Author: Denis Avetisyan
New research introduces methods for inferring the underlying motivations of strategic agents, moving beyond simply predicting their actions.
This paper presents two novel inverse game-theoretic learning frameworks, CE-ML and LBR-ML, for utility estimation and strategic modeling, demonstrating their effectiveness in both coordinated and uncoordinated environments like traffic simulation.
Inferring strategic reasoning from observed behavior remains a central challenge in multi-agent systems, yet bridging the gap between limited data and robust modeling is often elusive. This is addressed in ‘Inverse Learning in $2\times2$ Games: From Synthetic Interactions to Traffic Simulation’, which introduces two novel frameworks – Correlated Equilibrium Maximum-Likelihood (CE-ML) and Logit Best Response Maximum-Likelihood (LBR-ML) – for estimating agent utilities and predicting interactive dynamics. Results demonstrate a clear trade-off: CE-ML excels in scenarios demanding coordinated play, while LBR-ML proves more adaptable in uncoordinated settings. Can these complementary approaches be further integrated to unlock a more comprehensive understanding of complex strategic interactions in real-world applications?
Unveiling Strategy: Beyond the Game
The principles of strategic interaction extend far beyond traditional game theory, providing a powerful framework for understanding a surprisingly broad range of phenomena. Consider the dynamics of an economic market, where buyers and sellers constantly adjust their behaviors based on anticipated responses from others, or the seemingly chaotic flow of traffic, where each driver’s decisions – accelerate, brake, change lanes – are implicitly influenced by the actions of surrounding vehicles. These situations, and countless others – from biological competition and political maneuvering to even the subtle negotiations within a social group – can be effectively modeled as interactions between rational agents, each striving to maximize their own benefit given the anticipated strategies of others. This perspective allows researchers to move beyond simple observation and develop predictive models, offering insights into how these complex systems function and how interventions might achieve desired outcomes.
The Nash Equilibrium represents a cornerstone in game theory and the analysis of strategic interactions. It describes a remarkably stable state where each participant in a system has chosen a strategy such that, given the strategies of all others, no individual player can improve their outcome by unilaterally changing their own strategy. This doesn’t necessarily imply the best possible outcome for all involved – only that it’s a self-enforcing state. Imagine a scenario with multiple competing entities; a Nash Equilibrium arises when each entity has assessed the options and determined that deviating from its current course of action would yield no personal benefit, assuming others maintain theirs. \text{No player has incentive to deviate} This concept provides a powerful framework for understanding phenomena ranging from pricing strategies in economics to the evolution of animal behavior, offering insights into why certain outcomes persist even in the face of competition.
While Nash Equilibrium identifies stable states where individual players maximize their payoff given others’ strategies, Correlated Equilibrium demonstrates that sharing information – even in the form of a coordinating signal – can unlock demonstrably better outcomes for all involved. This concept moves beyond purely independent decision-making; it posits that if players can credibly commit to strategies contingent on a shared random signal, they can achieve profiles that are Pareto-optimal – meaning no player can improve their outcome without worsening another’s – which are often unattainable under Nash Equilibrium. Essentially, a trusted intermediary or a common understanding allows players to coordinate, effectively ruling out strategies that would be individually tempting but collectively detrimental. This isn’t about collusion, but rather a strategic alignment facilitated by shared knowledge, highlighting that efficiency in strategic interactions isn’t solely determined by individual rationality, but also by the available information and the capacity to act upon it collectively.
Deconstructing Intent: The Reverse Engineer’s Approach
Inverse Game-Theoretic Learning (IGTL) constitutes a set of techniques designed to deduce the underlying utility functions and strategic behaviors of agents solely from observed action sequences. Unlike traditional game theory which predicts behavior given known utilities, IGTL operates in reverse, estimating those utilities based on actions taken. This inference process relies on the assumption that agents, while not perfectly rational, behave strategically, seeking to maximize their inferred utilities given their beliefs about other agents. The toolkit provides algorithms for estimating these utilities and, consequently, predicting future actions, and is applicable across diverse domains including economics, political science, and artificial intelligence where agent modeling is critical.
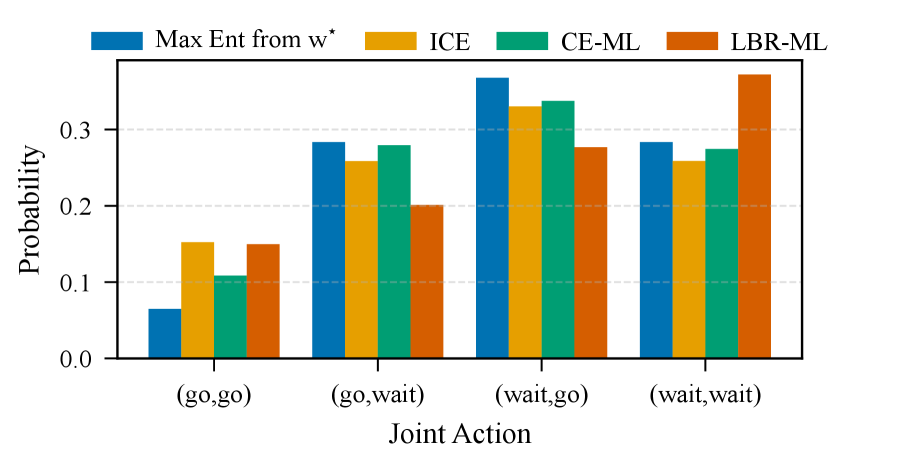
The methodology utilizes both Nash and Correlated Equilibrium concepts as foundational elements for inferring agent behavior. Nash Equilibrium assumes rational agents selecting strategies that maximize their utility given the strategies of others, while Correlated Equilibrium expands this by allowing for probabilistic strategy recommendations based on shared random signals. Our novel formulations, CE-ML and LBR-ML, build upon these equilibria to improve the accuracy of inference; specifically, CE-ML leverages the broader solution space offered by Correlated Equilibrium to better model complex interactions. Empirical results demonstrate that these formulations consistently outperform baseline methods in estimating agent utilities and strategies, as evidenced by reduced Root Mean Squared Error (RMSE) across multiple experimental setups.
Logit Best Response Dynamics (LBR) model agent learning as a stochastic process where agents iteratively select the best response to their beliefs about other agents’ strategies, with selection probabilities governed by a logit function; this provides a more realistic representation of bounded rationality and imperfect adaptation than assuming fully rational, instantaneous best responses. Across multiple experimental evaluations, the Correlated Equilibrium with Machine Learning (CE-ML) approach, utilizing LBR, consistently demonstrates lower Root Mean Squared Error (RMSE) values when estimating agent utility parameters compared to alternative methods. These lower RMSE values indicate that CE-ML, grounded in LBR dynamics, provides more accurate parameter estimation by better capturing the iterative and probabilistic nature of strategic learning in observed agent behavior.
Reality as a Testbed: Simulating the Strategic Dance of Traffic
SUMO (Simulation of Urban Mobility) is a microscopic, open-source traffic simulation package capable of modeling the behavior of individual vehicles and their interactions within a defined road network. Unlike macroscopic simulations that treat traffic as a continuous fluid, SUMO simulates each vehicle as a discrete entity with properties like position, speed, and acceleration. This allows for detailed analysis of phenomena such as lane changing, car following, and intersection management. The simulation environment supports a variety of road types, traffic signals, and vehicle types, and can ingest real-world map data via OpenStreetMap. Furthermore, SUMO facilitates the modeling of diverse driver behaviors and allows for the implementation of intelligent vehicle technologies, making it a valuable tool for traffic engineers, researchers, and autonomous vehicle developers.
Vehicle interactions within the SUMO traffic simulation can be formalized as 2×2 Normal-Form Games, enabling the quantitative analysis of driver decision-making. In this framework, each vehicle is modeled as a player facing a strategic choice between two actions – for example, maintaining its current lane or initiating a lane change, or accelerating or decelerating. The outcome, represented as payoffs, is determined by the simultaneous actions of interacting vehicles. This game-theoretic representation allows for the application of solution concepts, such as Nash equilibria, to predict and understand emergent traffic patterns. By defining these interactions as games, researchers can move beyond descriptive modeling to analyze the strategic motivations underlying observed traffic behavior.
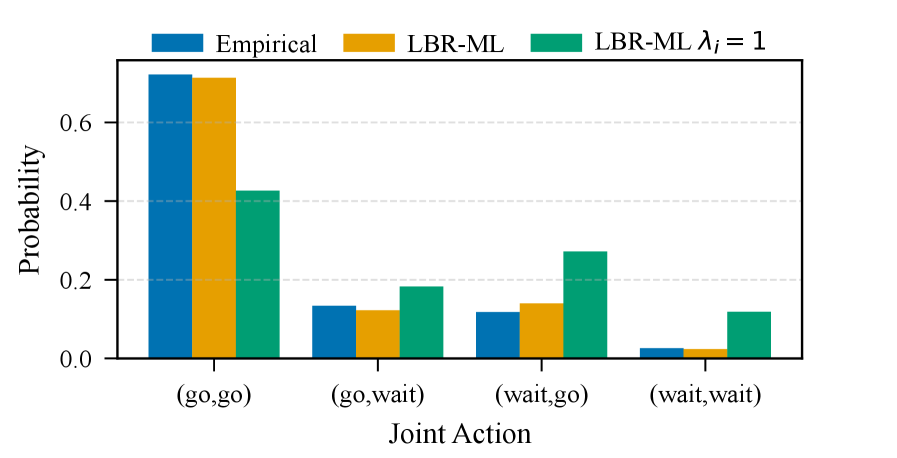
Inverse Game-Theoretic Learning, when applied to traffic data generated by the SUMO simulation, enables the inference of driver preferences and strategic behaviors. The LBR-ML algorithm, utilizing this approach, achieves 72.6% accuracy in predicting joint actions of vehicles in uncoordinated traffic situations, as demonstrated in Experiment E4. This performance indicates the robustness of the method in modeling realistic, non-cooperative driving scenarios. Furthermore, the derived rationality parameters, λ_1 and λ_2, consistently range from 1.0 to 3.0, suggesting that the modeled drivers exhibit adaptive behavior and do not consistently prioritize purely self-interested actions even in the absence of explicit coordination mechanisms.
The pursuit of realistic agent modeling, as demonstrated by the CE-ML and LBR-ML frameworks, inherently involves a process of controlled disruption. This work doesn’t simply assume rational behavior; it actively reverse-engineers it from observed interactions, much like dismantling a clock to understand its mechanisms. As Marvin Minsky once stated, “You can’t always get what you want, but if you try sometimes you find you get what you need.” This sentiment mirrors the approach taken here: the frameworks aren’t seeking perfect replication of human intent, but rather a functional understanding of strategic behavior that can be useful for applications like traffic simulation. The ability of LBR-ML to function effectively in uncoordinated scenarios exemplifies this pragmatic approach – accepting imperfection to achieve a robust, working model.
What’s Next?
The demonstrated efficacy of CE-ML and LBR-ML in bridging the gap between observed behavior and underlying utility functions is, predictably, not an end. The frameworks operate, after all, under assumptions-logit response, specific game structures-and any sufficiently complex system will inevitably reveal the limits of these simplifications. The true challenge lies not in achieving behavioral realism within a defined game, but in identifying the game itself. Future work must address the inherent difficulty of discerning whether observed interactions represent strategic equilibrium, chaotic exploration, or simply incompetence.
Current approaches treat utility estimation as a largely passive exercise – inferring preferences from actions. A more ambitious, and likely more fruitful, direction involves active learning – designing interventions to probe agent preferences directly. This introduces a control problem of its own, naturally, but acknowledges that behavior isn’t merely revealed, it’s often constructed.
Ultimately, the best hack is understanding why it worked. Every patch – every refinement to the estimation algorithms, every broadened assumption – is a philosophical confession of imperfection. The goal isn’t to perfectly model agents, but to build systems robust enough to function even when the model is wrong. The pursuit of behavioral realism, therefore, is less about mirroring reality and more about anticipating its inevitable deviations.
Original article: https://arxiv.org/pdf/2601.10367.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- How to find the Roaming Oak Tree in Heartopia
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- M7 Pass Event Guide: All you need to know
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-18 01:22