Author: Denis Avetisyan
New research explores the limits of human perception when interpreting AI-generated art, revealing a surprising challenge in discerning stylistic choices.

The study assesses human ability to infer prompts from AI-generated images, finding stronger accuracy in identifying subjects than in reconstructing stylistic modifiers, with implications for intellectual property protection.
The increasing commodification of AI-generated art through prompt marketplaces presents a paradox: while prompts are treated as intellectual property, their underlying content may be surprisingly recoverable. This research, ‘Prompt and Circumstances: Evaluating the Efficacy of Human Prompt Inference in AI-Generated Art’, investigates the extent to which humans and artificial intelligence can infer the original prompts used to create images, given only the resulting artwork. Our findings demonstrate that while core subjects can be reasonably inferred, accurately reconstructing stylistic details remains challenging, suggesting a degree of resilience for prompt-based intellectual property claims. However, the potential for increasingly sophisticated inference techniques raises the question of how effectively prompt ownership can be protected in the rapidly evolving landscape of AI-generated content.
The Illusion of Progress: A New Frontier for Digital Art
The landscape of digital art and visual content creation is undergoing a swift transformation due to the rapid evolution of text-to-image models. These systems, powered by artificial intelligence, now possess the capability to generate strikingly detailed and imaginative visuals from simple textual descriptions, unlocking unprecedented creative potential for artists, designers, and communicators. Recent advancements aren’t merely incremental; they represent a qualitative leap in image fidelity, stylistic control, and the ability to interpret nuanced prompts. This burgeoning technology democratizes visual content creation, allowing individuals without traditional artistic skills to realize their visions, and simultaneously provides established creatives with powerful new tools for exploration and iteration. The speed of innovation suggests that the boundaries of what’s visually possible are poised for continuous expansion, promising a future where imagination is the primary limitation – a seductive promise, if you ask me.
The creation of strikingly realistic images by models such as Midjourney V5.0 and Stable Diffusion XL hinges on a sophisticated process known as diffusion. Initially, these models are trained to gradually add noise to images, systematically destroying their structure until only random static remains. Remarkably, the models then learn to reverse this process – to ‘denoise’ – starting from random noise and iteratively refining it into a coherent image guided by a text prompt. This reverse diffusion is not a simple ‘undoing’ of the noise addition; it’s a learned process of predicting and removing noise at each step, effectively sculpting an image from digital chaos. The quality of the resulting image relies on the model’s ability to accurately estimate and subtract noise, a task demanding immense computational power and a deep understanding of image structure gleaned from massive datasets.
The remarkable ability of current text-to-image generative models stems from their training on datasets of unprecedented scale, most notably LAION-5B. This expansive collection, comprising 5.85 billion CLIP-filtered image-text pairs harvested from the internet, provides the statistical foundation for associating language with visual concepts. Essentially, the model learns to predict which images best correspond to given textual descriptions by identifying patterns within this massive dataset. The sheer volume of data allows these models to generalize beyond the specific examples seen during training, enabling them to generate novel images from previously unseen prompts. Without such a comprehensive dataset, the nuanced understanding of language and imagery required for high-quality image synthesis would be unattainable, highlighting LAION-5B as a critical enabler of this rapidly evolving technology.
The remarkable potential of text-to-image generative AI is inextricably linked to the art of prompt engineering. These models, while capable of astonishing creativity, are fundamentally interpreters of language; the precision and detail within a text prompt directly dictate the resulting image’s quality, composition, and aesthetic. Ambiguous or poorly constructed prompts often yield unpredictable or undesirable outputs, while carefully crafted prompts – specifying artistic style, lighting, subject detail, and even camera angles – unlock the full capabilities of the AI. Consequently, a growing field is emerging focused on mastering this ‘prompting’ skill, requiring not only linguistic finesse but also an understanding of how the AI interprets and translates language into visual representations. This emphasis on prompt engineering transforms the creative process, placing a new premium on the ability to communicate effectively with artificial intelligence and effectively guide its imaginative output.

Reverse Engineering Creativity: Decoding the Prompt
Prompt inference involves computationally determining the text prompt most likely used to generate a given image. This is achieved by analyzing the visual features present in the image and mapping those features to textual descriptions using models trained on image-text pairs. Essentially, it’s the inverse of the image generation process, where a text prompt is used to create an image; instead, an image is used to reconstruct the likely prompt. This reconstruction isn’t a perfect retrieval of the original prompt, but rather an approximation based on the model’s understanding of the relationship between visual content and language.
Inferring the prompt used to generate an image is a complex process necessitating specialized techniques for visual analysis. Current methods, such as the CLIP Interrogator, operate by extracting visual features from the input image and comparing them to a large database of text-image pairs. This comparison leverages the CLIP (Contrastive Language-Image Pre-training) model’s ability to measure the semantic similarity between images and text. The Interrogator then generates a series of descriptive phrases, ranked by their CLIP score – a measure of how well the text aligns with the image’s visual features – ultimately presenting the most probable prompt reconstruction. The process relies on identifying objects, scenes, and attributes present in the image and translating them into corresponding textual descriptions.
Accuracy in prompt inference is quantitatively assessed using metrics including CLIP Score, which measures the similarity between the inferred prompt and the image embedding; LPIPS (Learned Perceptual Image Patch Similarity), evaluating perceptual image similarity; and ImageHash, a perceptual hashing algorithm identifying near-duplicate images. Recent research indicates a partial success rate in subject identification, with ImageHash achieving approximately 53% hit rate when comparing inferred prompts to the original prompts used for image generation. However, these studies consistently demonstrate reduced accuracy when attempting to infer stylistic modifiers – elements defining artistic style, lighting, or composition – suggesting these attributes are less reliably reconstructed from visual data alone.
Accurate prompt inference enables several downstream applications. In image editing, reconstructed prompts can be used to refine or modify existing images via text-to-image models, allowing for targeted alterations based on the original creative intent. For content understanding, inferring the prompt provides a textual description of an image’s key elements, facilitating automated tagging, search, and categorization. Furthermore, the ability to reverse engineer the prompts used to generate specific images allows for analysis of creative workflows and potentially the identification of stylistic preferences or techniques employed by image creators, contributing to research in computational creativity and artistic style analysis.
![LPIPS distributions reveal that decreasing prompt specificity and subject variation from reference prompts leads to increasingly dissimilar generated images, as indicated by divergence in [latex]f-h[/latex].](https://arxiv.org/html/2601.17379v1/x8.png)
The Illusion of Control: Human-AI Synergy in Creative Work
Human-AI collaboration in prompt creation combines human conceptualization with the computational capabilities of artificial intelligence. Humans excel at high-level ideation, defining artistic direction, and establishing aesthetic goals. However, translating these concepts into effective instructions for image generation models can be challenging due to the complexity of available parameters. AI, specifically Large Language Models, can systematically explore this parameter space, iteratively refining and expanding upon initial human prompts to identify variations that more closely align with the desired outcome. This division of labor allows for a more efficient and comprehensive exploration of creative possibilities than either approach would permit independently, leading to outputs that better reflect the artist’s intent.
Large Language Models (LLMs), such as GPT-4, function as iterative prompt enhancers by accepting a base prompt as input and outputting a revised, more detailed version. This refinement process involves expanding upon ambiguous terms, adding specific artistic styles or technical details, and incorporating negative prompts to avoid unwanted elements. The LLM analyzes the initial prompt and generates additional clauses and parameters based on its training data, effectively translating a conceptual idea into a format readily understood by image generation models. This capability allows users to move beyond simple, high-level instructions and construct complex prompts with greater precision, ultimately leading to outputs more aligned with their intended creative vision. The resulting expanded prompts can include details regarding lighting, composition, camera angles, and specific aesthetic qualities, features often lacking in initial user inputs.
The integration of human artists with AI image generation tools enables a degree of creative control exceeding that of either working independently. Traditional digital art creation requires artists to manually adjust numerous parameters to achieve a desired visual outcome. Human-AI collaboration allows artists to articulate high-level creative goals through prompts, while the AI explores and implements variations within those parameters. This iterative process, involving prompt refinement and AI-generated iterations, facilitates a feedback loop where the artist guides the AI toward increasingly accurate representations of their vision. Consequently, artists can realize complex imagery with greater precision and efficiency, overcoming limitations imposed by technical skill or time constraints, and achieving results previously requiring significantly more effort or expertise.
The increasing availability of fine-tuned Large Diffusion Models (LDMs), such as Realistic Vision V5 and DreamShaper XL, demonstrates the practical impact of human-AI collaborative prompting. These models, built upon base LDMs, are optimized through datasets curated with prompts refined via human-AI synergy. Analysis of DreamShaper XL in controlled datasets indicates a slight positive correlation (r=0.15) between collaborative prompt refinement and inference success rates, suggesting that iteratively improved prompts yield more predictable and desired outputs from the LDM. While the correlation is modest, it provides quantifiable evidence supporting the benefit of integrating human creative direction with AI’s parameter exploration capabilities in the prompt engineering process.
The Commodification of Ideas: The Prompt Economy and Digital Art
A burgeoning digital marketplace is taking shape around the very instructions used to generate art with artificial intelligence. Platforms like PromptBase and PromptHero are pioneering this “prompt economy,” enabling creators to share, sell, and refine textual prompts – the specific keywords and phrases that guide AI image generators. This represents a novel approach to digital artistry, where the idea itself becomes a valuable commodity, distinct from the finished visual product. Individuals can now monetize their skill in crafting effective prompts, catering to users who may lack the expertise or time to develop them independently. The system fosters a dynamic exchange, with successful prompts often iterated upon and resold, creating a feedback loop that improves the quality and accessibility of AI-generated art for everyone.
The creation of digital art is undergoing a fundamental transformation, moving beyond the conventional exchange of finished pieces to encompass the trade of conceptual blueprints themselves. Previously, an artist’s value resided primarily in the execution of a vision; now, the very idea – the carefully crafted text prompt that guides an AI to generate an image – is becoming a marketable commodity. This shift empowers artists to monetize their creative thinking, offering a new revenue stream independent of traditional artistic skill or time investment. Consequently, consumers are no longer solely purchasing a finished artwork, but rather access to the generative seed from which unique visuals can blossom, fostering a more collaborative and iterative relationship between artist and audience. This innovative model reimagines artistic ownership and challenges established notions of what constitutes creative work in the age of artificial intelligence.
The burgeoning market for generative AI prompts introduces complex challenges to established notions of originality and intellectual property. While traditionally, artistic ownership resided in the execution – the finished painting, sculpture, or digital rendering – prompt marketplaces deal in the ideas that initiate creation. Determining the extent to which a carefully crafted text prompt constitutes an original work, and whether it can be legitimately owned, is proving difficult. If a prompt consistently generates similar outputs across different AI models, does that diminish its claim to originality? Furthermore, the question arises whether simply combining existing concepts within a prompt constitutes a novel creation worthy of protection, or if it falls under fair use. These uncertainties are prompting ongoing debate among legal scholars, artists, and technologists, highlighting the need for new frameworks to navigate this evolving landscape of digital creation.
The burgeoning prompt economy signals a potential shift in the landscape of digital artistry, offering expanded access to creative tools for a wider range of individuals. Historically, creating sophisticated digital art demanded significant technical skill and often expensive software; however, the ability to articulate a compelling prompt – a textual instruction for an AI – lowers the barrier to entry. This democratization allows aspiring artists, regardless of their technical proficiency, to realize their visions and contribute to the digital art space. Consequently, a new generation of creators is empowered, not necessarily through mastery of software, but through the art of conceptualization and effective communication with artificial intelligence, fostering innovation and potentially unlocking artistic talent previously constrained by traditional limitations.
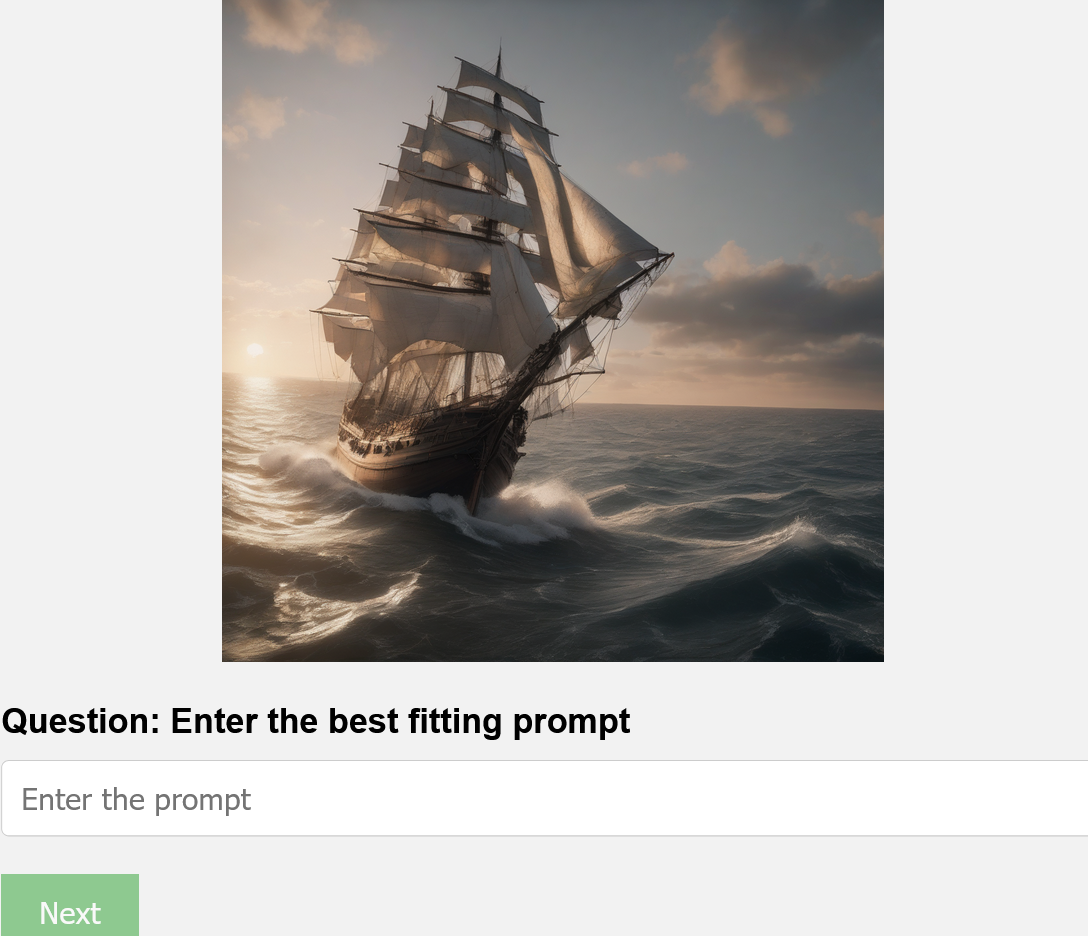
The pursuit of distilling human intent into machine-readable prompts feels… familiar. It’s a cycle. This research, highlighting the difficulty in reverse-engineering stylistic modifiers from AI-generated art, simply confirms what experience already dictates: nuance is lost in translation. As Claude Shannon observed, “The most important thing in communication is to get the message across, not to make it perfect.” The Kolmogorov-Smirnov test, in this case, isn’t proving a breakthrough; it’s merely quantifying the inevitable degradation of information. The system works-it generates-but reconstructing the artistry? Good luck. It’s another elegantly theorized framework destined to become tomorrow’s tech debt, because production-the AI, in this case-will always find a way to break the model.
What’s Next?
The demonstrated limitations in human inference of stylistic modifiers within AI-generated imagery are… predictable. It seems any attempt to distill creativity into quantifiable parameters will inevitably outpace human comprehension. The research offers a fleeting reassurance regarding prompt-based intellectual property, but this is merely a temporary stay of execution. Production will find a way to reverse engineer even the most subtle aesthetic signatures, and the legal battles will, of course, continue. The Kolmogorov-Smirnov test provides a neat metric, but metrics are just abstractions layered upon other abstractions.
Future work will likely focus on increasingly granular image similarity metrics, chasing a phantom precision. Perhaps the field will explore adversarial methods to intentionally obscure prompt influence, creating images that defy easy categorization. Or, more realistically, the focus will shift to automated prompt inference – algorithms attempting to deduce the stylistic intent of other algorithms. A beautifully recursive problem, and a new source of tech debt.
The illusion of control is always the most appealing. This study highlights that while humans can identify what an image depicts, understanding how it was depicted remains elusive. Documentation explaining these processes? A myth invented by managers. The real question isn’t whether humans can infer prompts, but whether anyone will care when the AI itself is doing the prompting.
Original article: https://arxiv.org/pdf/2601.17379.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
2026-01-28 00:34