robustly generated from a deliberately misleading prompt? The framework’s reliance on pre-defined skills hints at an underlying brittleness; extending it to truly novel tasks-those not implicitly encoded in the training data-will demand more than just scaling the network.
Furthermore, the notion of “compactness” deserves scrutiny. While efficient policies are desirable, minimizing size invariably introduces a trade-off with expressiveness. The current work favors generalization across a limited task set. But what if the optimal policy for a given task is inherently complex, defying easy compression? Is the pursuit of compactness merely an artifact of computational limitations, or does it reflect a deeper principle about the structure of intelligent behavior?
Ultimately, TeNet’s success prompts a rather uncomfortable question: are robots simply learning to parse human intention, or are they internalizing our inherent limitations? The ability to synthesize policies from language is impressive, but it’s a shortcut. The true test will be whether this framework can bootstrap genuine understanding, or if it remains forever tethered to the imperfections of the human instructions it so readily obeys.
Original article: https://arxiv.org/pdf/2601.15912.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Invincible Creator on Why More Spin-offs Haven’t Happened Yet
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
2026-01-25 05:03