Author: Denis Avetisyan
A new framework streamlines research by converting initial ideas into complete scientific narratives, accelerating discovery and knowledge synthesis.

Idea2Story leverages pre-computed knowledge graphs and language-based agents to generate efficient and reliable research patterns from core concepts.
Despite recent advances in autonomous scientific discovery leveraging large language models, current systems often struggle with computational cost, context limitations, and unreliable reasoning due to their reliance on real-time literature analysis. This work introduces ‘Idea2Story: An Automated Pipeline for Transforming Research Concepts into Complete Scientific Narratives’, a pre-computation framework that constructs a structured knowledge graph of methodological units and reusable research patterns from peer-reviewed literature. By shifting from online reasoning to offline knowledge construction, Idea2Story enables more efficient and reliable generation of research narratives, alleviating the context window bottleneck of LLMs. Could this pre-computation approach represent a scalable foundation for truly autonomous and reproducible scientific workflows?
The Inevitable Bottleneck: LLMs and the Limits of Runtime Reasoning
Contemporary large language model (LLM)-based agents, exemplified by systems like SWE-Agent and OpenHands, frequently encounter limitations when tasked with intricate research endeavors. These agents, while proficient in certain areas, demonstrate a constrained capacity for robust reasoning and a difficulty in accurately identifying and managing dependencies within complex problems. This isn’t simply a matter of processing power; rather, these systems often struggle to move beyond pattern recognition to genuine understanding, hindering their ability to synthesize information effectively or adapt to unforeseen challenges during a research process. Consequently, tasks requiring nuanced judgment, iterative refinement, or the integration of disparate knowledge sources often prove beyond their current capabilities, highlighting a critical gap between their potential and the demands of authentic scientific inquiry.
A significant impediment to fully autonomous research lies in the prevalent reliance on runtime computation, exemplified by approaches such as Runtime-Centric Research. These methods necessitate performing calculations and analyses during the research process itself, rather than leveraging pre-computed knowledge or established datasets. This creates substantial bottlenecks, slowing down experimentation and hindering the efficient exploration of complex scientific questions. The constant need to re-compute results, especially when iterating through hypotheses or refining parameters, consumes valuable resources and limits the scope of inquiry. Consequently, these systems struggle to scale effectively and often fail to match the speed and efficiency of human researchers who can draw upon vast stores of prior knowledge and readily available computational resources.
Large language models, despite their impressive capabilities, are fundamentally constrained by a limited context window – the amount of text they can process at once. This poses a significant challenge for autonomous research, as scientific inquiry often relies on identifying and integrating information across extensive datasets and lengthy chains of reasoning. The inability to effectively leverage long-range dependencies – connections between pieces of information separated by considerable text – hinders an LLM’s capacity to build upon accumulated knowledge and synthesize truly novel insights. Consequently, models may struggle with tasks requiring holistic understanding, instead offering fragmented analyses or failing to recognize crucial relationships buried within larger bodies of work. Overcoming this bottleneck is therefore paramount to unlocking the full potential of LLMs in scientific discovery, demanding innovative approaches to knowledge representation and retrieval.
Pre-Computation: Building the Foundation for Autonomous Discovery
Idea2Story distinguishes between the processes of knowledge construction and research generation to improve efficiency and reduce computational demands. Traditional research workflows often interleave these two activities, requiring repeated analysis of source materials during iterative exploration. By pre-processing and structuring knowledge offline-prior to any specific research query-Idea2Story creates a readily accessible foundation. This decoupling allows for faster online research generation as the system can leverage the pre-built knowledge base instead of repeatedly parsing and interpreting raw data, ultimately lowering runtime costs and accelerating discovery.
Method Units, representing discrete and reusable experimental or analytical procedures, are extracted from scientific publications through automated text processing and natural language understanding techniques. These units are then formalized and integrated into a structured Knowledge Graph, a network where nodes represent Method Units and edges define relationships between them – such as prerequisite steps, alternative approaches, or data dependencies. This graph-based organization allows for the representation of complex methodological workflows and facilitates computational analysis of scientific methods, moving beyond simple keyword searches to enable reasoning about how research is conducted. The resulting Knowledge Graph serves as a centralized repository of methodological knowledge, readily accessible for downstream applications like automated experimental design or research synthesis.
The Knowledge Graph constructed within Idea2Story utilizes UMAP (Uniform Manifold Approximation and Projection) for dimensionality reduction and visualization of high-dimensional relationships between Method Units. UMAP is a non-linear dimensionality reduction technique that preserves both local and global structure in the data, allowing for efficient representation of complex connections. This enables faster navigation and identification of relevant Method Units within the graph, as UMAP projects the data into a lower-dimensional space while retaining meaningful proximities. The resulting UMAP embedding facilitates both visual exploration of the Knowledge Graph and computational analysis of relationships between different methodological components.
Pre-computing a knowledge foundation significantly lowers runtime operational costs by shifting intensive processing from query time to build time. This approach avoids repeated analysis of source literature for each research exploration, instead leveraging a pre-indexed and structured Knowledge Graph. Consequently, researchers can explore complex relationships and retrieve relevant Method Units with increased speed and reduced computational demand. The pre-computation allows for efficient navigation of the Knowledge Graph using techniques like Umap, facilitating faster hypothesis generation and validation compared to real-time data processing.
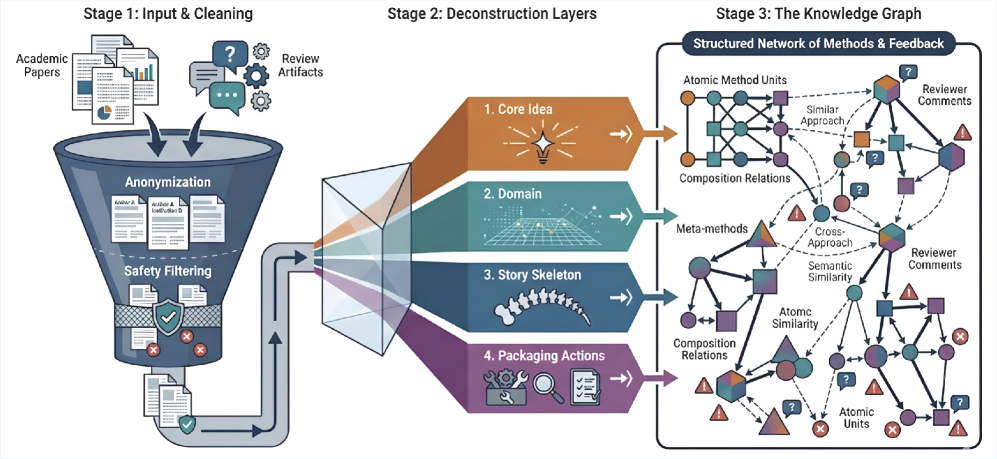
Dynamic Research: Assembling Patterns from a Pre-Computed Foundation
Idea2Story facilitates online research generation by accessing and combining pre-defined Research Patterns stored within a Knowledge Graph. This Knowledge Graph contains a structured compilation of methodological components, allowing the system to retrieve relevant patterns based on research needs. The composition process involves assembling these pre-built patterns into coherent research frameworks, effectively providing a starting point for investigation. This approach contrasts with traditional Large Language Model (LLM) workflows that perform reasoning and composition during runtime, and instead relies on a pre-computed library of research structures to accelerate and standardize the generation process.
Standard Large Language Model (LLM) workflows frequently encounter limitations due to repeated reasoning and context window constraints. Repeated reasoning occurs when the LLM revisits and re-evaluates the same information multiple times during a single task, increasing computational cost and latency. The context window bottleneck restricts the amount of information the LLM can process at once, hindering its ability to synthesize knowledge from extensive sources. Pre-computation, as utilized in Idea2Story, addresses these issues by proactively calculating and storing relevant information and methodological components before runtime. This reduces the need for real-time reasoning on previously analyzed data and minimizes the amount of information that must be included within the LLM’s context window during research pattern generation, leading to improved efficiency and scalability.
The system accelerates research and improves its dependability by pre-assembling relevant methodological components. This proactive approach involves identifying and integrating established research methods, statistical analyses, data collection techniques, and evaluation metrics before the research question is fully defined. By pre-computing these components and storing them within the Knowledge Graph, the system avoids redundant reasoning during runtime and reduces the computational burden on the Large Language Model. This pre-computation allows for faster hypothesis generation, experimental design, and data interpretation, ultimately leading to a more efficient and reliable research workflow. The pre-assembled components also ensure methodological consistency and reduce the risk of introducing bias or errors during the research process.
Evaluations conducted using Gemini 3 Pro consistently demonstrated a preference for research patterns generated by Idea2Story when compared to standard LLM outputs. These patterns exhibited statistically significant improvements in three key areas: novelty of proposed research, depth of methodological detail, and overall research quality as assessed by the model. This preference indicates a functional shift from traditional, runtime-dependent research generation-where all reasoning occurs during execution-to a pre-computation-driven approach, wherein complex research structures are assembled proactively, resulting in more robust and innovative autonomous research capabilities.
The research patterns generated by Idea2Story function as detailed experimental blueprints, specifying methodological components and their relationships to facilitate investigation. These patterns outline the necessary steps for testing a hypothesis, including suggested data collection methods, analytical techniques, and potential control variables. By pre-defining these elements, the system reduces the cognitive load on researchers and accelerates the transition from initial concept to actionable experimental design. This pre-computation approach enables rapid prototyping of research strategies and supports iterative refinement of experimental protocols, ultimately streamlining the research lifecycle and increasing efficiency.

Beyond Automation: A Paradigm Shift in Scientific Inquiry
The Idea2Story framework fundamentally alters how large language model (LLM)-based agents approach scientific inquiry. It establishes a meticulously organized knowledge base, moving beyond the limitations of unstructured data by pre-processing and categorizing information relevant to specific research areas. Crucially, this framework doesn’t simply store data; it incorporates an efficient research generation pipeline that allows agents to synthesize novel hypotheses and design experiments with greater speed and accuracy. By providing a pre-computed foundation of knowledge and a structured approach to problem-solving, Idea2Story empowers LLM agents to move beyond simple data retrieval and towards genuine scientific reasoning, significantly enhancing their capacity for independent discovery and innovation.
Existing scientific agents, such as Kosmos and Agent Review, demonstrate significant promise but often face limitations in knowledge access and research consistency. By integrating the pre-computed knowledge foundation offered by the Idea2Story framework, these systems can transcend these challenges. This foundational layer provides a readily available, structured base of scientific information, enabling agents to bypass time-consuming literature searches and focus on analysis and hypothesis generation. The result is a demonstrable improvement in both the speed and reliability of scientific inquiry; agents are less prone to errors stemming from incomplete or misinterpreted data and can more efficiently synthesize information to arrive at novel conclusions. This enhancement positions these agents as increasingly powerful tools for accelerating discovery across diverse scientific disciplines.
Early attempts at creating AI scientists, such as the AI Scientist system, were fundamentally limited by their dependence on manually crafted templates – pre-defined pathways for experimentation and analysis. While innovative for their time, these systems struggled with adaptability and scalability, requiring significant human effort to update and refine the templates for each new scientific domain. This new approach circumvents those limitations by dynamically generating research pipelines, effectively replacing rigid, pre-programmed structures with a flexible, knowledge-driven system. By automating the construction of experimental designs and analytical strategies, it unlocks the potential for AI to explore a far broader range of scientific questions with greater efficiency and independence than previously possible, moving beyond the constraints of human-defined boundaries.
The development of this methodology represents a significant leap towards automating scientific discovery, moving beyond isolated experiments to a system capable of continuous, self-directed research. By establishing a foundation for scalable knowledge integration and efficient hypothesis generation, it addresses a core limitation of earlier AI-driven science initiatives. This robust framework isn’t merely about accelerating existing research; it’s about enabling the creation of genuinely autonomous scientific agents capable of formulating novel questions, designing experiments, and interpreting results with minimal human intervention. The potential impact extends across diverse fields, promising a future where AI collaborators dramatically augment human scientists, accelerating the pace of innovation and unlocking solutions to complex challenges.
The pursuit of automating scientific narrative, as demonstrated by Idea2Story, feels less like construction and more like tending a garden. The framework’s pre-computation of knowledge into a graph isn’t about imposing order, but about recognizing the inherent patterns already present. It recalls Andrey Kolmogorov’s observation: “The most important discoveries often come from recognizing that something is possible, not from figuring out how to do it.” The system doesn’t build a story; it cultivates the conditions for one to emerge from the existing web of research. Each method unit extracted, each connection forged within the knowledge graph, is a gentle nudge, influencing the direction of growth. It acknowledges the inevitability of change and adaptation, understanding that even the most carefully planned systems will, in time, reveal unforeseen pathways.
What’s Next?
Idea2Story, as a structured attempt to coax narrative from the chaos of research, is less a solution than a beautifully articulated postponement of inevitable complexity. The pre-computation of knowledge, the forging of patterns – these are not acts of control, but rather the meticulous building of sandcastles before the tide. The system’s efficacy will not be judged by its current performance, but by the nature of its failures – what unforeseen edges of the scientific landscape will prove resistant to its structuring?
The true challenge lies not in automating the generation of stories, but in acknowledging that every story is a provisional map of a territory constantly reshaped by new data. There are no best practices – only survivors. Future work will inevitably focus on the fragility of the knowledge graph itself; on its susceptibility to bias, incompleteness, and the ever-shifting definitions within the scientific community.
The pipeline’s architecture is, ultimately, a prophecy. It anticipates a future where the volume of research exceeds any human capacity for synthesis, and where even automated systems must contend with the fundamental truth: order is just cache between two outages. The next iteration will not be about more automation, but about building in mechanisms for graceful degradation, for admitting uncertainty, and for learning from the inevitable collapse of meticulously crafted narratives.
Original article: https://arxiv.org/pdf/2601.20833.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- EMEA Masters Winter 2026 introduces official Qualifier for Esports World Cup
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Total Football free codes and how to redeem them (March 2026)
2026-01-29 11:44