Author: Denis Avetisyan
Researchers have developed a new method for efficiently reconstructing and rendering dynamic urban environments from sparse data, enabling real-time visualization and applications like autonomous driving.
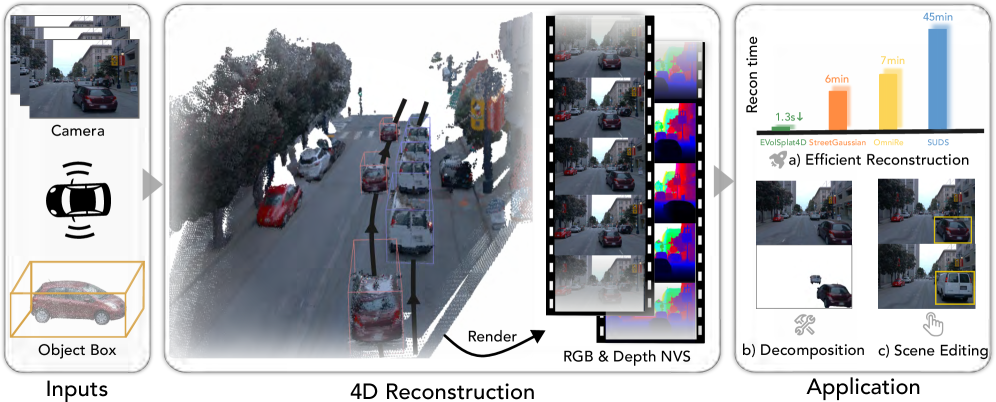
EVolSplat4D decomposes scenes into static and dynamic components using 3D Gaussian splatting for feed-forward reconstruction and high-fidelity rendering.
Balancing reconstruction fidelity and efficiency remains a core challenge in synthesizing dynamic urban scenes for applications like autonomous driving. To address this, we present EVolSplat4D: Efficient Volume-based Gaussian Splatting for 4D Urban Scene Synthesis, a novel feed-forward framework that decomposes scenes into static and dynamic components represented with 3D Gaussian splatting. By unifying volume-based and pixel-based predictions across specialized branches, EVolSplat4D achieves high-fidelity, consistent 4D reconstruction with real-time rendering capabilities. Can this approach pave the way for more robust and scalable solutions for simulating complex, real-world environments?
Unveiling Dynamic Worlds: The Challenge of Real-Time 3D Rendering
The creation of convincingly real and ever-changing three-dimensional scenes demands immense computational power, presenting a significant obstacle to the widespread adoption of technologies reliant on visual realism. Applications such as autonomous vehicles, which must process complex environments in real-time, and augmented/virtual reality experiences, requiring seamless and responsive interactions, are particularly affected by these limitations. The sheer number of calculations needed to simulate light interactions, object movements, and intricate details within a dynamic scene quickly overwhelms even the most powerful hardware. Consequently, achieving both high visual fidelity and the necessary speed for practical use remains a central challenge, driving ongoing research into more efficient rendering techniques and innovative hardware solutions.
Conventional techniques in 3D scene rendering face substantial hurdles when dealing with dynamism and intricacy. Capturing the continuous motion of objects, along with the nuances of complex environments, demands immense computational resources and memory. Existing systems frequently rely on meticulously detailed models, representing every surface and texture, which quickly become unwieldy as scene complexity increases. This reliance on dense representations creates a significant bottleneck, especially when dealing with real-time applications where responsiveness is crucial. The sheer volume of data needed to describe even moderately detailed moving scenes often exceeds the capabilities of current hardware, limiting the fidelity and smoothness of the rendered experience and hindering progress in fields like robotics and immersive technologies.
Conventional 3D scene rendering techniques frequently employ dense representations, where every point in a scene is meticulously modeled, leading to substantial computational demands. These methods, while capable of high visual fidelity, quickly encounter memory and processing bottlenecks as scene complexity increases. The sheer volume of data required to define even moderately detailed environments, coupled with the need to update this information with every movement or change, overwhelms available resources. This limitation is particularly acute in dynamic scenarios, such as those encountered in autonomous navigation or augmented reality, where real-time performance is critical. Consequently, the pursuit of more efficient, sparse representations has become a central focus in graphics research, aiming to achieve comparable visual quality with significantly reduced computational overhead.
Achieving both high visual fidelity and real-time performance in 3D scene rendering presents a significant hurdle for numerous applications. Current limitations necessitate a trade-off: detailed scenes often demand excessive computational resources, resulting in lag and hindering interactivity, while faster rendering frequently compromises visual quality, producing unrealistic or simplistic environments. This is particularly critical for time-sensitive fields like autonomous navigation, where split-second decisions depend on accurate environmental perception, and augmented/virtual reality, where seamless immersion requires consistently smooth and detailed visuals. Consequently, research is heavily focused on developing innovative rendering techniques that can break this performance barrier, offering a pathway towards truly realistic and interactive 3D experiences without sacrificing responsiveness or straining hardware limitations.
![This method reconstructs unbounded urban scenes by disentangling them into close-range volume, dynamic actors, and far-field scenery, each modeled with distinct feed-forward networks-[latex]\mathcal{F}^{\text{3D}}[/latex] for geometry and color in the close range, a motion-adjusted IBR module for dynamic actors, and a 2D U-Net backbone [latex]\mathcal{F}^{\text{2D}}[/latex] with cross-view attention for distant regions-and then composing the results.](https://arxiv.org/html/2601.15951v1/x2.png)
Embracing Sparsity: A New Paradigm in Neural Rendering
Real-world scenes are often characterized by significant empty space; most 3D volumes contain a relatively small number of surfaces or objects. This inherent sparsity presents an opportunity to reduce computational load in 3D processing pipelines. Traditional methods often process all points within a volume, regardless of whether they represent actual geometry. By identifying and focusing only on the occupied regions-those containing visible surfaces-algorithms can drastically reduce the number of computations required for tasks like rendering, reconstruction, and simulation. This selective processing is achieved through techniques such as sparse voxel octrees or sparse convolution, which efficiently represent and manipulate only the meaningful portions of a 3D scene, leading to substantial improvements in both speed and memory usage.
Neural Radiance Fields (NeRF) represent scenes as continuous volumetric functions, enabling view synthesis from arbitrary viewpoints. This is achieved by training a multi-layer perceptron (MLP) to map 3D coordinates and viewing directions to color and density values. While providing high-quality renderings, standard NeRF implementations require evaluating this MLP for numerous 3D points along each ray cast through the scene. This dense evaluation process, combined with the computational cost of the MLP itself, results in substantial training times and slow rendering speeds, particularly for complex or large-scale scenes. The computational complexity scales with the number of samples required to accurately integrate radiance along each ray, limiting the practicality of NeRF for real-time or interactive applications without optimization.
Combining Neural Radiance Fields (NeRF) with sparse convolution techniques addresses the computational limitations of processing large-scale 3D data, particularly point clouds generated by LiDAR systems. Traditional convolution operations applied to sparse 3D data are inefficient due to the processing of empty space. Sparse convolutions, however, only operate on occupied voxels, significantly reducing computational cost and memory footprint. By integrating sparse convolutions into the NeRF rendering pipeline, the system can efficiently process the sparse geometry inherent in LiDAR scans, enabling the creation of detailed and accurate 3D scene representations without the prohibitive computational demands of dense convolutional approaches. This allows for scaling NeRF to datasets with billions of points, facilitating applications requiring real-time or near-real-time rendering of large environments.
The integration of sparse convolution techniques with Neural Radiance Fields (NeRF) enables a trade-off between rendering fidelity and computational cost. Traditional NeRF implementations, while capable of high-quality results, require significant processing power and time for both training and rendering. By leveraging the sparsity inherent in 3D scenes, these hybrid approaches reduce the number of computations required, particularly for large-scale datasets like LiDAR point clouds. This optimization allows for rendering speeds sufficient for interactive or real-time applications, such as virtual and augmented reality, robotics, and autonomous navigation, without substantial degradation in visual quality. The resulting performance gains broaden the applicability of NeRF beyond offline rendering tasks.
![Motion-adjusted Implicit Neural Radiance Fields (IBR) transform LiDAR points using time-specific poses and a window-based projection to sample coherent features and visibility, which are then decoded by a dynamic Gaussian decoder [latex]\mathcal{D}_{\text{dyn}}[/latex] to regress 3D Gaussian attributes and render the dynamic object’s image and binary mask.](https://arxiv.org/html/2601.15951v1/x4.png)
EVolSplat4D: A Framework for Dynamic Scene Reconstruction
EVolSplat4D presents a new framework for dynamic urban scene reconstruction and rendering by integrating 3D Gaussian Splatting (3DGS) with neural rendering techniques. This approach leverages 3DGS to represent scenes as a collection of 3D Gaussians, offering a differentiable and efficient representation. Neural rendering is then employed to synthesize novel views of the scene, enabling high-quality rendering. The combination allows for the reconstruction of both static and dynamic elements within urban environments, offering a pathway to create realistic and detailed moving scene representations. The system moves beyond static scene reconstruction by explicitly addressing the challenges presented by temporal variations and moving objects within complex urban settings.
EVolSplat4D employs scene decomposition to separate a dynamic urban environment into static and dynamic components, which facilitates efficient rendering. This process identifies and isolates moving objects – such as vehicles and pedestrians – from the static background and infrastructure. By representing these components independently, the rendering pipeline can focus computational resources on the dynamic elements, avoiding redundant processing of the static scene. This targeted approach significantly reduces rendering time and improves overall performance, particularly in complex urban environments with numerous moving objects, as it allows for optimized rendering strategies for each component type.
Dynamic Gaussian Prediction within EVolSplat4D functions by representing moving objects as a collection of 3D Gaussians, each with associated time-varying parameters. These parameters, including position, rotation, and scale, are predicted using a recurrent neural network (RNN) that analyzes the historical trajectory of each Gaussian. This allows the framework to extrapolate the future motion of the Gaussian, enabling accurate tracking and rendering of dynamic elements within the scene. The prediction network is trained to minimize the temporal displacement error of the Gaussians, ensuring smooth and realistic motion over time. By decoupling object motion from background geometry, the system avoids motion blur and artifacts typically associated with traditional volume rendering techniques.
Evaluations of EVolSplat4D on the Waymo and PandaSet datasets demonstrate significant performance gains. Specifically, the system achieves a Peak Signal-to-Noise Ratio (PSNR) of 27.78 dB and a Structural Similarity Index (SSIM) of 0.86 when evaluated on the Waymo dataset. These metrics indicate a demonstrable improvement in reconstruction and rendering quality compared to existing state-of-the-art methods on the same benchmarks, suggesting enhanced fidelity and realism in dynamic scene representation.
EVolSplat4D is engineered for real-time rendering performance despite potential data loss. The framework maintains operational functionality even with an 80% reduction in input data points, demonstrating robustness under conditions of significant input sparsity. This resilience is achieved through the efficient representation of dynamic scenes using 3D Gaussian Splatting and neural rendering techniques, allowing for continued reconstruction and rendering quality despite incomplete or noisy input data. The system prioritizes maintaining a consistent frame rate and visual fidelity even when faced with substantial data loss, making it suitable for applications with limited or unreliable sensor input.

Beyond Pixels: Implications and Future Directions
The development of EVolSplat4D holds considerable promise for advancements in autonomous driving technology. By efficiently rendering and accurately modeling dynamic scenes, the framework facilitates the creation of highly realistic simulations crucial for training and validating self-driving algorithms. This capability extends beyond simple visual fidelity; the accurate motion modeling allows for the simulation of complex interactions between vehicles, pedestrians, and the environment, providing a more robust testing ground than real-world trials alone. Furthermore, the system’s perceptual capabilities, honed through realistic rendering, can directly enhance the perception systems within autonomous vehicles, improving their ability to interpret and react to dynamic surroundings in real-time, ultimately contributing to safer and more reliable self-driving systems.
The advent of EVolSplat4D facilitates a new level of control over dynamic scenes, moving beyond simple static adjustments to enable intuitive and efficient modification of environments in motion. Previously, altering a scene with moving elements required painstaking re-rendering or complex keyframe animation; this framework allows users to directly manipulate the underlying neural representation, effectively ‘editing’ the physics of the scene itself. This capability extends to nuanced changes – adjusting the speed of a pedestrian, altering the trajectory of a vehicle, or even introducing new dynamic elements – all with high fidelity and minimal computational cost. The result is a paradigm shift in content creation and simulation, promising significant advancements in areas like virtual reality, robotics, and the development of realistic training environments.
The ability of EVolSplat4D to accurately model dynamic scenes is fundamentally linked to its sophisticated semantic understanding, achieved through integration with methods like DINO. This isn’t simply about recognizing objects; the framework builds a contextual awareness of how objects relate to each other and the environment, allowing for more intelligent interaction. By leveraging DINO’s powerful visual feature extraction, EVolSplat4D can interpret scene elements not just as shapes, but as meaningful entities with associated behaviors. This enhanced interpretation facilitates advanced applications, such as enabling autonomous agents to predict pedestrian movements or allowing for intuitive scene editing where modifications to one object intelligently affect others, resulting in a more realistic and responsive virtual environment.
Continued development of EVolSplat4D prioritizes addressing limitations in handling increasingly intricate and expansive dynamic scenes. Researchers aim to refine the framework’s computational efficiency, allowing it to process and realistically render environments with a significantly higher density of interacting agents and objects. This includes exploring techniques for distributed processing and advanced data compression to overcome current scalability bottlenecks. Furthermore, investigations are underway to incorporate more sophisticated physical modeling – encompassing nuanced interactions like fluid dynamics and deformable object simulations – thereby enhancing the realism and fidelity of complex dynamic scenarios and broadening the scope of potential applications beyond current capabilities.
The pursuit of dynamic scene reconstruction, as demonstrated by EVolSplat4D, fundamentally relies on discerning patterns within observed data. The method’s decomposition of scenes into static and dynamic components echoes a core principle of understanding complex systems – breaking them down into manageable, interpretable parts. This aligns with Andrew Ng’s observation that, “Machine learning is about learning the mapping from inputs to outputs.” EVolSplat4D effectively learns this mapping by identifying and modeling the evolving elements of urban environments, transforming sparse inputs into high-fidelity, real-time representations. Model errors, inevitable in such reconstructions, become crucial indicators for refining the decomposition and improving the fidelity of the dynamic scene representation.
Beyond the Splat: Charting a Course for Dynamic Scene Understanding
The emergence of EVolSplat4D, and similar approaches, highlights a curious trend: the pursuit of increasingly photorealistic representations often outpaces a genuine understanding of the scenes they depict. While fidelity is undeniably important, the decomposition into static and dynamic components, though effective, feels inherently limited. Future work must move beyond simply representing motion to interpreting it. What constitutes ‘dynamic’ is, after all, subjective – a fluttering leaf and a speeding vehicle both change over time, but demand drastically different analytical approaches.
A critical unresolved challenge lies in the inherent ambiguity of sparse input data. EVolSplat4D, like many feed-forward methods, excels at interpolation, but remains vulnerable to misinterpretation when faced with occlusion or novel viewpoints. The field needs to prioritize techniques for robust uncertainty estimation, moving beyond confidence intervals to actively question the reconstructed scene. Is that shadow a true obstruction, or a reconstruction artifact?
Ultimately, the true test of these techniques will not be their ability to mimic reality, but to facilitate genuine interaction and reasoning. The promise of autonomous driving hinges not on creating a perfect visual simulation, but on building systems that can anticipate, adapt, and – dare one say – understand the chaotic dance of urban life. Reproducibility and explainability should be valued as much as, if not more than, raw rendering speed.
Original article: https://arxiv.org/pdf/2601.15951.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Invincible Creator on Why More Spin-offs Haven’t Happened Yet
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- Olivia Colman’s highest-rated drama hailed as “exceptional” is a must-see on TV tonight
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
2026-01-26 01:18