Author: Denis Avetisyan
Researchers are leveraging the power of AI not to produce research, but to rigorously verify existing claims and uncover hidden assumptions in systematic reviews.
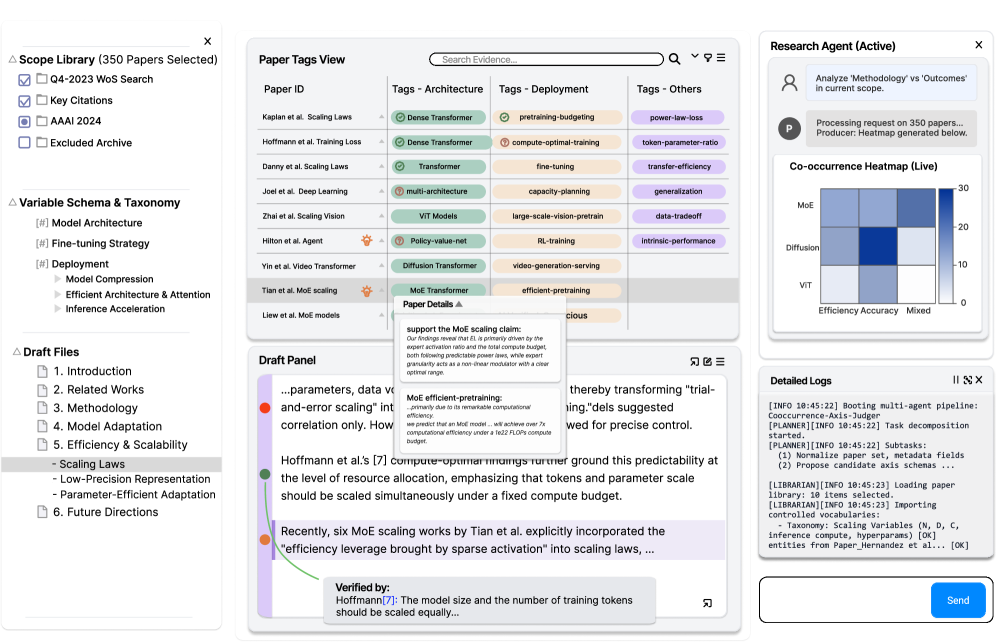
This paper introduces Research IDE, a tool that reframes meta-analysis as code debugging, enabling human-AI collaboration through ‘Hypothesis Breakpoints’ and abductive reasoning.
Rigorous meta-analysis demands sophisticated abductive reasoning, yet current tools often treat researchers as passive recipients of automated insights. This paper, ‘Probing the Future of Meta-Analysis: Eliciting Design Principles via an Agentic Research IDE’, introduces Research IDE, a novel authoring environment that reframes research as code debugging, embedding an agentic backend to support in-situ hypothesis verification. Our field deployment reveals that this “Research as Code” approach-facilitated by “hypothesis breakpoints”-empowers researchers to actively leverage prior knowledge and maintain intellectual ownership. Could such tools redefine human-AI collaboration, fostering a future where computational scale amplifies, rather than supplants, critical scientific thought?
The Evolving Landscape of Knowledge Synthesis
The established process of systematic review, while foundational to evidence-based practice, presents significant limitations in an era of exponential research growth. A manual approach to sifting through countless studies is inherently time-consuming, often requiring months or even years to complete a single review. More critically, the subjective judgment of researchers-in study selection, data extraction, and risk of bias assessment-introduces the potential for human bias, subtly shaping the conclusions reached. This bias isn’t necessarily intentional, but rather a consequence of interpreting complex information, potentially overlooking relevant evidence, or prioritizing findings aligned with pre-existing beliefs. Consequently, traditional systematic reviews may not fully capture the breadth and nuance of available knowledge, hindering a truly comprehensive understanding of a given topic and potentially leading to incomplete or skewed syntheses.
The exponential growth of scientific literature presents a significant challenge to researchers attempting comprehensive knowledge synthesis. While the intent is to build upon existing findings, the sheer volume of publications routinely overwhelms traditional review methods, making it increasingly difficult to identify all relevant evidence. This isn’t simply a matter of time; the deluge of data increases the risk of overlooking crucial studies, introducing bias through selective inclusion, and ultimately, drawing conclusions that lack the robustness needed to confidently inform practice or future research. Consequently, even with diligent effort, systematic reviews may offer an incomplete, and potentially skewed, representation of the current state of knowledge, hindering genuine scientific progress and innovation.
Existing methods of literature review often fail to delve beneath readily apparent connections, instead prioritizing broad summaries over detailed investigation. This limitation stems from a reliance on keyword searches and manual screening, which inadvertently favor easily quantifiable data and neglect subtle, complex interactions between research findings. Consequently, valuable insights – such as conditional effects, contextual nuances, and previously unrecognized patterns – remain hidden within the vast body of scientific literature. The inability to move beyond surface-level analysis not only restricts a complete understanding of existing knowledge but also hampers the generation of novel hypotheses and the identification of promising avenues for future research, ultimately slowing the pace of scientific discovery.
Research as Code: A System for Iterative Discovery
The Research IDE implements a ‘Research as Code’ approach by framing the process of hypothesis verification as analogous to software debugging. This involves formulating research questions as testable claims and employing iterative refinement based on evidence. Similar to debugging, researchers can step through their reasoning, identify points of failure in their logic, and revise their hypotheses based on observed discrepancies. This paradigm shift enables a more systematic and reproducible research workflow, facilitating the identification and correction of errors in reasoning, and promoting greater transparency in the research process.
The Research IDE’s functionality is enabled by a Multi-Agent Backend comprised of independent software agents designed to automate complex cognitive tasks. These agents collaboratively perform functions including literature search, claim extraction, evidence evaluation, and logical inference, synthesizing information to support or refute research hypotheses. The system architecture allows for modularity and scalability, enabling the integration of new reasoning techniques and data sources without disrupting core functionality. Agent orchestration is managed through a central control mechanism which dynamically assigns tasks and resolves conflicts, ensuring coherent and efficient evidence synthesis.
Interactive Hypothesis Breakpoints, a core feature of the Research IDE, enable researchers to pause automated reasoning at specific points within a hypothesis and directly assess the supporting evidence derived from relevant literature. During a one-week longitudinal deployment involving eight participants, the system recorded a total of 105 breakpoint activations. This indicates frequent researcher intervention and verification of claims as the automated system progressed, suggesting a high degree of user engagement with the evidence synthesis process and facilitating iterative refinement of hypotheses based on direct literature review.
The Research IDE is designed to maintain researcher agency and cognitive control throughout the research process by avoiding automated conclusion generation. The system functions as a tool for augmenting, not replacing, researcher judgment; all analytical steps and evidence syntheses are initiated and directed by the user. This approach ensures intellectual ownership of the research findings, as the researcher retains full control over the interpretation and validation of evidence. The interface facilitates direct manipulation of research parameters and allows for granular control over the reasoning process, preventing the system from drawing conclusions independently of researcher oversight.
Deconstructing Complexity: Specialized Agents in Action
The Planner Agent functions as an initial decomposition module within the automated reasoning system. Given a user’s complex claim or research question, this agent breaks it down into a series of discrete, answerable sub-questions. This decomposition process is critical for streamlining research, as it allows subsequent agents – specifically the Librarian and Reasoner – to focus on retrieving and analyzing evidence relevant to these individual components. By dividing the overarching claim, the system avoids attempting a holistic search which is often inefficient and inaccurate, and instead enables targeted information retrieval and analysis, ultimately improving the speed and quality of the research process. During system deployment, the Planner Agent contributed to the processing of evidence from a corpus of 548 papers.
The Librarian Agent employs Retrieval-Augmented Generation (RAG) as its primary method for evidence retrieval. This process involves initially querying a vector database containing embedded representations of numerous research papers. The database returns the most semantically similar documents to the user’s query. These retrieved documents are then concatenated with the original query and fed into a large language model. This combined input allows the language model to generate a more informed and contextually relevant response, effectively augmenting its internal knowledge with external evidence. This approach facilitates efficient information gathering and reduces reliance on the language model’s pre-existing knowledge base.
The Reasoner Agent facilitates cross-document analysis by systematically comparing information presented in multiple sources. This process goes beyond simple information retrieval; the agent actively identifies points of agreement – consensus – and disagreement – dissensus – between documents. By evaluating evidence from diverse perspectives, the agent determines the degree to which claims are supported or contradicted across the corpus of analyzed materials. This comparative analysis is crucial for establishing the robustness of findings and highlighting areas where further investigation is warranted, ultimately contributing to a more nuanced and reliable understanding of the subject matter.
The Producer Agent serves as the final component in the automated reasoning pipeline, responsible for consolidating information gathered by the other agents into a readily understandable format. During a deployment phase, researchers utilized the system – incorporating the Planner, Librarian, and Reasoner agents alongside the Producer – to categorize and label a corpus of 548 academic papers. This labeling process served as a validation of the system’s ability to synthesize complex information and present it in a manner conducive to human review and analysis, effectively demonstrating the Producer Agent’s role in translating automated reasoning into actionable insights.
The Trajectory of Knowledge Synthesis: Automation and Design
A robust taxonomy serves as the foundational architecture for the multi-agent backend, enabling efficient organization of vast quantities of research literature. This structured framework moves beyond simple keyword searches, instead categorizing information based on nuanced relationships and concepts. By defining a hierarchical classification system, the backend can intelligently route information to the appropriate agent for analysis, synthesis, or validation. This not only accelerates the research process but also facilitates the discovery of previously unseen connections within the literature, fostering a more comprehensive understanding of complex topics. The taxonomy’s design directly impacts the system’s ability to perform effective knowledge synthesis and automate tasks requiring conceptual understanding, ensuring that the multi-agent system operates with precision and relevance.
Functional automation represents a significant leap in research efficiency by relieving scientists of tedious, yet crucial, preparatory work. This involves automating tasks such as consistent formatting of citations, generating hyperlinks between related concepts, and organizing digital libraries. By handling these traditionally manual processes, researchers can dedicate more cognitive resources to analysis, interpretation, and the formulation of novel hypotheses. The implementation of such systems isn’t about replacing human intellect, but rather augmenting it – freeing up valuable time and minimizing the potential for errors inherent in repetitive tasks, ultimately accelerating the pace of discovery and enabling more comprehensive investigations.
Epistemic automation represents a significant leap beyond simple data processing, enabling systems to actively generate new knowledge from existing literature. This isn’t merely about identifying relationships; it involves automating the processes of logical inference, hypothesis formation, and even theory building. By employing computational models of reasoning, these systems can synthesize information, draw conclusions, and propose novel insights that might otherwise remain hidden within the vast expanse of research. This capability moves beyond summarizing what is known to actively contributing to the expansion of knowledge itself, effectively transforming research tools into collaborative intellectual partners. Studies indicate that researchers find this level of automation acceptable when accuracy falls within the 70-80% range, allowing for swift validation and refinement of AI-generated conclusions.
The convergence of automated knowledge synthesis with a Research through Design methodology dramatically accelerates the pace of inquiry, affording researchers the ability to tackle intricate subjects with enhanced efficiency and precision. Studies indicate that an acceptable accuracy range of 70-80% for artificial intelligence components facilitates a productive cycle of rapid prototyping and validation; this threshold allows researchers to confidently leverage AI-driven insights without being hampered by the need for absolute perfection. This iterative process – building, testing, and refining – not only speeds up discovery but also fosters a deeper understanding of the underlying complexities, ultimately empowering more robust and nuanced conclusions.
The Research IDE, as detailed in the paper, posits a shift in how systematic reviews are conducted – framing them not as information retrieval, but as a process of claim verification akin to code debugging. This echoes Brian Kernighan’s observation that “every abstraction carries the weight of the past.” The tool’s emphasis on Hypothesis Breakpoints and active researcher engagement directly addresses the potential for unchecked assumptions and opaque reasoning within complex systems. Just as a programmer must trace the execution of code to understand its behavior, researchers utilizing the IDE maintain intellectual ownership by rigorously testing the foundations of their meta-analyses, ensuring that any ‘abstraction’ – or synthesized conclusion – is built upon a solid, verifiable base. The system aims to age gracefully, preserving resilience through continuous verification rather than passive acceptance of generated results.
What’s Next?
The introduction of Research IDE, framed as a debugging environment for knowledge, highlights an inevitable truth: any improvement ages faster than expected. The initial elegance of a novel methodology invariably decays as edge cases accumulate and unforeseen interactions emerge. This is not a failure of design, but a fundamental property of complex systems. The challenge, then, isn’t to build perpetually robust tools, but to create mechanisms for gracefully accommodating decay-for identifying, isolating, and, if necessary, surgically removing flawed components.
The emphasis on ‘hypothesis breakpoints’ and abductive reasoning signals a critical shift. The field has long been enamored with predictive power; with extracting patterns from existing data. But prediction, while useful, is ultimately static. True progress demands active interrogation-the deliberate introduction of falsifying conditions. The future of meta-analysis will not be about finding what is, but about systematically dismantling what isn’t – a process inherently iterative and, therefore, resistant to complete automation.
Rollback is a journey back along the arrow of time, and the inherent limitations of reconstructing intellectual provenance will become increasingly apparent. The tool merely assists; it cannot be the scientist. The true measure of success won’t be the speed of synthesis, but the fidelity with which the process of intellectual discovery is preserved-even as the underlying knowledge base inevitably erodes.
Original article: https://arxiv.org/pdf/2601.18239.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
2026-01-27 12:34