Author: Denis Avetisyan
A new framework categorizes the diverse roles humans and large language models play in collaborative decision-making.
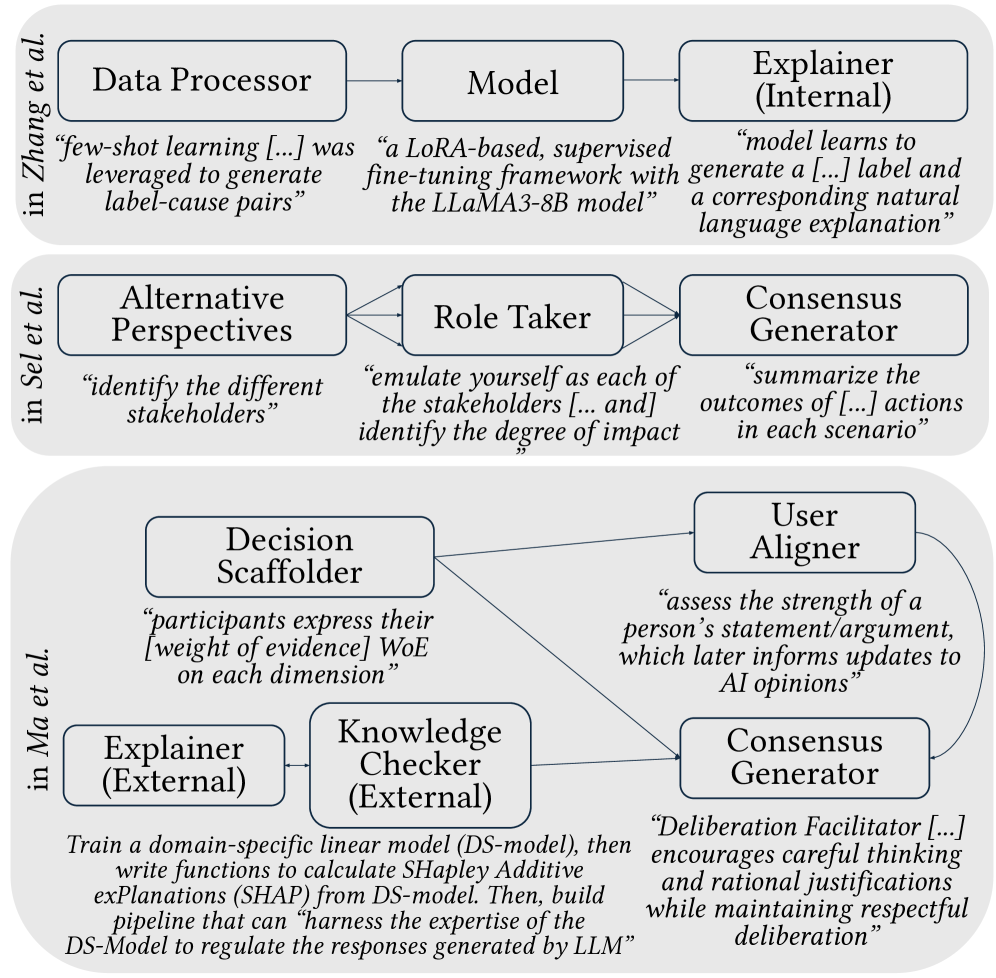
Researchers identify 17 archetypes of human-AI interaction to guide the design and evaluation of more effective and responsible AI-assisted systems.
As large language models (LLMs) become increasingly integrated into high-stakes decision-making processes, a critical gap emerges in understanding how humans and AI collaborate and the roles each assume. This paper, ‘Who Does What? Archetypes of Roles Assigned to LLMs During Human-AI Decision-Making’, addresses this by introducing a framework of 17 human-LLM archetypes – recurring patterns structuring collaborative decision-making roles. Through analysis of clinical diagnostics, we demonstrate that selecting a specific interaction archetype demonstrably influences LLM outputs and subsequent decisions. How can designers leverage this understanding to build more effective and responsible human-AI systems, mitigating risks associated with varying interaction paradigms?
Mapping the Landscape of Human-LLM Collaboration
The rapid integration of large language models into daily life-from customer service chatbots and writing assistants to coding companions and research tools-demands a move beyond simplistic views of human-computer interaction. This proliferation isn’t merely about using a tool, but entering into collaborative partnerships where roles are fluid and responsibilities are shared. Understanding these dynamics requires recognizing that humans and LLMs each contribute unique strengths-creativity, critical thinking, and contextual awareness from humans, and speed, scale, and pattern recognition from the models. Consequently, effective collaboration isn’t about replacing human tasks, but augmenting them, necessitating research into how individuals adapt, learn, and build trust with these increasingly capable artificial partners to maximize their combined potential.
Conventional frameworks for understanding human-computer interaction presume a largely static division of labor – a user issues commands, and a system responds. However, the advent of large language models (LLMs) is rapidly dismantling this paradigm, fostering partnerships where roles are fluid and renegotiated in real-time. Research indicates individuals aren’t simply directing LLMs, but rather collaborating with them, assuming roles like ‘exploratory partner’ in brainstorming, ‘critical evaluator’ of generated content, or even ‘teacher’ refining the model’s understanding through feedback. These dynamic interactions necessitate a move beyond task-oriented metrics, demanding investigations into the socio-cognitive processes – trust, shared understanding, and mutual adaptation – that govern these increasingly complex human-LLM collaborations. The limitations of older models aren’t merely a matter of precision; they fundamentally fail to capture the emergent, reciprocal nature of these novel partnerships.
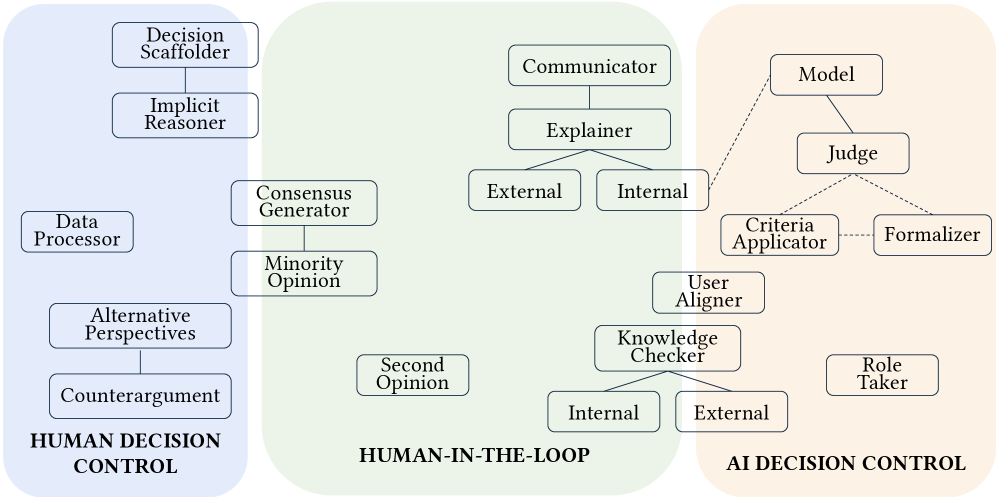
Defining Patterns: A Taxonomy of Collaborative Archetypes
The research introduces a framework of seventeen ‘Human-LLM Archetypes’ designed to categorize observed patterns in collaborative tasks involving both human participants and Large Language Models. These archetypes are not intended as rigid classifications, but rather as a means of identifying recurring socio-technical configurations. The framework systematically documents how decision-making authority is distributed between the human and the LLM, the extent to which each has access to external information sources, and the established social roles within the collaborative interaction. This categorization allows for analysis of team dynamics and prediction of performance based on the identified archetype, providing a structured approach to understanding human-LLM collaboration.
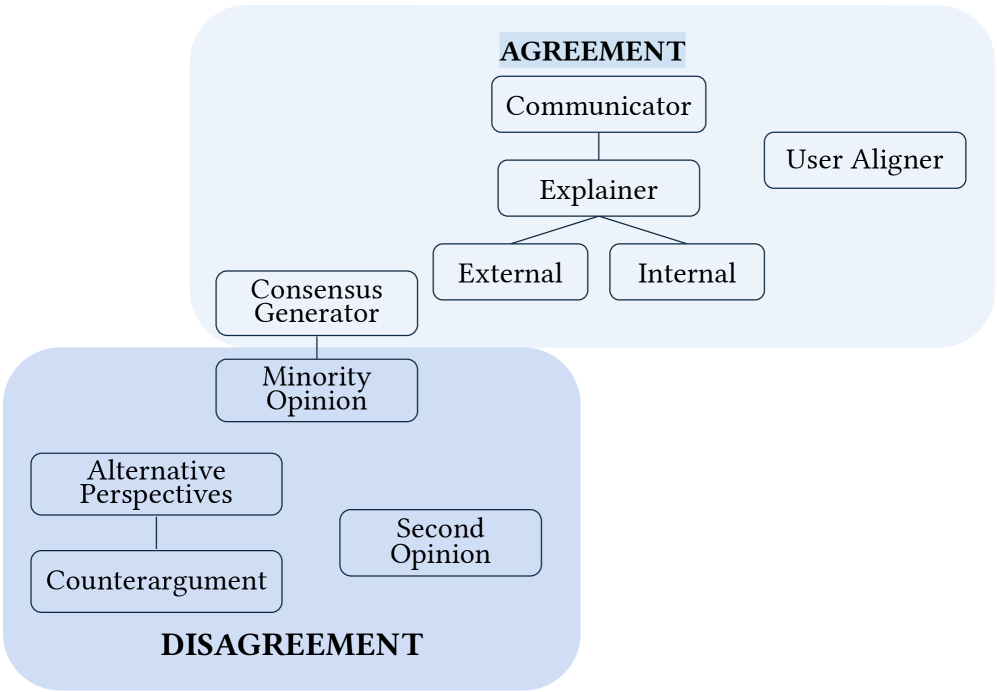
Human-LLM collaboration archetypes are differentiated by three primary characteristics: the allocation of decision-making authority between the human and the LLM, the extent to which each agent can access and utilize external information sources, and the established social role or positioning of the human participant within the collaborative process. Decision control ranges from fully human-led, where the LLM provides only suggestions, to LLM-dominant scenarios where the human primarily validates outputs. Access to external knowledge varies, with some archetypes relying solely on the LLM’s pre-trained data, while others actively integrate real-time information retrieval. Finally, social positioning encompasses the human’s perceived role – for example, as a supervisor, executor, or peer – which influences interaction patterns and the interpretation of outputs.
Predicting and optimizing human-LLM team effectiveness requires a granular understanding of how task characteristics interact with the socio-technical roles assumed by both human and artificial agents. By categorizing collaborative patterns into defined archetypes, we establish a basis for anticipating performance bottlenecks and identifying interventions to improve outcomes. Specifically, recognizing the distribution of decision control – whether humans or the LLM maintain primary control – coupled with access to external knowledge and social positioning, allows for targeted adjustments to workflow, information access, and team composition. This archetype-driven approach moves beyond generalized assessments of human-AI collaboration, enabling a more precise and actionable strategy for maximizing team performance and minimizing cognitive load on human participants.
Human-LLM collaboration archetypes are not static; they are dynamically influenced by group dynamics, specifically how team members interact and distribute workload. These interactions directly impact the cognitive load experienced by human participants, as factors like communication overhead, conflict resolution, and shared understanding require cognitive resources. Increased cognitive load-resulting from complex group dynamics-can diminish a human’s capacity to effectively utilize the LLM, potentially shifting the team’s operational archetype and reducing overall performance. Conversely, streamlined group dynamics and effective task allocation can reduce cognitive load, enabling humans to better leverage the LLM’s capabilities and maintain the intended archetype.
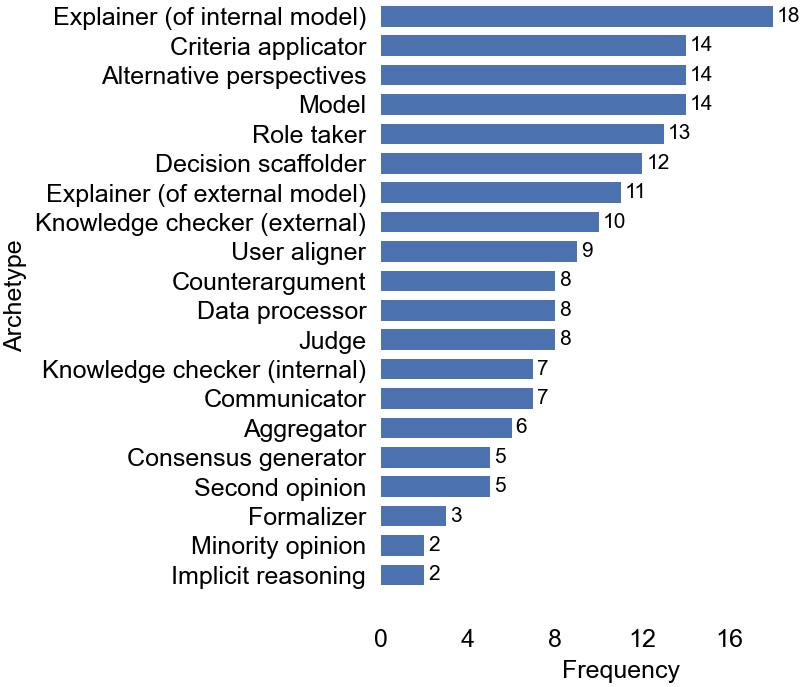
Evaluating Alignment: Gauging the Fidelity of Collaborative Outputs
In clinical diagnostics and other high-stakes applications, concordance between Large Language Model (LLM) outputs and expert human assessments is a fundamental requirement for responsible deployment. Discrepancies between LLM predictions and established clinical standards can directly impact patient care, leading to misdiagnosis or inappropriate treatment plans. Therefore, evaluating the degree of agreement-quantified through metrics such as percent agreement, Cohen’s Kappa, or other statistical measures of inter-rater reliability-is not merely an academic exercise but a critical step in validating the safety and efficacy of LLM-assisted diagnostic tools. This necessitates robust evaluation frameworks that explicitly measure and report the level of alignment between LLM outputs and validated human judgment, particularly in scenarios where errors could have significant consequences.
Evaluation of Large Language Models (LLMs) in collaborative contexts necessitates quantifying multiple performance characteristics. Key metrics include accuracy – the correctness of LLM outputs – and text quality, assessed through established linguistic criteria. Critically, the degree of agreement, or conversely, disagreement, between LLM-generated responses and human judgment serves as a vital indicator of alignment. Diagnostic case studies reveal statistically significant differences (p<0.05) in these metrics between different LLM archetypes, demonstrating that performance is not uniform across models and requires archetype-specific evaluation protocols. These quantitative measures allow for objective comparison and identification of areas requiring improvement in human-LLM collaborative systems.
Rigorous evaluation of Large Language Model (LLM) performance necessitates the implementation of both LLM evaluation techniques and scoping reviews. LLM evaluation involves direct assessment of model outputs against defined criteria, utilizing metrics such as accuracy, precision, recall, and F1-score, often performed through human annotation or automated scoring systems. Scoping reviews, a form of knowledge synthesis, systematically analyze existing literature to identify the breadth of evidence regarding LLM performance in specific applications, highlighting gaps in knowledge and areas requiring further investigation. Combining these methods provides a comprehensive understanding of an LLM’s capabilities and limitations, crucial for establishing reliable performance benchmarks and identifying potential failure modes before deployment in critical contexts.
Analysis of the ‘Judge’ archetype revealed a 49% agreement rate between Large Language Model (LLM) predictions and established reference standards, indicating a substantial level of misalignment. This metric, however, necessitates archetype-specific contextualization; a low agreement rate doesn’t inherently denote overall LLM failure, but rather highlights specific areas where the model diverges from expert judgment within that particular behavioral profile. Further investigation into the nature of these disagreements – identifying patterns in the types of errors made by the LLM for the ‘Judge’ archetype – is crucial for targeted improvements and the development of strategies to mitigate misalignment. Understanding why disagreements occur within each archetype is paramount for optimizing LLM performance and ensuring responsible deployment in critical applications.

Enhancing Collaborative Outcomes: Techniques for Optimizing LLM Performance
Prompt engineering and model fine-tuning are crucial for directing Large Language Models (LLMs) to consistently perform within defined behavioral boundaries, or archetypes. Prompt engineering involves crafting specific input instructions to elicit desired responses, influencing style, tone, and content. Model fine-tuning, conversely, modifies the LLM’s internal parameters through supervised learning on a dataset relevant to the target archetype and task. This process adapts the model’s existing knowledge to prioritize and generate outputs aligned with the desired characteristics. Both techniques address limitations of pre-trained LLMs, which may exhibit unpredictable behavior or lack specialized knowledge, and are often used in combination to achieve optimal performance and consistency in collaborative workflows.
Retrieval-augmented generation (RAG) enhances large language model (LLM) performance by integrating information retrieved from external knowledge sources during the generation process. Rather than relying solely on the parameters learned during pre-training, RAG systems first identify relevant documents or data fragments based on a given input query. This retrieved content is then provided to the LLM as context, allowing it to generate responses grounded in factual, up-to-date information. This approach demonstrably improves both the accuracy of generated text, reducing instances of hallucination, and its relevance to the user’s specific query, as the LLM can draw upon a broader and more targeted knowledge base than its internal parameters alone would allow.
By automating information retrieval and initial content drafting, techniques like prompt engineering and retrieval-augmented generation (RAG) demonstrably decrease the cognitive burden on human collaborators. This reduction in load stems from lessened requirements for memory recall, fact-checking, and initial content creation, allowing human team members to focus on higher-level tasks such as critical analysis, strategic decision-making, and creative problem-solving. Studies indicate that offloading these foundational elements to LLMs correlates with increased task completion rates, reduced error margins, and improved overall team efficiency in collaborative workflows.
Maximizing the efficacy of human-LLM collaboration requires identifying distinct interaction archetypes – such as LLMs functioning as assistants, collaborators, or critics – and then deliberately applying techniques like prompt engineering, fine-tuning, and retrieval-augmented generation to support that specific role. Successful implementation is contingent on aligning the chosen methodology with the desired archetype; for example, a knowledge-intensive archetype benefits significantly from RAG, while a creative archetype may prioritize fine-tuning for stylistic consistency. Failing to strategically match techniques to archetypes limits the LLM’s ability to effectively augment human capabilities and can result in suboptimal outcomes, hindering the full potential of the partnership.
The exploration of human-AI interaction archetypes reveals a crucial truth about complex systems. If a system survives on duct tape – a patchwork of ad-hoc solutions to bridge gaps in design – it’s probably overengineered. This mirrors the findings within the paper; a proliferation of roles assigned to LLMs, without a unifying architectural principle, leads to brittle and unpredictable decision-making. As Marvin Minsky noted, “The more you know, the more you realize how much you don’t know.” The 17 archetypes presented aren’t simply a taxonomy, but a framework for acknowledging the limits of current LLM capabilities and designing systems that gracefully handle uncertainty – recognizing that modularity without a holistic understanding of the system is an illusion of control. A well-defined role, understood within the broader context, fosters more robust and reliable human-AI collaboration.
Beyond Roles: The Architecture of Trust
The delineation of seventeen archetypes within human-AI decision-making, while a necessary step toward clarity, risks becoming another exercise in categorization – a taxonomy of behaviors rather than an understanding of underlying principles. The true challenge lies not merely in defining what an LLM does within a decision loop, but in grasping why certain roles emerge as more effective – or more easily abused – than others. Modifying a single archetype, altering the LLM’s assigned function, invariably triggers a cascade of adjustments in human strategy and trust. The system as a whole, not the isolated component, must be the focus of continued inquiry.
Future work should move beyond behavioral observation toward a more formal analysis of the information architecture supporting these archetypes. What are the constraints – computational, cognitive, or ethical – that shape the possible roles? How do different architectural choices amplify or mitigate inherent biases? A deeper understanding of these foundational elements is crucial to avoid designing systems that merely appear responsible, masking underlying vulnerabilities with clever role assignment.
Ultimately, the field must confront the uncomfortable truth that effective human-AI collaboration isn’t about optimizing a task, but about negotiating a relationship. The stability of that relationship, the enduring capacity for mutual understanding, will depend not on the elegance of any single archetype, but on the robustness of the entire system – its capacity to adapt, to learn, and to maintain a delicate balance between autonomy and control.
Original article: https://arxiv.org/pdf/2602.11924.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Gold Rate Forecast
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Invincible Creator on Why More Spin-offs Haven’t Happened Yet
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
2026-02-15 11:15